This pipeline calculates clusters based on a consensus non-negative matrix factorization (NMF) clustering method ##REF##1,##REF##3. This pipeline has the following features:
-
Convert input data set to a non-negitive matrix by column rank normalization.
-
Classify samples into consensus clusters.
-
Determine differentially expressed focal events for each subtype.
The most robust consensus NMF clustering of 177 samples using the 44 copy number focal regions was identified for k = 4 clusters. We computed the clustering for k = 2 to k = 8 and used the cophenetic correlation coefficient to determine the best solution.
Figure 1. Get High-res Image Samples were separated into 4 clusters. Shown are 177 samples and 49 marker focal events. The color bar of the row indicates the marker focal events for the corresponding cluster.
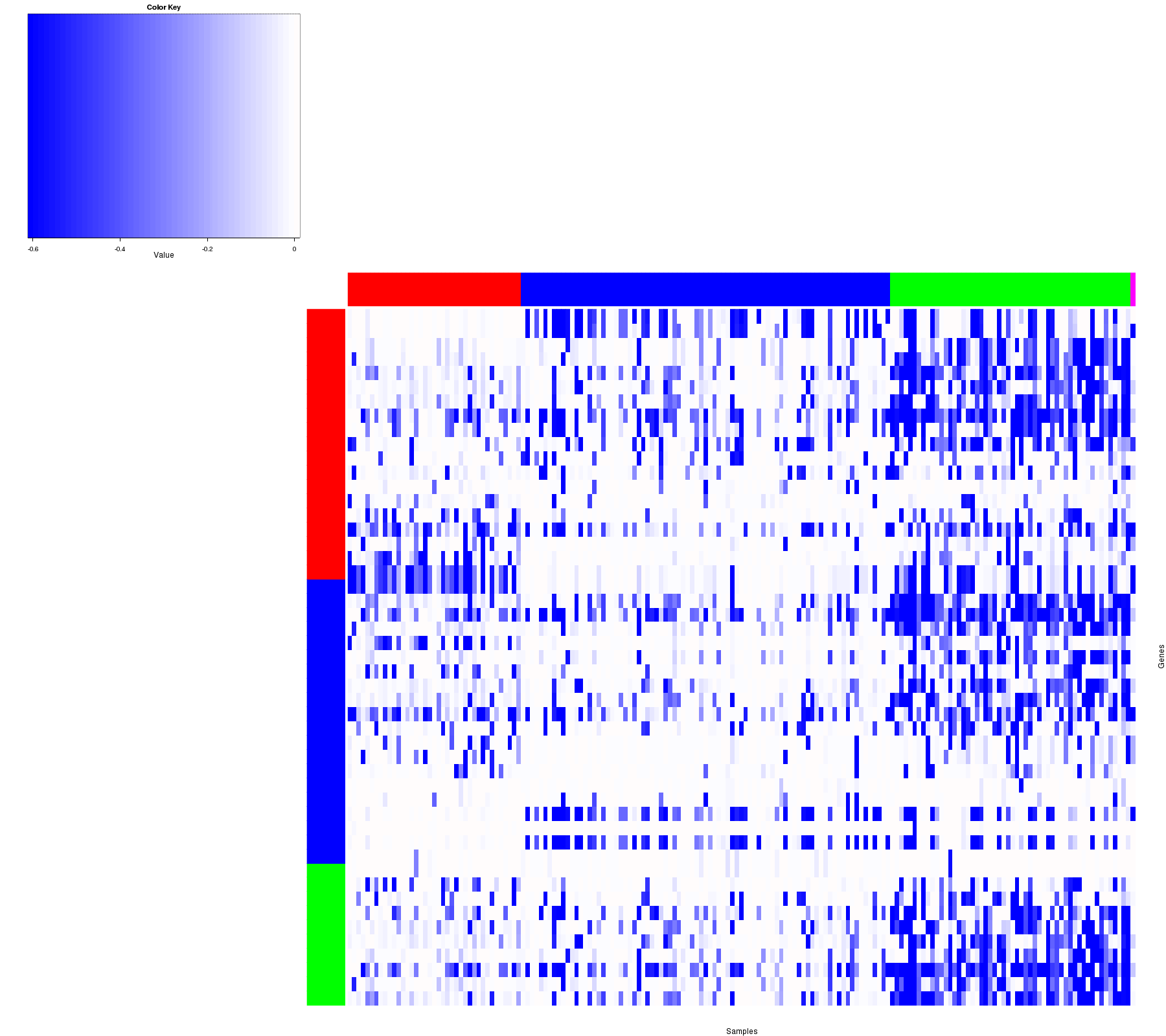
Figure 2. Get High-res Image Heatmap with a standard hierarchical clustering for 177 samples and the 44 focal events.
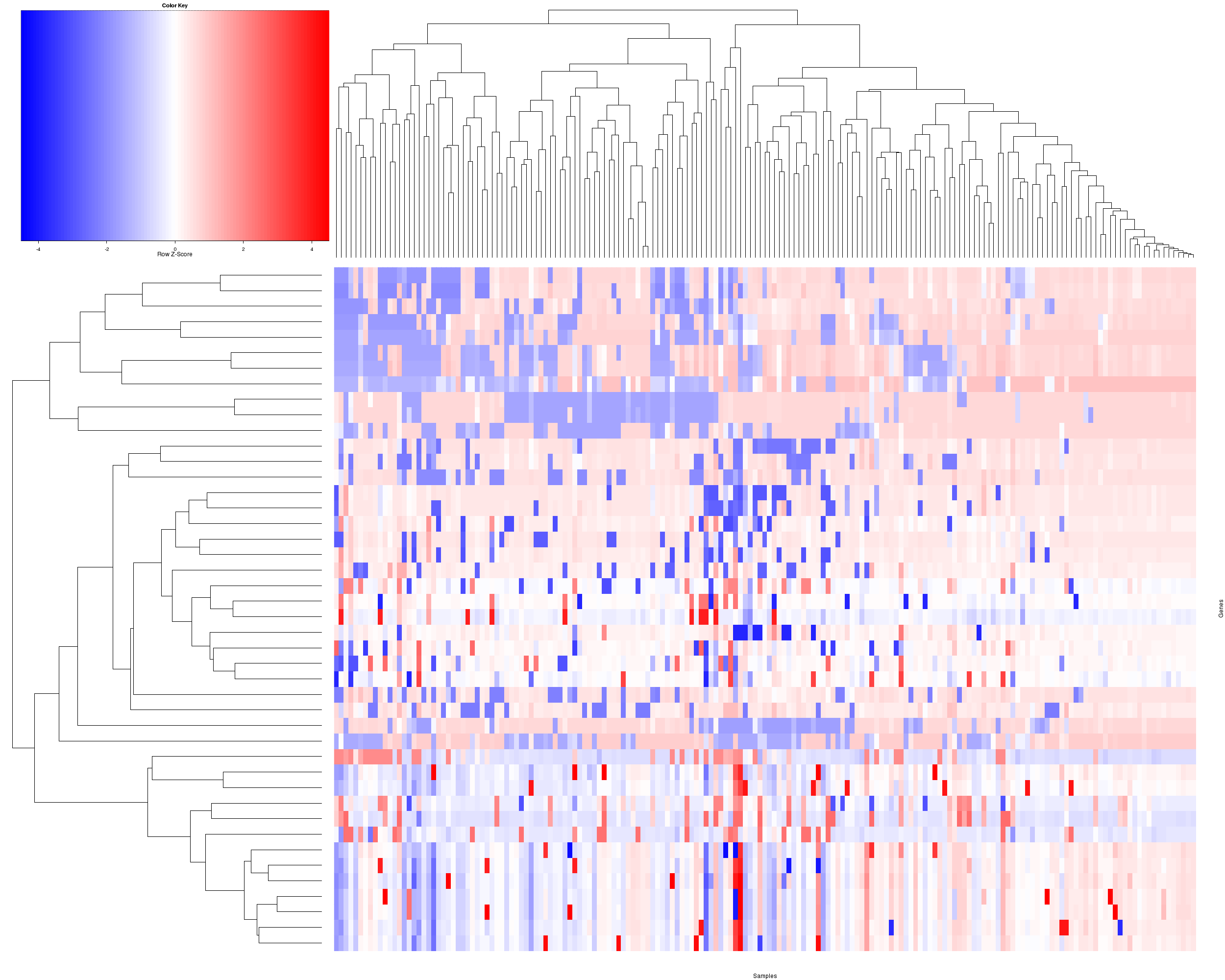
Figure 3. Get High-res Image The consensus matrix after clustering shows 4 clusters with limited overlap between clusters.
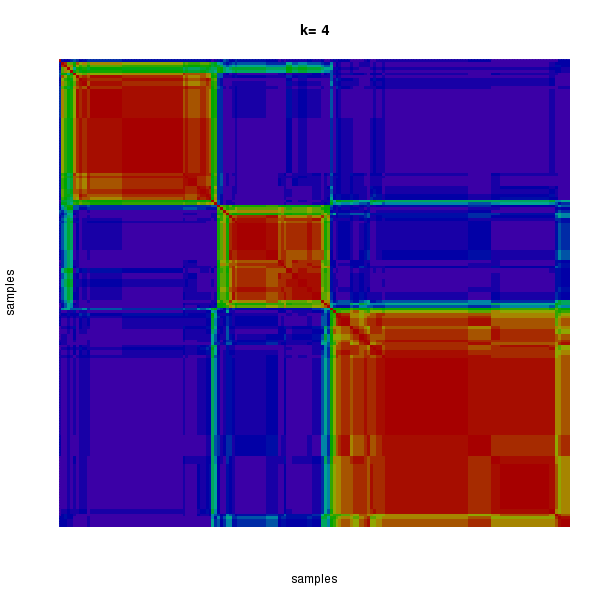
Figure 4. Get High-res Image The correlation matrix also shows 4 clusters.
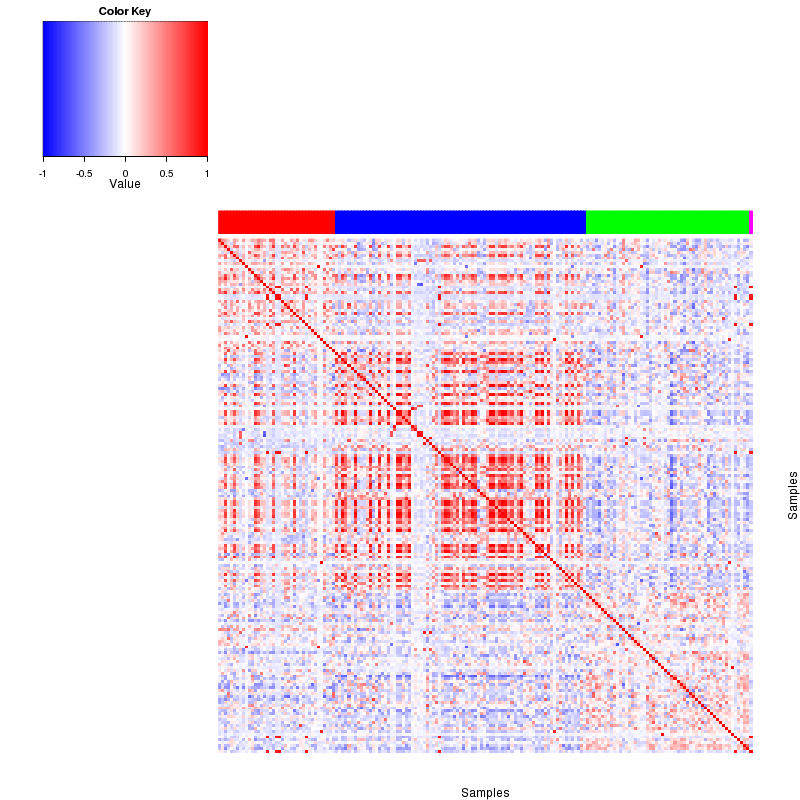
Figure 5. Get High-res Image The silhouette width was calculated for each sample and each value of k. The left panel shows the average silhouette width across all samples for each tested k (left panel). The right panels shows assignments of clusters to samples and the silhouette width of each sample for the most robust clustering.
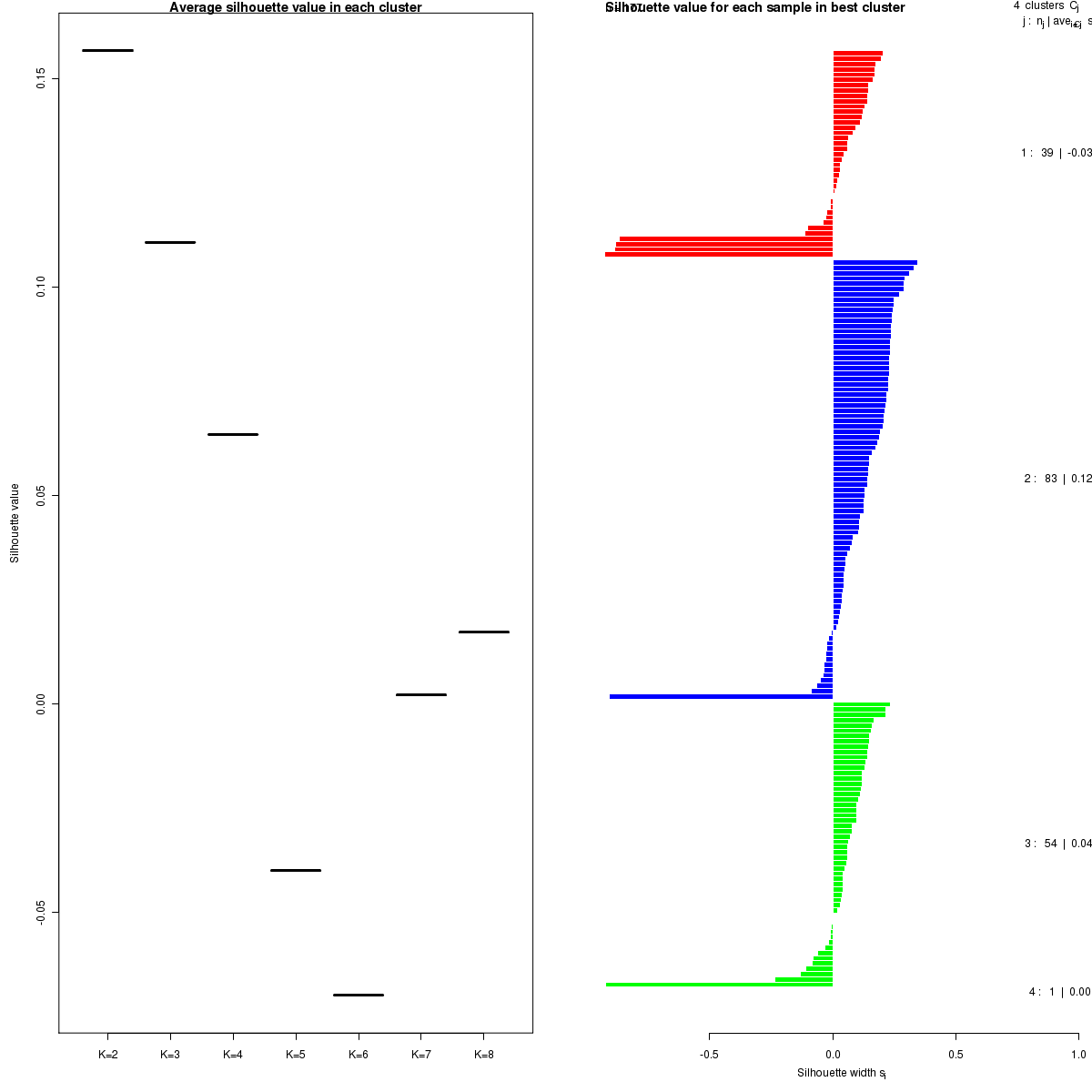
Table 1. Get Full Table List of samples with 4 subtypes and silhouette width.
| SampleName | cluster | silhouetteValue |
|---|---|---|
| TCGA-CH-5737-01A-11D-1574-01 | 1 | 0.17 |
| TCGA-CH-5740-01A-11D-1574-01 | 1 | 0.029 |
| TCGA-CH-5748-01A-11D-1574-01 | 1 | 0.031 |
| TCGA-CH-5767-01A-11D-1785-01 | 1 | 0.12 |
| TCGA-CH-5771-01A-21D-1574-01 | 1 | 0.0093 |
| TCGA-CH-5772-01A-11D-1574-01 | 1 | -0.038 |
| TCGA-CH-5792-01A-11D-1574-01 | 1 | 0.17 |
| TCGA-EJ-5505-01A-01D-1574-01 | 1 | -0.0082 |
| TCGA-EJ-5509-01A-01D-1574-01 | 1 | 0.17 |
| TCGA-EJ-5531-01A-01D-1574-01 | 1 | 0.061 |
Table 2. Get Full Table List of samples belonging to each cluster in different k clusters.
| SampleName | K=2 | K=3 | K=4 | K=5 | K=6 | K=7 | K=8 |
|---|---|---|---|---|---|---|---|
| TCGA-CH-5737-01A-11D-1574-01 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| TCGA-CH-5738-01A-11D-1574-01 | 1 | 2 | 2 | 2 | 1 | 2 | 2 |
| TCGA-CH-5740-01A-11D-1574-01 | 1 | 1 | 1 | 4 | 1 | 1 | 4 |
| TCGA-CH-5741-01A-11D-1574-01 | 1 | 2 | 2 | 1 | 1 | 4 | 3 |
| TCGA-CH-5743-01A-21D-1574-01 | 1 | 2 | 2 | 2 | 1 | 2 | 2 |
| TCGA-CH-5746-01A-11D-1574-01 | 1 | 2 | 2 | 2 | 1 | 1 | 3 |
| TCGA-CH-5748-01A-11D-1574-01 | 1 | 1 | 1 | 1 | 1 | 1 | 4 |
| TCGA-CH-5750-01A-11D-1574-01 | 1 | 2 | 2 | 2 | 1 | 2 | 2 |
| TCGA-CH-5752-01A-11D-1574-01 | 1 | 2 | 2 | 1 | 1 | 1 | 4 |
| TCGA-CH-5762-01A-11D-1574-01 | 1 | 3 | 3 | 3 | 3 | 2 | 7 |
Samples most representative of the clusters, hereby called core samples were identified based on positive silhouette width, indicating higher similarity to their own class than to any other class member. Core samples were used to select differentially expressed marker focal events for each subtype by comparing the subclass versus the other subclasses, using Student's t-test.
Table 3. Get Full Table List of marker focal events with p <= 0.05.
| Composite.Element.REF | p | difference | q | subclass |
|---|---|---|---|---|
| DEL PEAK 27(21Q22.3) | 4.8e-09 | 0.21 | 1.1e-07 | 1 |
| DEL PEAK 26(21Q22.2) | 5.1e-09 | 0.21 | 1.1e-07 | 1 |
| DEL PEAK 24(18Q22.1) | 1.4e-08 | 0.17 | 2.1e-07 | 1 |
| DEL PEAK 25(18Q23) | 1.9e-06 | 0.16 | 0.000014 | 1 |
| DEL PEAK 21(16Q24.1) | 0.000052 | 0.16 | 0.00032 | 1 |
| DEL PEAK 22(17P13.1) | 8.8e-07 | 0.14 | 7.8e-06 | 1 |
| DEL PEAK 20(16Q22.3) | 0.00025 | 0.13 | 0.0014 | 1 |
| DEL PEAK 14(8P21.3) | 0.029 | 0.13 | 0.091 | 1 |
| AMP PEAK 4(8P11.22) | 0.038 | 0.13 | 0.098 | 1 |
| DEL PEAK 16(10Q23.31) | 0.034 | 0.12 | 0.093 | 1 |
Copy number data file = All Lesions File actual copy number part (all_lesions.conf_##.txt, where ## is the confidence level). The all lesions file is from GISTIC pipeline and summarizes the results from the GISTIC run. It contains data about the significant regions of amplification and deletion as well as which samples are amplified or deleted in each of these regions. The identified regions are listed down the first column, and the samples are listed across the first row, starting in column 10
Non-negative matrix factorization (NMF) is an unsupervised learning algorithm that has been shown to identify molecular patterns when applied to gene expression data ##REF##1,##REF##3. Rather than separating gene clusters based on distance computation, NMF detects contextdependent patterns of gene expression in complex biological systems.
We use the cophenetic correlation coefficient ##REF##1 to determine the cluster that yields the most robust clustering. The cophenetic correlation coefficient is computed based on the consensus matrix of the CNMF clustering, and measures how reliably the same samples are assigned to the same cluster across many iterations of the clustering lgorithm with random initializations. The cophenetic correlation coefficient lies between 0 and 1, with higher values indicating more stable cluster assignments. We select the number of clusters k based on the largest observed correlation coefficient for all tested values of k.
Silhouette width is defined as the ratio of average distance of each sample to samples in the same cluster to the smallest distance to samples not in the same cluster. If silhouette width is close to 1, it means that sample is well clustered. If silhouette width is close to -1, it means that sample is misclassified ##REF##2.
This is an experimental feature. The full results of the analysis summarized in this report can be downloaded from the TCGA Data Coordination Center.