(primary blood tumor (peripheral) cohort)
This pipeline computes the correlation between cancer subtypes identified by different molecular patterns and selected clinical features.
Testing the association between subtypes identified by 5 different clustering approaches and 3 clinical features across 197 patients, 2 significant findings detected with P value < 0.05 and Q value < 0.25.
-
6 subtypes identified in current cancer cohort by 'METHLYATION CNMF'. These subtypes correlate to 'Time to Death' and 'AGE'.
-
CNMF clustering analysis on sequencing-based mRNA expression data identified 3 subtypes that do not correlate to any clinical features.
-
Consensus hierarchical clustering analysis on sequencing-based mRNA expression data identified 2 subtypes that do not correlate to any clinical features.
-
CNMF clustering analysis on sequencing-based miR expression data identified 3 subtypes that do not correlate to any clinical features.
-
Consensus hierarchical clustering analysis on sequencing-based miR expression data identified 3 subtypes that do not correlate to any clinical features.
Table 1. Get Full Table Overview of the association between subtypes identified by 5 different clustering approaches and 3 clinical features. Shown in the table are P values (Q values). Thresholded by P value < 0.05 and Q value < 0.25, 2 significant findings detected.
|
Clinical Features |
Time to Death |
AGE | GENDER |
| Statistical Tests | logrank test | ANOVA | Fisher's exact test |
| METHLYATION CNMF |
2.96e-05 (0.000415) |
9.48e-09 (1.42e-07) |
0.77 (1.00) |
| RNAseq CNMF subtypes |
0.308 (1.00) |
0.39 (1.00) |
0.312 (1.00) |
| RNAseq cHierClus subtypes |
0.683 (1.00) |
0.0292 (0.359) |
1 (1.00) |
| MIRseq CNMF subtypes |
0.0276 (0.359) |
0.221 (1.00) |
0.797 (1.00) |
| MIRseq cHierClus subtypes |
0.0358 (0.393) |
0.077 (0.77) |
0.767 (1.00) |
Table S1. Get Full Table Description of clustering approach #1: 'METHLYATION CNMF'
| Cluster Labels | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| Number of samples | 48 | 18 | 26 | 40 | 48 | 14 |
P value = 2.96e-05 (logrank test), Q value = 0.00041
Table S2. Clustering Approach #1: 'METHLYATION CNMF' versus Clinical Feature #1: 'Time to Death'
| nPatients | nDeath | Duration Range (Median), Month | |
|---|---|---|---|
| ALL | 169 | 106 | 0.9 - 94.1 (12.0) |
| subtype1 | 42 | 30 | 1.0 - 69.0 (8.0) |
| subtype2 | 16 | 4 | 0.9 - 84.0 (36.0) |
| subtype3 | 24 | 17 | 1.0 - 56.1 (15.5) |
| subtype4 | 36 | 15 | 1.0 - 94.1 (19.5) |
| subtype5 | 40 | 31 | 0.9 - 52.0 (10.5) |
| subtype6 | 11 | 9 | 1.0 - 42.0 (10.0) |
Figure S1. Get High-res Image Clustering Approach #1: 'METHLYATION CNMF' versus Clinical Feature #1: 'Time to Death'
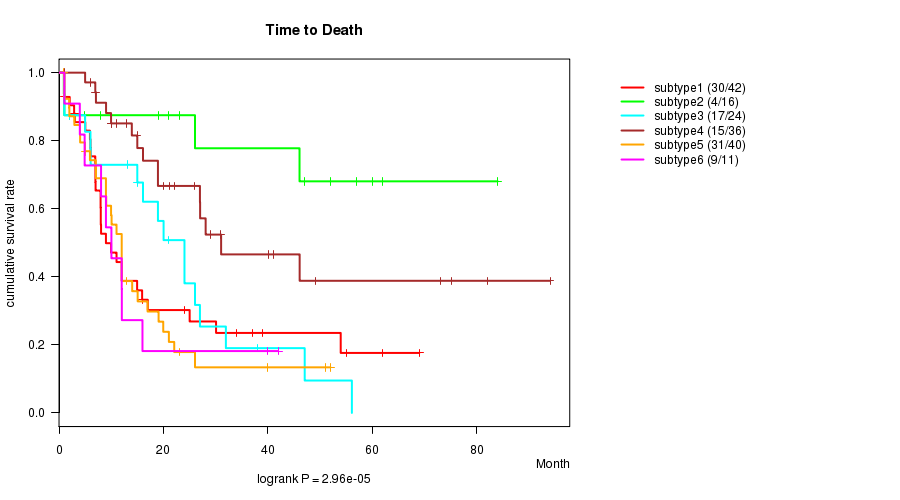
P value = 9.48e-09 (ANOVA), Q value = 1.4e-07
Table S3. Clustering Approach #1: 'METHLYATION CNMF' versus Clinical Feature #2: 'AGE'
| nPatients | Mean (Std.Dev) | |
|---|---|---|
| ALL | 194 | 55.1 (16.0) |
| subtype1 | 48 | 56.6 (14.2) |
| subtype2 | 18 | 47.4 (14.8) |
| subtype3 | 26 | 61.3 (13.3) |
| subtype4 | 40 | 45.1 (16.9) |
| subtype5 | 48 | 63.8 (12.0) |
| subtype6 | 14 | 47.4 (15.7) |
Figure S2. Get High-res Image Clustering Approach #1: 'METHLYATION CNMF' versus Clinical Feature #2: 'AGE'
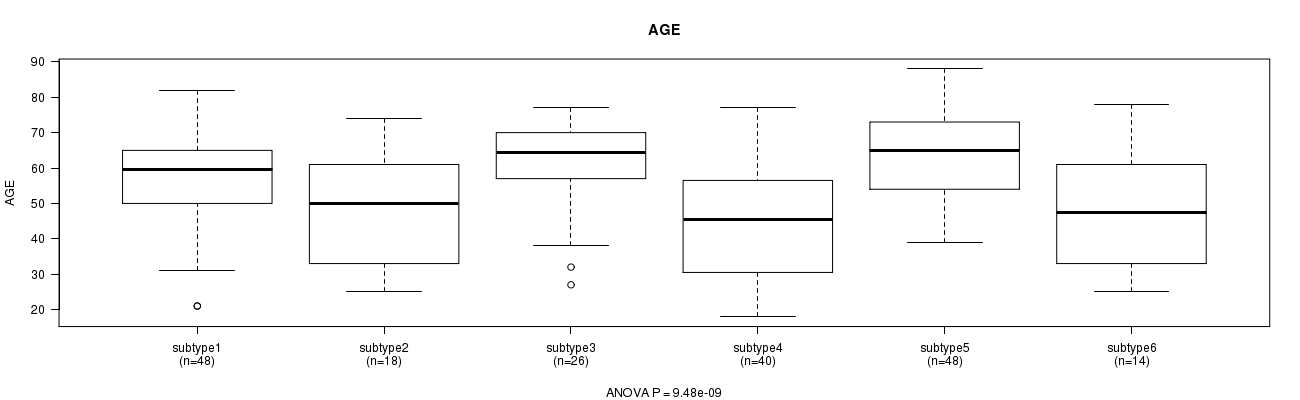
P value = 0.77 (Chi-square test), Q value = 1
Table S4. Clustering Approach #1: 'METHLYATION CNMF' versus Clinical Feature #3: 'GENDER'
| nPatients | FEMALE | MALE |
|---|---|---|
| ALL | 89 | 105 |
| subtype1 | 24 | 24 |
| subtype2 | 10 | 8 |
| subtype3 | 13 | 13 |
| subtype4 | 18 | 22 |
| subtype5 | 19 | 29 |
| subtype6 | 5 | 9 |
Figure S3. Get High-res Image Clustering Approach #1: 'METHLYATION CNMF' versus Clinical Feature #3: 'GENDER'
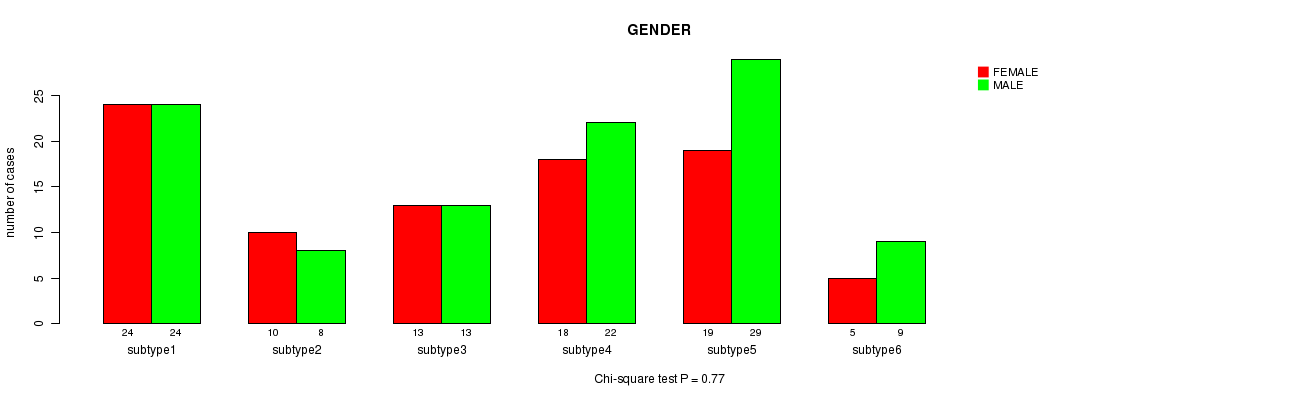
Table S5. Get Full Table Description of clustering approach #2: 'RNAseq CNMF subtypes'
| Cluster Labels | 1 | 2 | 3 |
|---|---|---|---|
| Number of samples | 74 | 57 | 48 |
P value = 0.308 (logrank test), Q value = 1
Table S6. Clustering Approach #2: 'RNAseq CNMF subtypes' versus Clinical Feature #1: 'Time to Death'
| nPatients | nDeath | Duration Range (Median), Month | |
|---|---|---|---|
| ALL | 157 | 97 | 0.9 - 94.1 (12.0) |
| subtype1 | 67 | 39 | 1.0 - 94.1 (16.1) |
| subtype2 | 50 | 32 | 0.9 - 75.1 (11.0) |
| subtype3 | 40 | 26 | 0.9 - 62.0 (9.5) |
Figure S4. Get High-res Image Clustering Approach #2: 'RNAseq CNMF subtypes' versus Clinical Feature #1: 'Time to Death'
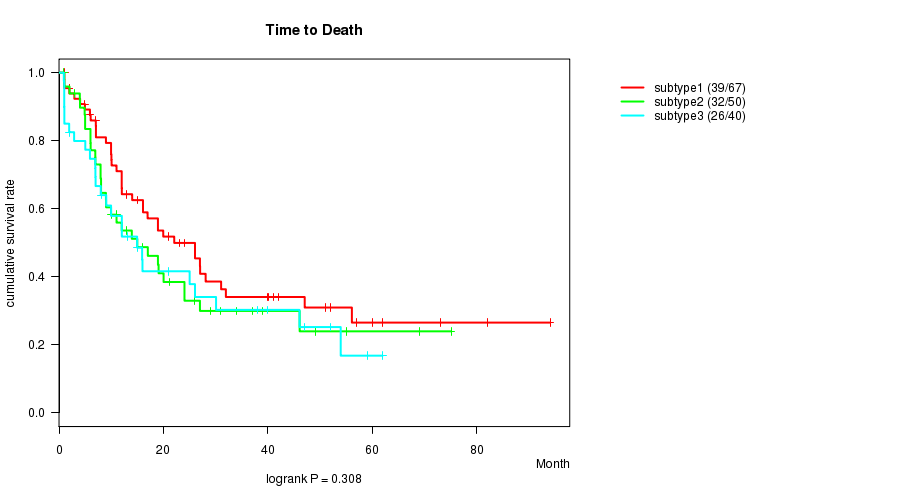
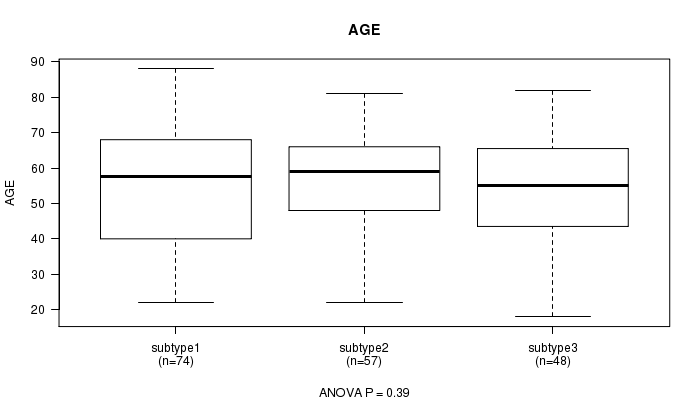
P value = 0.39 (ANOVA), Q value = 1
Table S7. Clustering Approach #2: 'RNAseq CNMF subtypes' versus Clinical Feature #2: 'AGE'
| nPatients | Mean (Std.Dev) | |
|---|---|---|
| ALL | 179 | 55.0 (15.9) |
| subtype1 | 74 | 53.8 (17.1) |
| subtype2 | 57 | 57.4 (13.6) |
| subtype3 | 48 | 54.0 (16.7) |
Figure S5. Get High-res Image Clustering Approach #2: 'RNAseq CNMF subtypes' versus Clinical Feature #2: 'AGE'
P value = 0.312 (Fisher's exact test), Q value = 1
Table S8. Clustering Approach #2: 'RNAseq CNMF subtypes' versus Clinical Feature #3: 'GENDER'
| nPatients | FEMALE | MALE |
|---|---|---|
| ALL | 84 | 95 |
| subtype1 | 33 | 41 |
| subtype2 | 24 | 33 |
| subtype3 | 27 | 21 |
Figure S6. Get High-res Image Clustering Approach #2: 'RNAseq CNMF subtypes' versus Clinical Feature #3: 'GENDER'
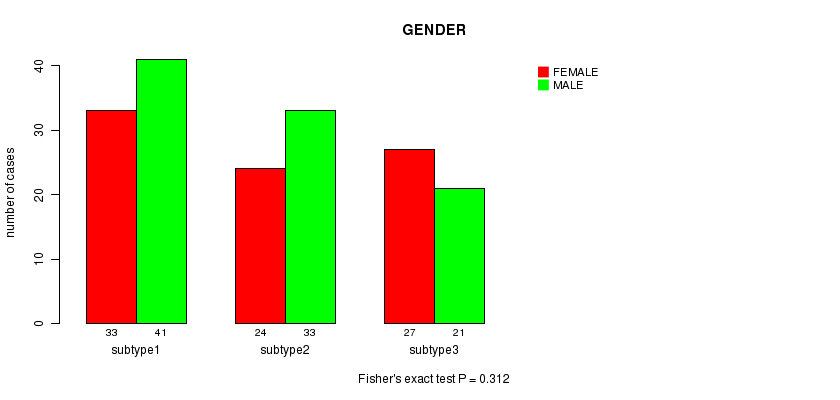
Table S9. Get Full Table Description of clustering approach #3: 'RNAseq cHierClus subtypes'
| Cluster Labels | 1 | 2 |
|---|---|---|
| Number of samples | 61 | 118 |
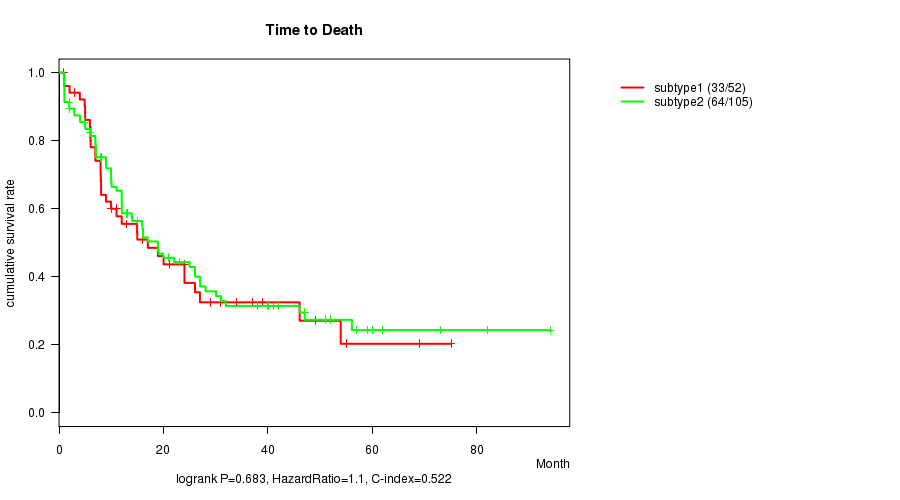
P value = 0.683 (logrank test), Q value = 1
Table S10. Clustering Approach #3: 'RNAseq cHierClus subtypes' versus Clinical Feature #1: 'Time to Death'
| nPatients | nDeath | Duration Range (Median), Month | |
|---|---|---|---|
| ALL | 157 | 97 | 0.9 - 94.1 (12.0) |
| subtype1 | 52 | 33 | 0.9 - 75.1 (11.5) |
| subtype2 | 105 | 64 | 0.9 - 94.1 (12.9) |
Figure S7. Get High-res Image Clustering Approach #3: 'RNAseq cHierClus subtypes' versus Clinical Feature #1: 'Time to Death'
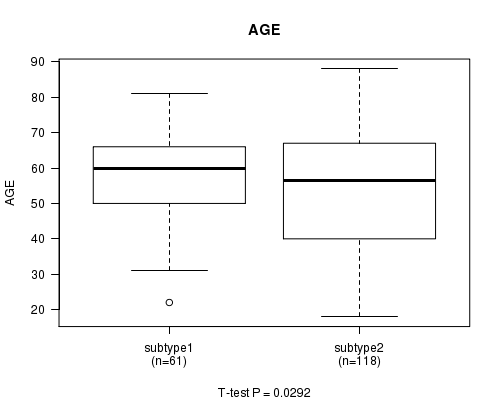
P value = 0.0292 (t-test), Q value = 0.36
Table S11. Clustering Approach #3: 'RNAseq cHierClus subtypes' versus Clinical Feature #2: 'AGE'
| nPatients | Mean (Std.Dev) | |
|---|---|---|
| ALL | 179 | 55.0 (15.9) |
| subtype1 | 61 | 58.3 (12.8) |
| subtype2 | 118 | 53.3 (17.1) |
Figure S8. Get High-res Image Clustering Approach #3: 'RNAseq cHierClus subtypes' versus Clinical Feature #2: 'AGE'
P value = 1 (Fisher's exact test), Q value = 1
Table S12. Clustering Approach #3: 'RNAseq cHierClus subtypes' versus Clinical Feature #3: 'GENDER'
| nPatients | FEMALE | MALE |
|---|---|---|
| ALL | 84 | 95 |
| subtype1 | 29 | 32 |
| subtype2 | 55 | 63 |
Figure S9. Get High-res Image Clustering Approach #3: 'RNAseq cHierClus subtypes' versus Clinical Feature #3: 'GENDER'
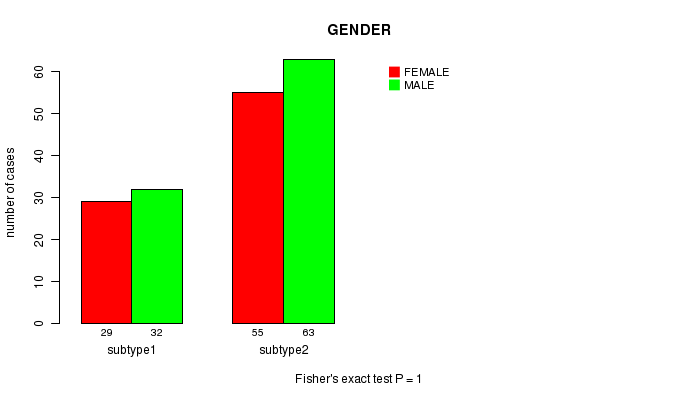
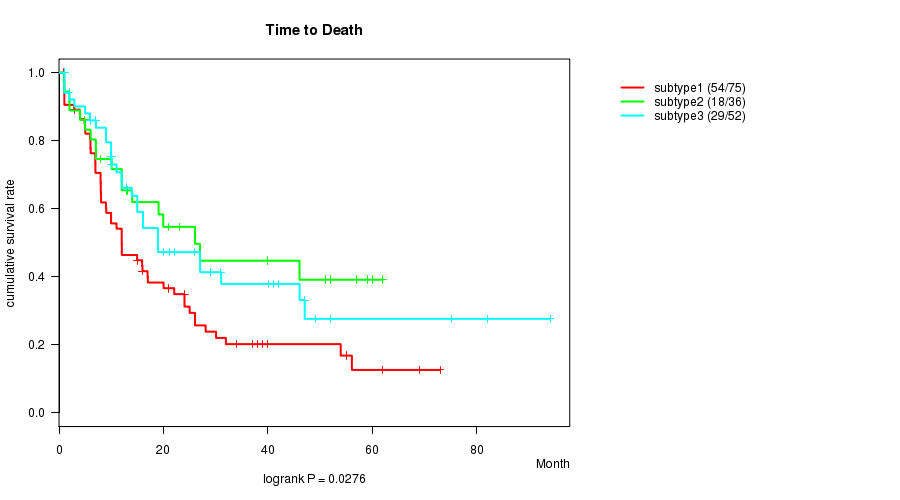
Table S13. Get Full Table Description of clustering approach #4: 'MIRseq CNMF subtypes'
| Cluster Labels | 1 | 2 | 3 |
|---|---|---|---|
| Number of samples | 86 | 40 | 61 |
P value = 0.0276 (logrank test), Q value = 0.36
Table S14. Clustering Approach #4: 'MIRseq CNMF subtypes' versus Clinical Feature #1: 'Time to Death'
| nPatients | nDeath | Duration Range (Median), Month | |
|---|---|---|---|
| ALL | 163 | 101 | 0.9 - 94.1 (12.0) |
| subtype1 | 75 | 54 | 0.9 - 73.0 (10.0) |
| subtype2 | 36 | 18 | 0.9 - 62.0 (14.5) |
| subtype3 | 52 | 29 | 1.0 - 94.1 (15.0) |
Figure S10. Get High-res Image Clustering Approach #4: 'MIRseq CNMF subtypes' versus Clinical Feature #1: 'Time to Death'
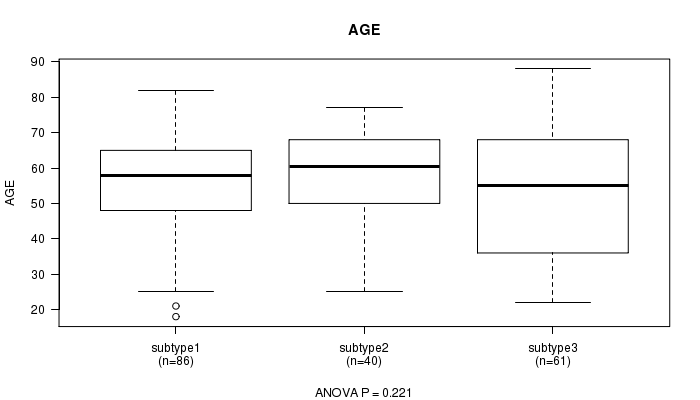
P value = 0.221 (ANOVA), Q value = 1
Table S15. Clustering Approach #4: 'MIRseq CNMF subtypes' versus Clinical Feature #2: 'AGE'
| nPatients | Mean (Std.Dev) | |
|---|---|---|
| ALL | 187 | 55.1 (16.0) |
| subtype1 | 86 | 56.1 (14.5) |
| subtype2 | 40 | 57.2 (14.5) |
| subtype3 | 61 | 52.2 (18.7) |
Figure S11. Get High-res Image Clustering Approach #4: 'MIRseq CNMF subtypes' versus Clinical Feature #2: 'AGE'
P value = 0.797 (Fisher's exact test), Q value = 1
Table S16. Clustering Approach #4: 'MIRseq CNMF subtypes' versus Clinical Feature #3: 'GENDER'
| nPatients | FEMALE | MALE |
|---|---|---|
| ALL | 86 | 101 |
| subtype1 | 39 | 47 |
| subtype2 | 17 | 23 |
| subtype3 | 30 | 31 |
Figure S12. Get High-res Image Clustering Approach #4: 'MIRseq CNMF subtypes' versus Clinical Feature #3: 'GENDER'
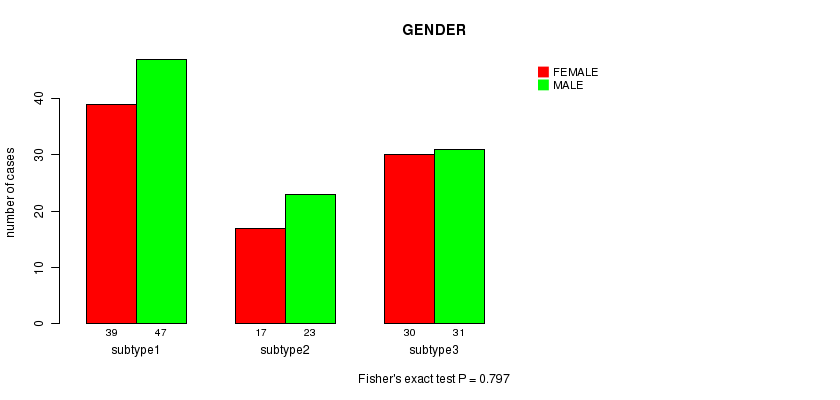
Table S17. Get Full Table Description of clustering approach #5: 'MIRseq cHierClus subtypes'
| Cluster Labels | 1 | 2 | 3 |
|---|---|---|---|
| Number of samples | 38 | 82 | 67 |
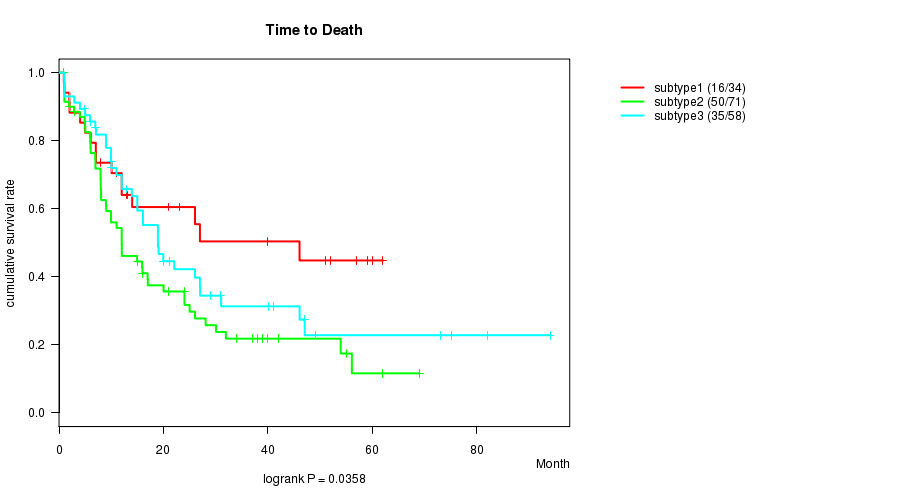
P value = 0.0358 (logrank test), Q value = 0.39
Table S18. Clustering Approach #5: 'MIRseq cHierClus subtypes' versus Clinical Feature #1: 'Time to Death'
| nPatients | nDeath | Duration Range (Median), Month | |
|---|---|---|---|
| ALL | 163 | 101 | 0.9 - 94.1 (12.0) |
| subtype1 | 34 | 16 | 0.9 - 62.0 (14.5) |
| subtype2 | 71 | 50 | 0.9 - 69.0 (10.0) |
| subtype3 | 58 | 35 | 1.0 - 94.1 (15.0) |
Figure S13. Get High-res Image Clustering Approach #5: 'MIRseq cHierClus subtypes' versus Clinical Feature #1: 'Time to Death'
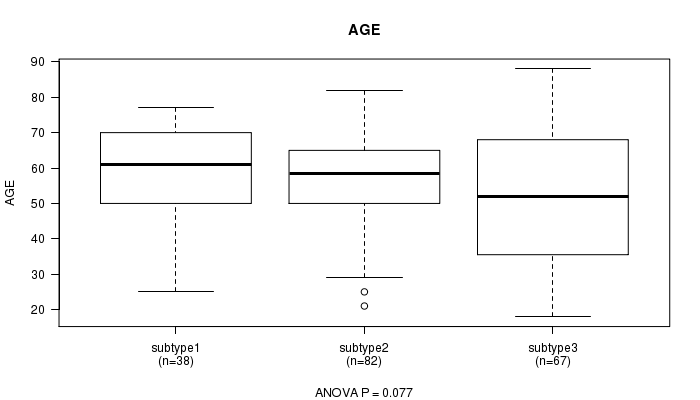
P value = 0.077 (ANOVA), Q value = 0.77
Table S19. Clustering Approach #5: 'MIRseq cHierClus subtypes' versus Clinical Feature #2: 'AGE'
| nPatients | Mean (Std.Dev) | |
|---|---|---|
| ALL | 187 | 55.1 (16.0) |
| subtype1 | 38 | 58.2 (14.2) |
| subtype2 | 82 | 56.4 (13.6) |
| subtype3 | 67 | 51.6 (19.1) |
Figure S14. Get High-res Image Clustering Approach #5: 'MIRseq cHierClus subtypes' versus Clinical Feature #2: 'AGE'
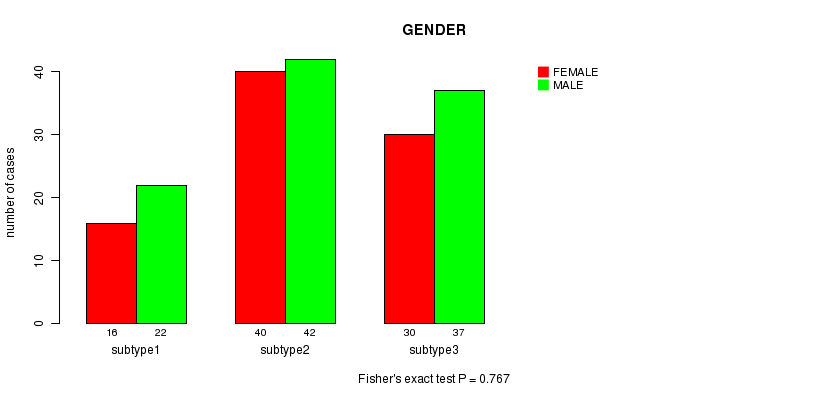
P value = 0.767 (Fisher's exact test), Q value = 1
Table S20. Clustering Approach #5: 'MIRseq cHierClus subtypes' versus Clinical Feature #3: 'GENDER'
| nPatients | FEMALE | MALE |
|---|---|---|
| ALL | 86 | 101 |
| subtype1 | 16 | 22 |
| subtype2 | 40 | 42 |
| subtype3 | 30 | 37 |
Figure S15. Get High-res Image Clustering Approach #5: 'MIRseq cHierClus subtypes' versus Clinical Feature #3: 'GENDER'
-
Cluster data file = LAML-TB.mergedcluster.txt
-
Clinical data file = LAML-TP.clin.merged.picked.txt
-
Number of patients = 197
-
Number of clustering approaches = 5
-
Number of selected clinical features = 3
-
Exclude small clusters that include fewer than K patients, K = 3
consensus non-negative matrix factorization clustering approach (Brunet et al. 2004)
Resampling-based clustering method (Monti et al. 2003)
For survival clinical features, the Kaplan-Meier survival curves of tumors with and without gene mutations were plotted and the statistical significance P values were estimated by logrank test (Bland and Altman 2004) using the 'survdiff' function in R
For continuous numerical clinical features, one-way analysis of variance (Howell 2002) was applied to compare the clinical values between tumor subtypes using 'anova' function in R
For multi-class clinical features (nominal or ordinal), Chi-square tests (Greenwood and Nikulin 1996) were used to estimate the P values using the 'chisq.test' function in R
For binary clinical features, two-tailed Fisher's exact tests (Fisher 1922) were used to estimate the P values using the 'fisher.test' function in R
For continuous numerical clinical features, two-tailed Student's t test with unequal variance (Lehmann and Romano 2005) was applied to compare the clinical values between two tumor subtypes using 't.test' function in R
For multiple hypothesis correction, Q value is the False Discovery Rate (FDR) analogue of the P value (Benjamini and Hochberg 1995), defined as the minimum FDR at which the test may be called significant. We used the 'Benjamini and Hochberg' method of 'p.adjust' function in R to convert P values into Q values.
This is an experimental feature. The full results of the analysis summarized in this report can be downloaded from the TCGA Data Coordination Center.