This pipeline computes the correlation between significant copy number variation (cnv) genes and molecular subtypes.
Testing the association between copy number variation of 27 peak regions and molecular subtype 'METHLYATION_CNMF' across 20 patients, one significant finding detected with Q value < 0.25.
-
Del Peak 5(5q11.2) cnvs correlated to 'METHLYATION_CNMF'.
Table 1. Get Full Table Overview of the association between significant copy number variation of 27 regions and 1 molecular subtypes. Shown in the table are P values (Q values). Thresholded by Q value < 0.25, one significant finding detected.
|
Molecular subtypes |
METHLYATION CNMF |
||
| nCNV (%) | nWild-Type | Fisher's exact test | |
| Del Peak 5(5q11 2) | 0 (0%) | 9 |
0.00125 (0.0338) |
| Amp Peak 1(1q42 3) | 0 (0%) | 11 |
0.255 (1.00) |
| Amp Peak 2(2p15) | 0 (0%) | 10 |
1 (1.00) |
| Amp Peak 3(3q28) | 0 (0%) | 3 |
0.0228 (0.593) |
| Amp Peak 4(6p12 3) | 0 (0%) | 14 |
1 (1.00) |
| Amp Peak 5(7p11 2) | 0 (0%) | 8 |
0.103 (1.00) |
| Amp Peak 6(7q31 1) | 0 (0%) | 6 |
0.638 (1.00) |
| Amp Peak 8(10p11 21) | 0 (0%) | 13 |
0.457 (1.00) |
| Amp Peak 9(11p13) | 0 (0%) | 14 |
0.808 (1.00) |
| Amp Peak 10(11q13 3) | 0 (0%) | 7 |
0.457 (1.00) |
| Amp Peak 11(12p13 33) | 0 (0%) | 7 |
0.0716 (1.00) |
| Amp Peak 12(14q21 3) | 0 (0%) | 9 |
0.31 (1.00) |
| Amp Peak 13(18p11 31) | 0 (0%) | 12 |
0.811 (1.00) |
| Amp Peak 14(Xp21 1) | 0 (0%) | 14 |
0.808 (1.00) |
| Del Peak 1(2q22 1) | 0 (0%) | 14 |
1 (1.00) |
| Del Peak 2(3p14 2) | 0 (0%) | 4 |
0.773 (1.00) |
| Del Peak 4(4q21 23) | 0 (0%) | 11 |
0.381 (1.00) |
| Del Peak 6(6p25 3) | 0 (0%) | 11 |
0.464 (1.00) |
| Del Peak 7(7q31 1) | 0 (0%) | 13 |
0.553 (1.00) |
| Del Peak 8(9p21 3) | 0 (0%) | 3 |
0.518 (1.00) |
| Del Peak 9(10p11 21) | 0 (0%) | 13 |
0.0304 (0.76) |
| Del Peak 10(10q23 31) | 0 (0%) | 10 |
0.7 (1.00) |
| Del Peak 11(13q14 2) | 0 (0%) | 9 |
0.0388 (0.932) |
| Del Peak 12(15q22 2) | 0 (0%) | 15 |
0.628 (1.00) |
| Del Peak 13(16q23 1) | 0 (0%) | 13 |
0.457 (1.00) |
| Del Peak 15(19q13 31) | 0 (0%) | 12 |
1 (1.00) |
| Del Peak 16(Xp11 3) | 0 (0%) | 11 |
0.835 (1.00) |
P value = 0.00125 (Fisher's exact test), Q value = 0.034
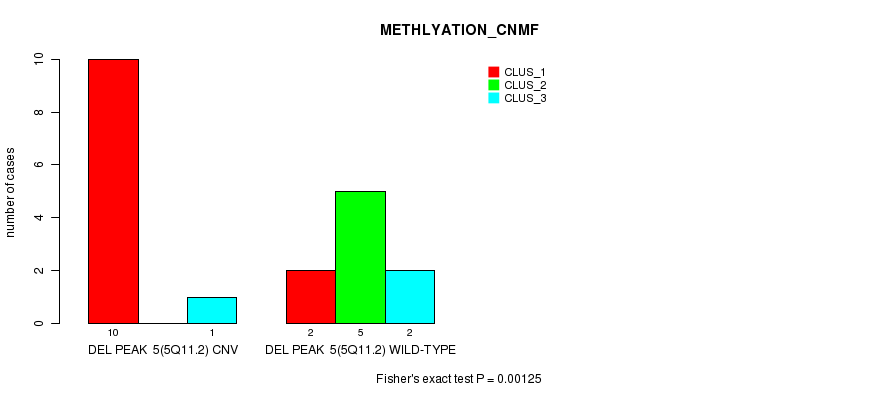
Table S1. Gene #17: 'Del Peak 5(5q11.2)' versus Molecular Subtype #1: 'METHLYATION_CNMF'
| nPatients | CLUS_1 | CLUS_2 | CLUS_3 |
|---|---|---|---|
| ALL | 12 | 5 | 3 |
| DEL PEAK 5(5Q11.2) CNV | 10 | 0 | 1 |
| DEL PEAK 5(5Q11.2) WILD-TYPE | 2 | 5 | 2 |
Figure S1. Get High-res Image Gene #17: 'Del Peak 5(5q11.2)' versus Molecular Subtype #1: 'METHLYATION_CNMF'
-
Copy number data file = All Lesions File (all_lesions.conf_##.txt, where ## is the confidence level). The all lesions file is from GISTIC pipeline and summarizes the results from the GISTIC run. It contains data about the significant regions of amplification and deletion as well as which samples are amplified or deleted in each of these regions. The identified regions are listed down the first column, and the samples are listed across the first row, starting in column 10.
-
Molecular subtype file = ESCA-TP.transferedmergedcluster.txt
-
Number of patients = 20
-
Number of copy number variation regions = 27
-
Number of molecular subtypes = 1: 'METHLYATION_CNMF'
-
Exclude regions that fewer than K tumors have alterations, K = 3
For binary or multi-class clinical features (nominal or ordinal), two-tailed Fisher's exact tests (Fisher 1922) were used to estimate the P values using the 'fisher.test' function in R
For multiple hypothesis correction, Q value is the False Discovery Rate (FDR) analogue of the P value (Benjamini and Hochberg 1995), defined as the minimum FDR at which the test may be called significant. We used the 'Benjamini and Hochberg' method of 'p.adjust' function in R to convert P values into Q values.
This is an experimental feature. The full results of the analysis summarized in this report can be downloaded from the TCGA Data Coordination Center.