This report serves to describe the mutational landscape and properties of a given individual set, as well as rank genes and genesets according to mutational significance. MutSig vS2N was used to generate the results found in this report.
-
Working with individual set: STAD
The input for this pipeline is a set of individuals with the following files associated for each:
-
An annotated .maf file describing the mutations called for the respective individual, and their properties.
-
A .wig file that contains information about the coverage of the sample.
-
MAF used for this analysis:STAD.final_analysis_set.maf
-
Significantly mutated genes (q ≤ 0.1): 14
Column Descriptions:
-
N = number of sequenced bases in this gene across the individual set
-
nnon = number of (nonsilent) mutations in this gene across the individual set
-
nnull = number of (nonsilent) null mutations in this gene across the individual set
-
nflank = number of noncoding mutations from this gene's flanking region, across the individual set
-
nsil = number of silent mutations in this gene across the individual set
-
p = p-value (overall)
-
q = q-value, False Discovery Rate (Benjamini-Hochberg procedure)
Table 1. Get Full Table A Ranked List of Significantly Mutated Genes. Number of significant genes found: 14. Number of genes displayed: 35. Click on a gene name to display its stick figure depicting the distribution of mutations and mutation types across the chosen gene (this feature may not be available for all significant genes).
| gene | N | nflank | nsil | nnon | nnull | p | q |
|---|---|---|---|---|---|---|---|
| TP53 | 16758 | 4 | 2 | 68 | 22 | 1.5e-62 | 2.9e-58 |
| KRAS | 13760 | 4 | 0 | 17 | 0 | 1e-52 | 9.6e-49 |
| CBWD1 | 15184 | 4 | 0 | 18 | 16 | 1.5e-45 | 9.7e-42 |
| RPL22 | 6650 | 1 | 0 | 10 | 10 | 5.5e-38 | 2.6e-34 |
| ARID1A | 77406 | 6 | 2 | 30 | 20 | 1.4e-18 | 5.4e-15 |
| RNF43 | 26672 | 4 | 2 | 16 | 11 | 1.7e-13 | 5.4e-10 |
| ACVR2A | 25259 | 7 | 0 | 18 | 14 | 9e-13 | 2.4e-09 |
| PIK3CA | 56115 | 14 | 3 | 33 | 1 | 1.8e-10 | 4.2e-07 |
| PHF2 | 37894 | 10 | 4 | 14 | 10 | 1.6e-08 | 0.000033 |
| PGM5 | 20831 | 8 | 0 | 21 | 2 | 1.1e-07 | 0.00021 |
| UPF3A | 16021 | 6 | 1 | 7 | 6 | 2.9e-07 | 0.00049 |
| HLA-B | 12707 | 9 | 0 | 13 | 7 | 1.3e-06 | 0.0021 |
| MLL2 | 164919 | 6 | 8 | 34 | 12 | 8.9e-06 | 0.013 |
| MLL4 | 65258 | 4 | 3 | 25 | 9 | 0.000063 | 0.084 |
| CRYGC | 7980 | 0 | 0 | 6 | 0 | 0.0001 | 0.13 |
| RHOA | 12768 | 8 | 0 | 8 | 0 | 0.00086 | 1 |
| FAM9A | 11693 | 1 | 0 | 7 | 5 | 0.00097 | 1 |
| ERBB3 | 58659 | 6 | 3 | 21 | 0 | 0.0014 | 1 |
| SPERT | 14159 | 1 | 3 | 8 | 2 | 0.0016 | 1 |
| HLA-A | 14303 | 1 | 1 | 9 | 2 | 0.0024 | 1 |
| SMAD2 | 21934 | 8 | 0 | 8 | 5 | 0.0024 | 1 |
| OR8H3 | 16819 | 0 | 1 | 10 | 0 | 0.0025 | 1 |
| TPTE | 30651 | 24 | 3 | 17 | 1 | 0.0028 | 1 |
| NCOA2 | 63923 | 15 | 2 | 12 | 1 | 0.003 | 1 |
| CDC5L | 37772 | 7 | 0 | 10 | 0 | 0.0031 | 1 |
| HNF1A | 22682 | 3 | 1 | 6 | 5 | 0.0032 | 1 |
| BCOR | 65320 | 11 | 2 | 14 | 8 | 0.0036 | 1 |
| DOCK3 | 87088 | 28 | 6 | 26 | 10 | 0.0037 | 1 |
| IRF2 | 17229 | 3 | 1 | 11 | 3 | 0.0038 | 1 |
| TLR4 | 43092 | 0 | 2 | 13 | 0 | 0.004 | 1 |
| AKAP7 | 19878 | 10 | 0 | 6 | 5 | 0.0042 | 1 |
| MAP2K7 | 14226 | 4 | 0 | 13 | 2 | 0.0043 | 1 |
| FSHR | 36309 | 17 | 3 | 17 | 1 | 0.0045 | 1 |
| CAMTA2 | 50507 | 0 | 2 | 11 | 6 | 0.0048 | 1 |
| HIST1H1B | 9044 | 0 | 3 | 9 | 2 | 0.0049 | 1 |
Figure S1. This figure depicts the distribution of mutations and mutation types across the TP53 significant gene.
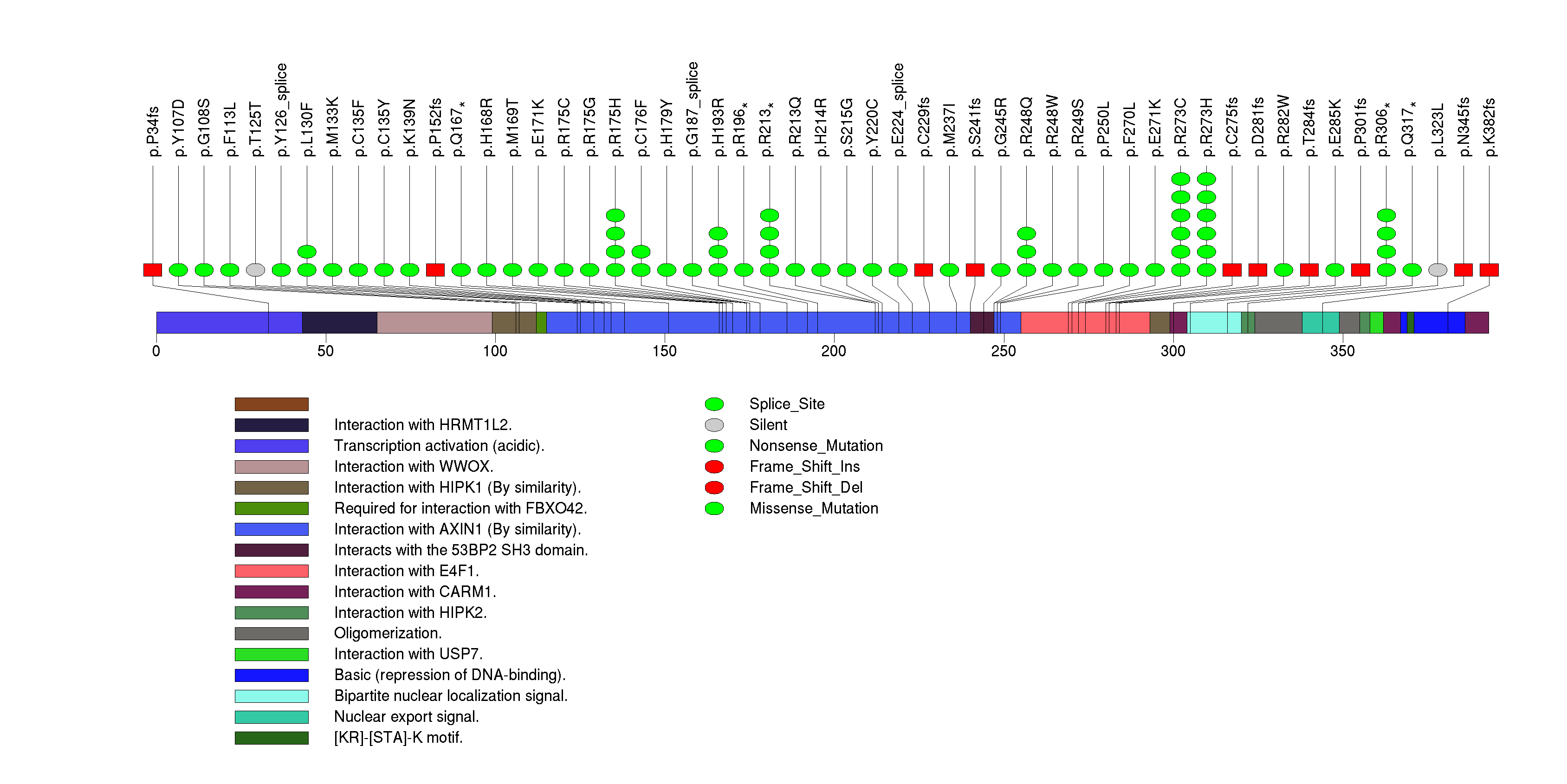
Figure S2. This figure depicts the distribution of mutations and mutation types across the KRAS significant gene.
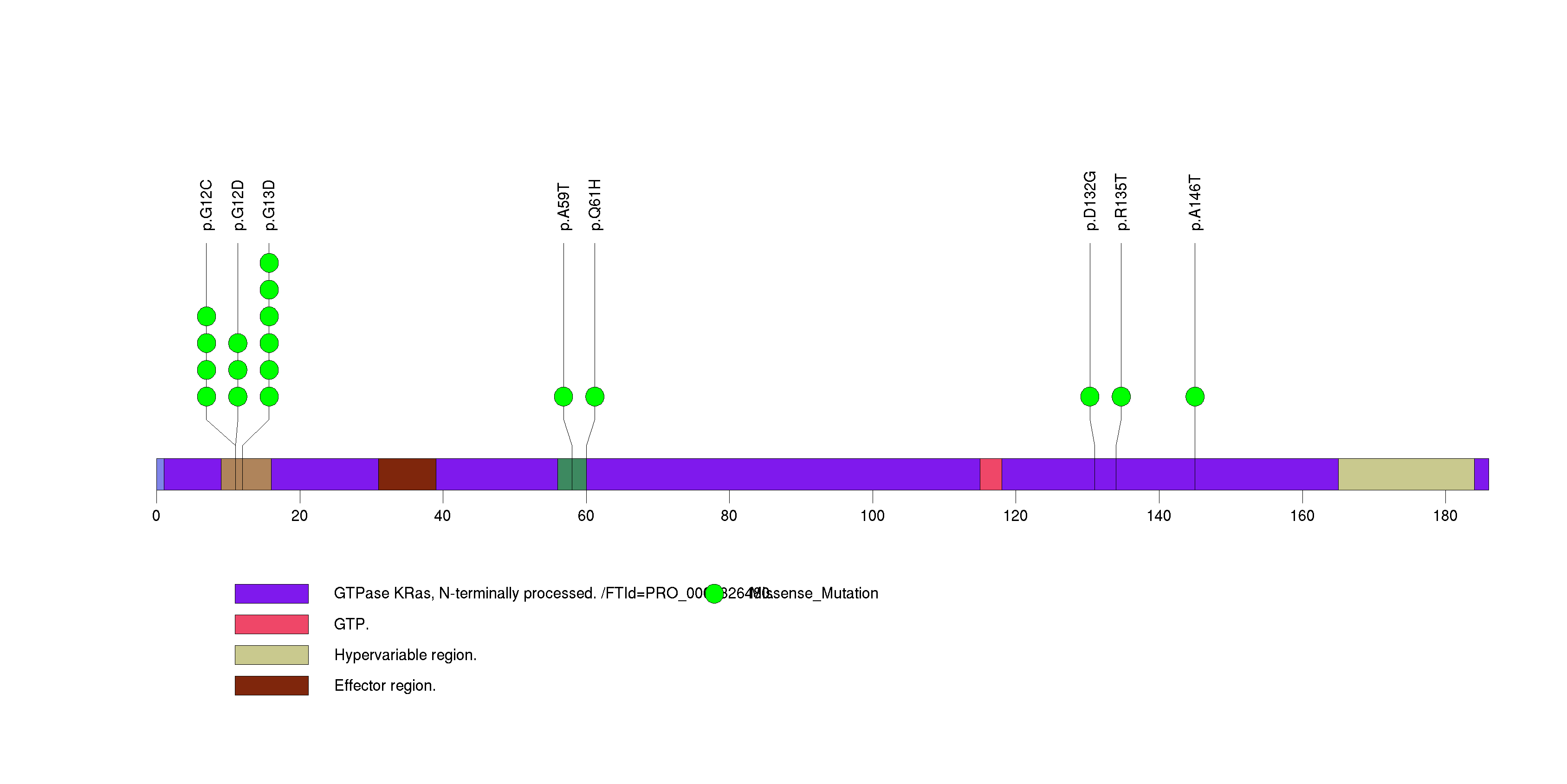
Figure S3. This figure depicts the distribution of mutations and mutation types across the RPL22 significant gene.
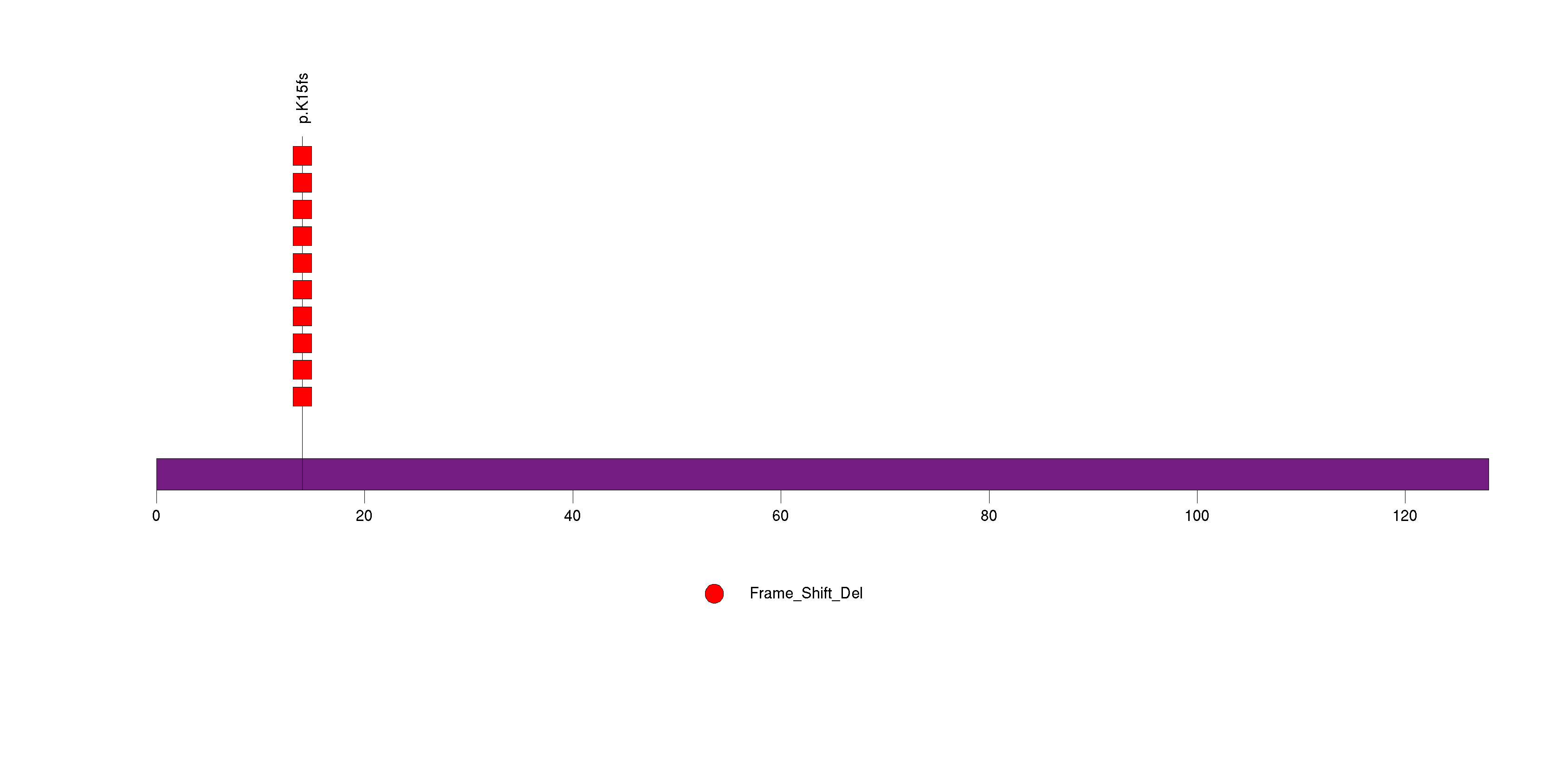
Figure S4. This figure depicts the distribution of mutations and mutation types across the ARID1A significant gene.
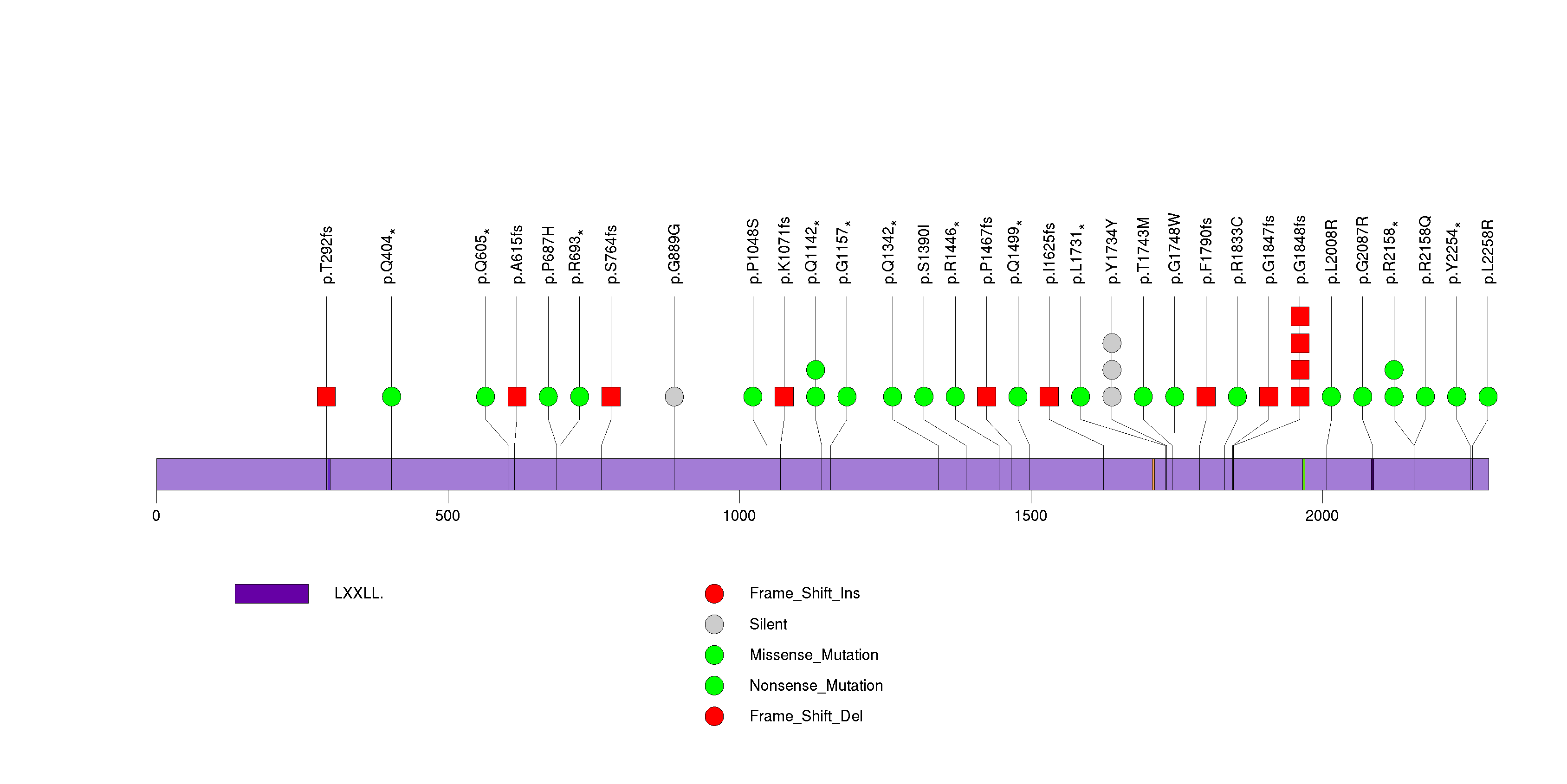
Figure S5. This figure depicts the distribution of mutations and mutation types across the RNF43 significant gene.
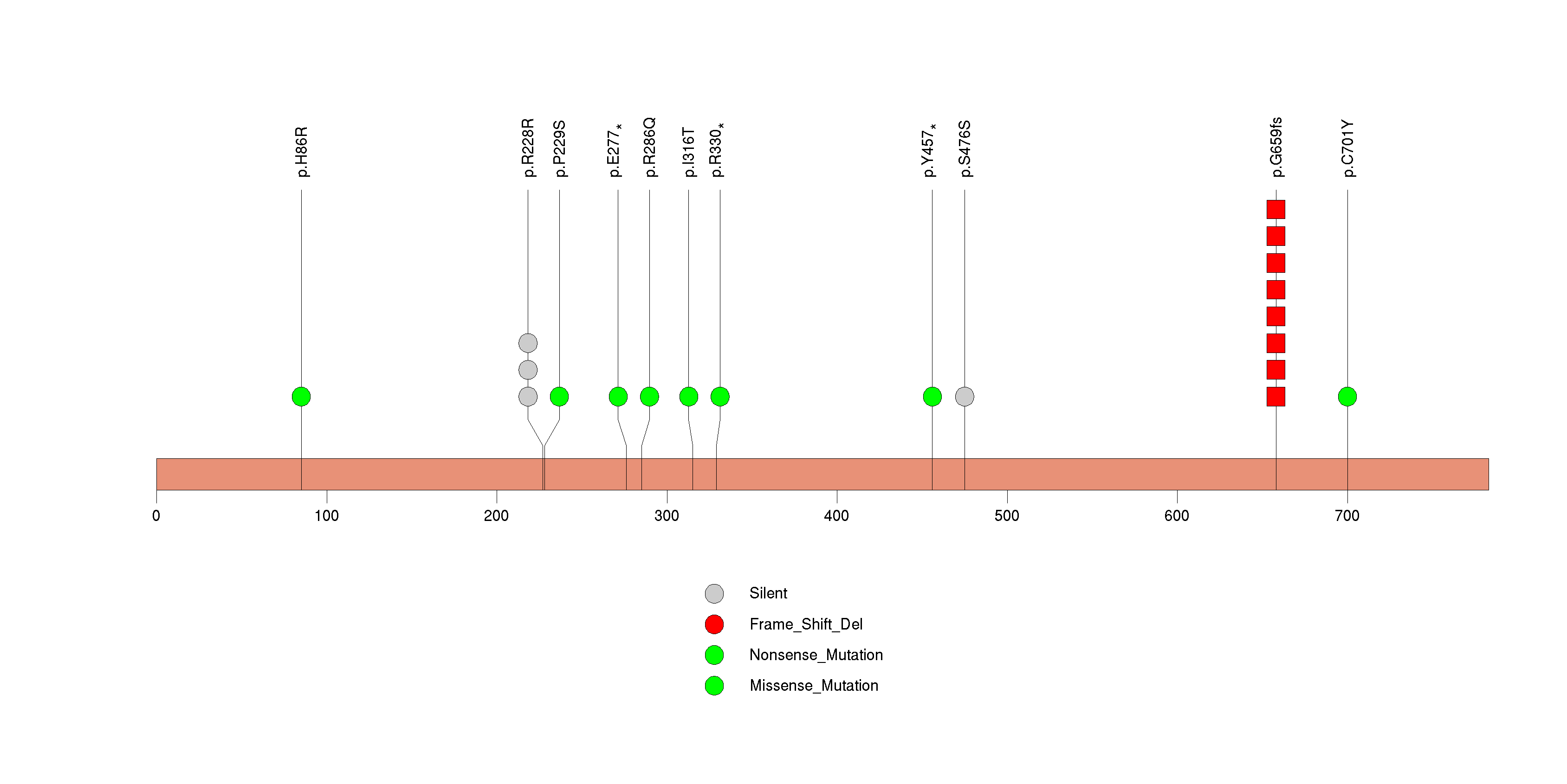
Figure S6. This figure depicts the distribution of mutations and mutation types across the ACVR2A significant gene.
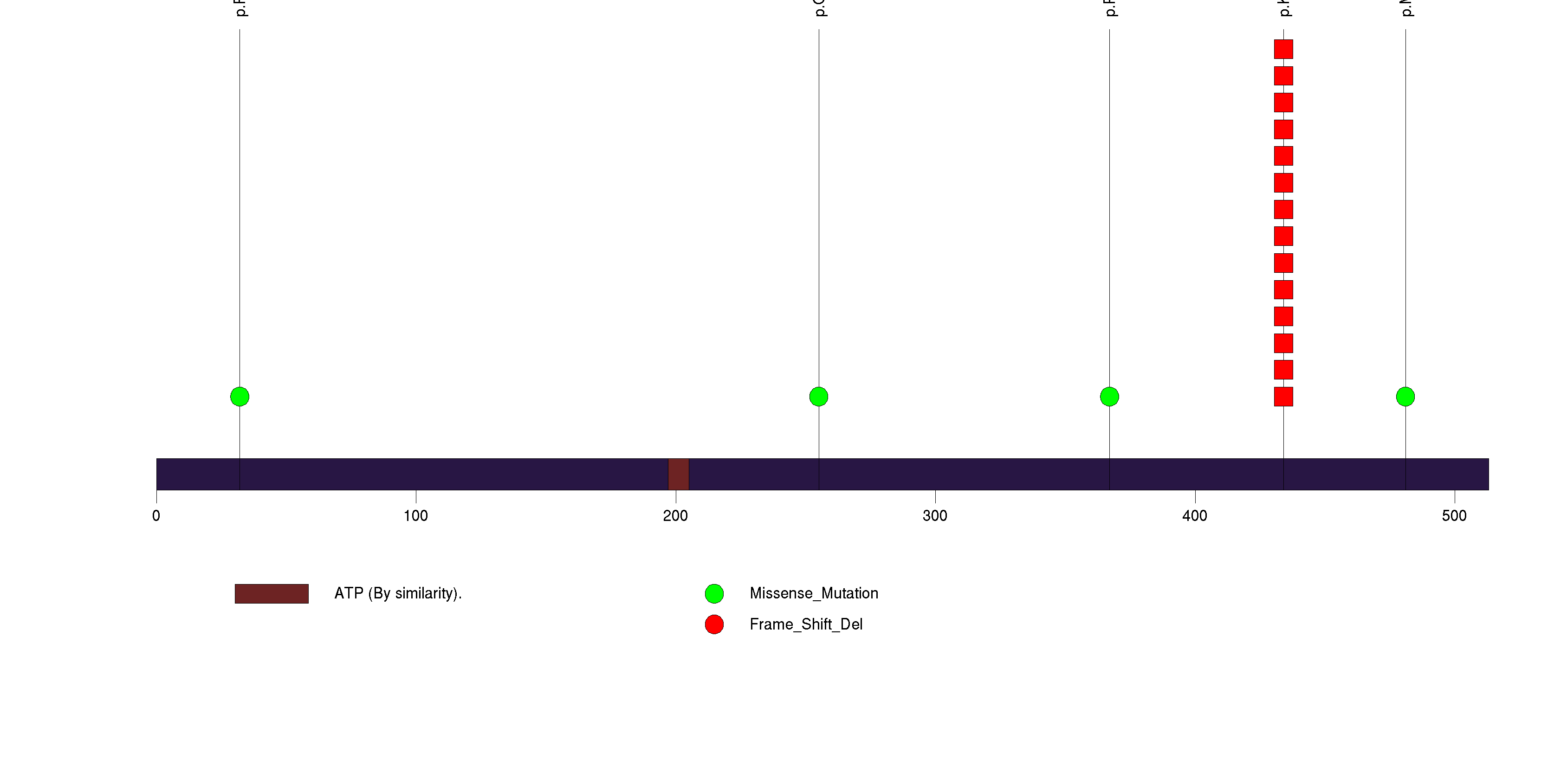
Figure S7. This figure depicts the distribution of mutations and mutation types across the PIK3CA significant gene.
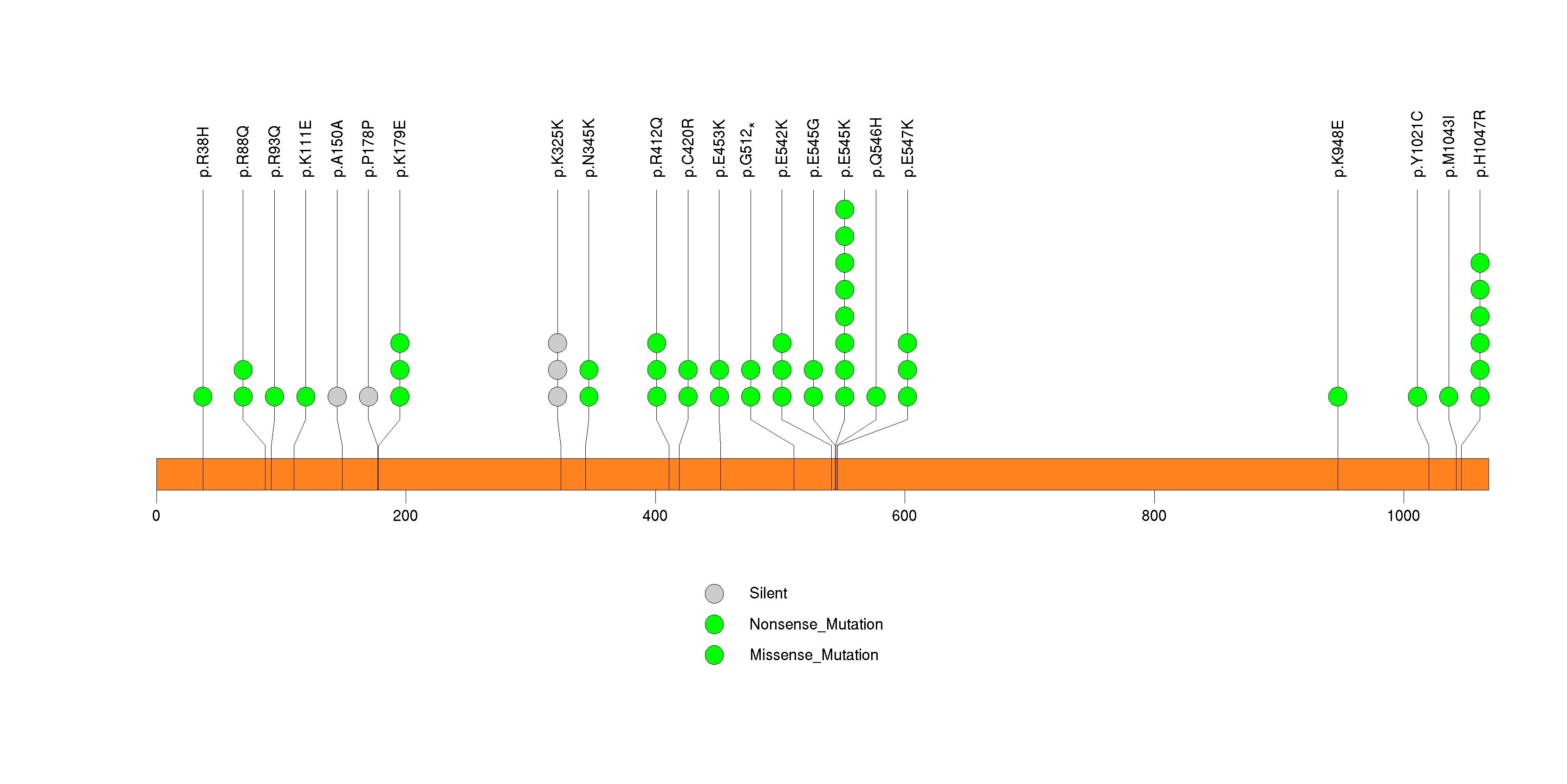
Figure S8. This figure depicts the distribution of mutations and mutation types across the PHF2 significant gene.
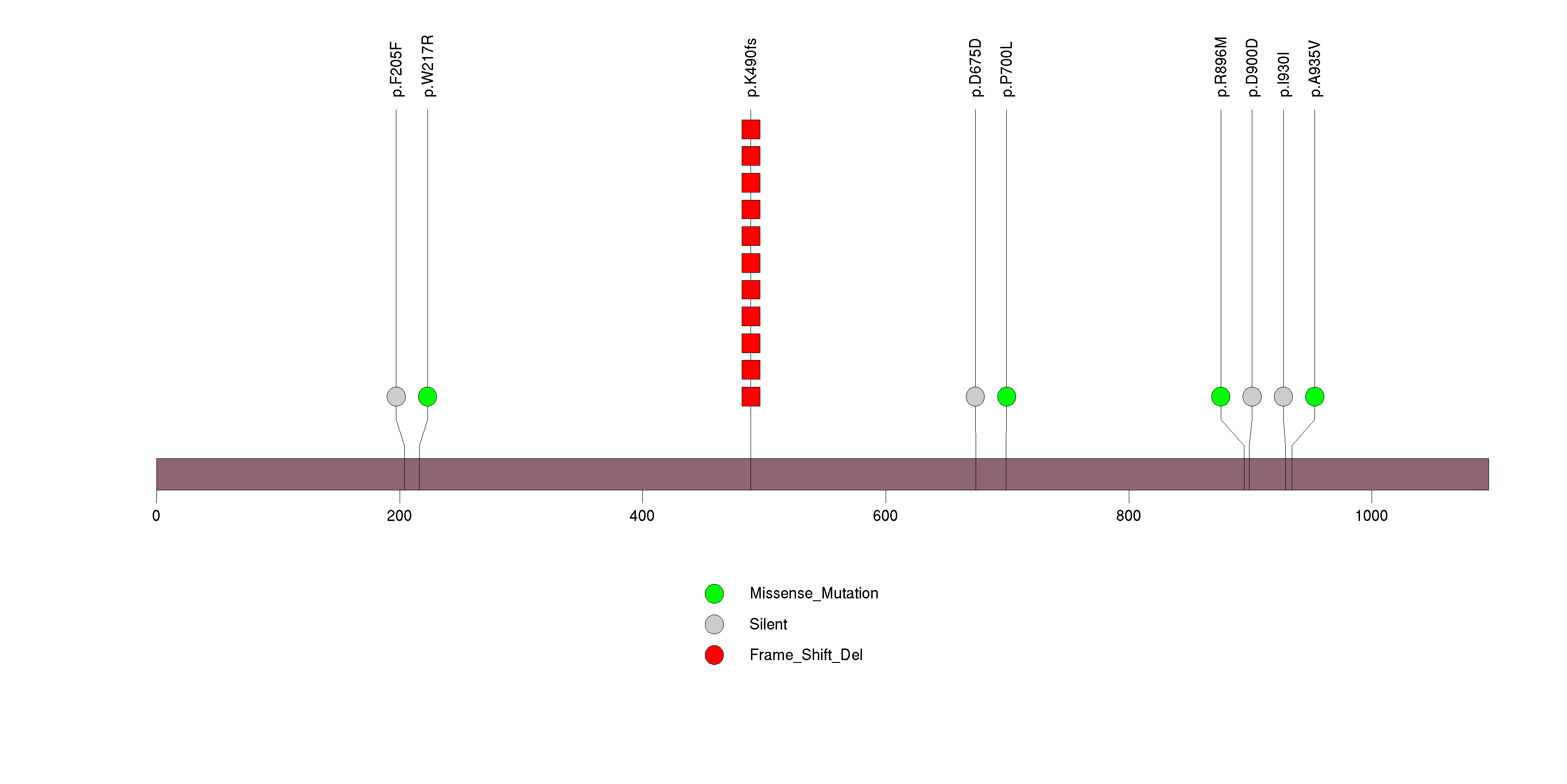
Figure S9. This figure depicts the distribution of mutations and mutation types across the PGM5 significant gene.
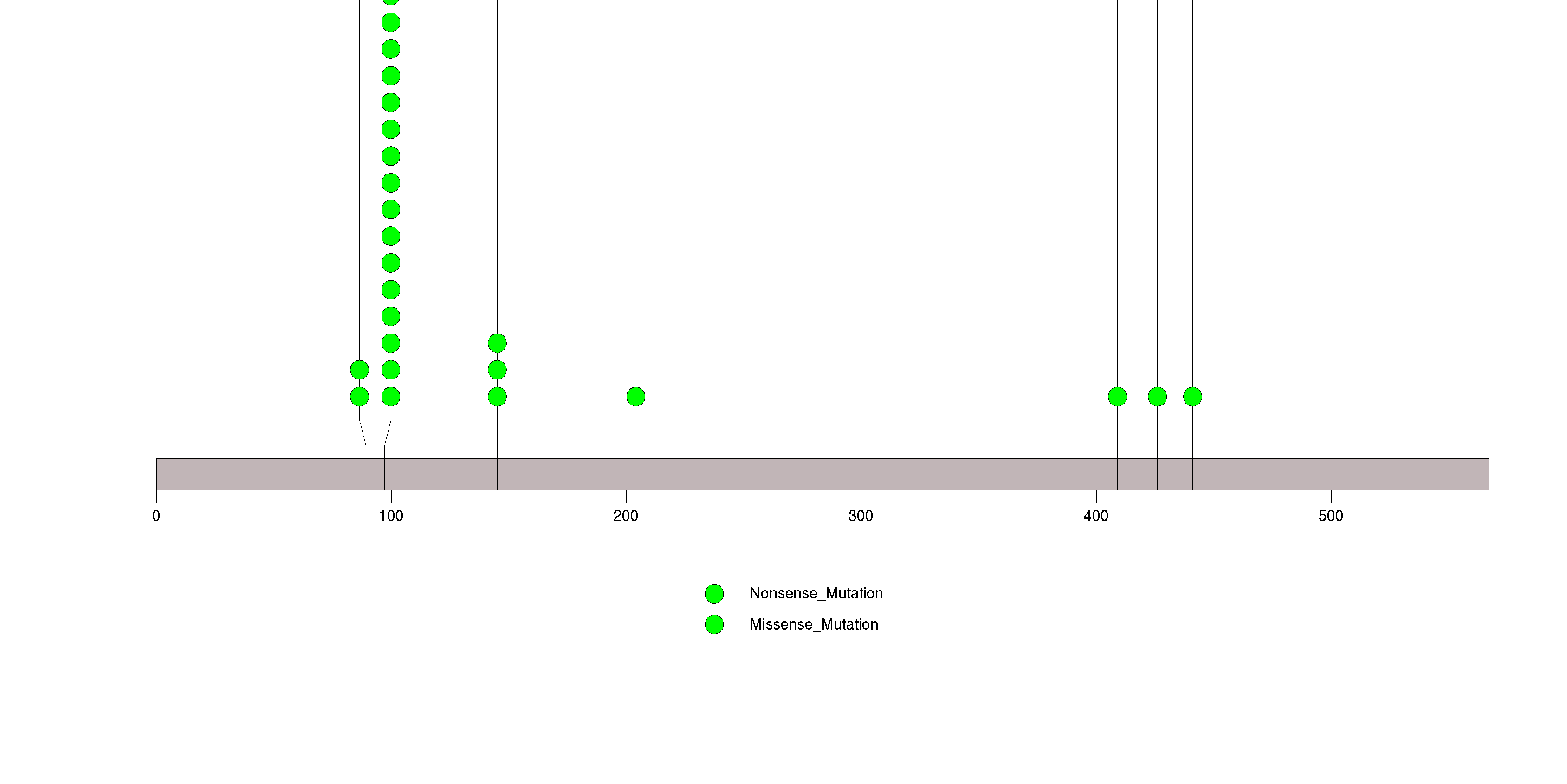
Figure S10. This figure depicts the distribution of mutations and mutation types across the UPF3A significant gene.
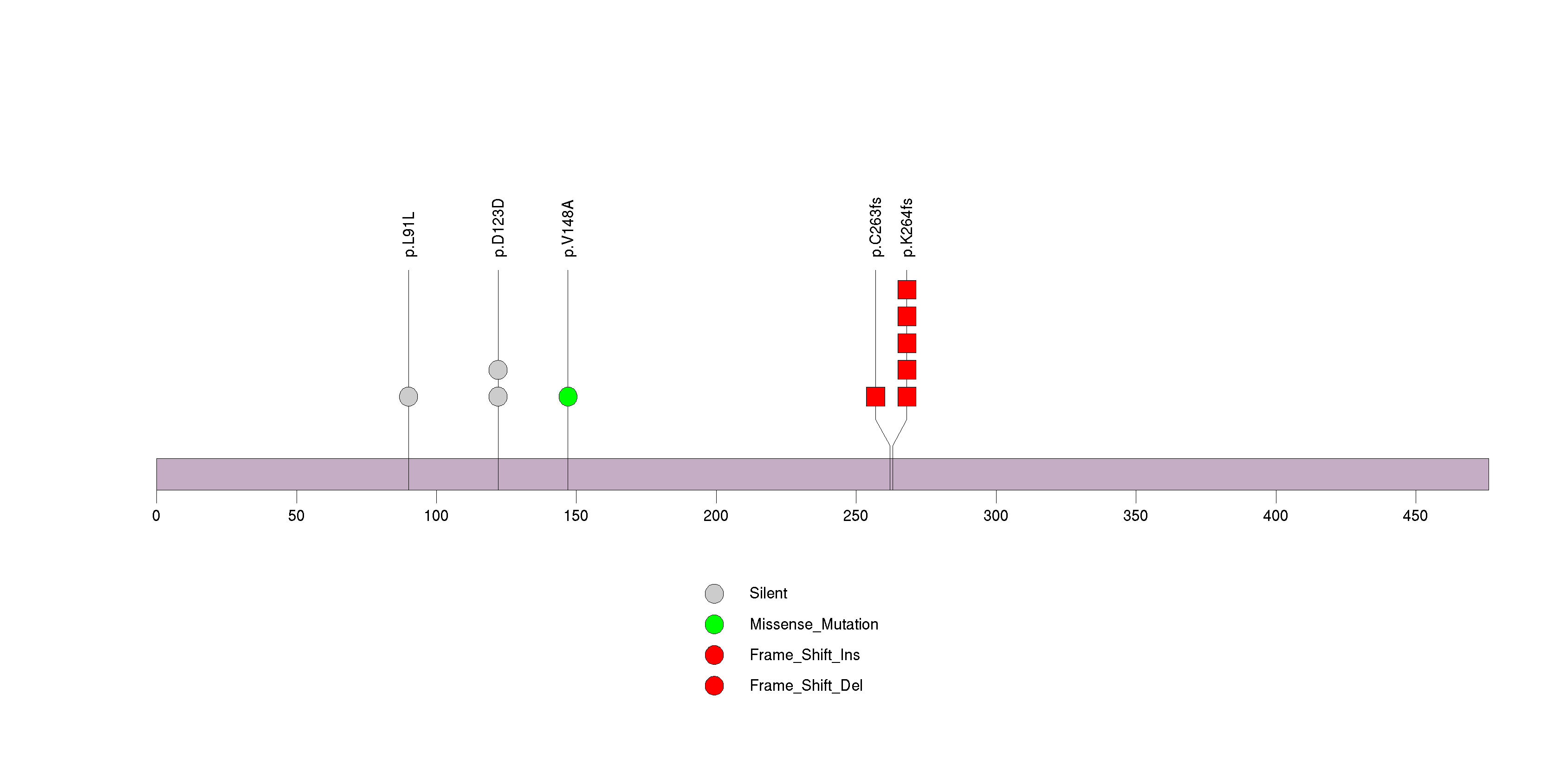
Figure S11. This figure depicts the distribution of mutations and mutation types across the MLL2 significant gene.
In brief, we tabulate the number of mutations and the number of covered bases for each gene. The counts are broken down by mutation context category: four context categories that are discovered by MutSig, and one for indel and 'null' mutations, which include indels, nonsense mutations, splice-site mutations, and non-stop (read-through) mutations. For each gene, we calculate the probability of seeing the observed constellation of mutations, i.e. the product P1 x P2 x ... x Pm, or a more extreme one, given the background mutation rates calculated across the dataset. [1]
This is an experimental feature. The full results of the analysis summarized in this report can be downloaded from the TCGA Data Coordination Center.