A TCGA sample is profiled to detect the copy number variations and expressions of genes. This pipeline attempts to correlate copy number and expression data of genes across samples to determine if the copy number variations also result in differential expressions. This report contains the calculated correlation coefficients based on measurements of genomic copy number (log2) values and intensity of the expressions of the corresponding feature across patients. High positive/low negative correlation coefficients indicate that genomic alterations result in differences in the expressions of mRNA the genomic regions transcribe.
The correlation coefficients in 10, 20, 30, 40, 50, 60, 70, 80, 90 percentiles are -0.09319, -0.01, 0.05333, 0.1106, 0.16705, 0.2236, 0.2863, 0.35788, 0.4516, respectively.
Number of genes and samples used for the calculation are shown in Table 1. Figure 1 shows the distribution of calculated correlation coefficients and quantile-quantile plot of the calculated correlation coefficients against a normal distribution. Table 2 shows the top 20 features ordered by the value of correlation coefficients.
Table 1. Counts of mRNA and number of samples in copy number and expression data sets and common to both
| Category | Copy number | Expression | Common |
|---|---|---|---|
| Sample | 504 | 54 | 53 |
| Genes | 24174 | 17815 | 15702 |
Figure 1. Summary figures. Left: histogram showing the distribution of the calculated correlations across samples for all Genes. Right: QQ plot of the calculated correlations across samples. The QQ plot is used to plot the quantiles of the calculated correlation coefficients against that derived from a normal distribution. Points deviating from the blue line indicate deviation from normality.
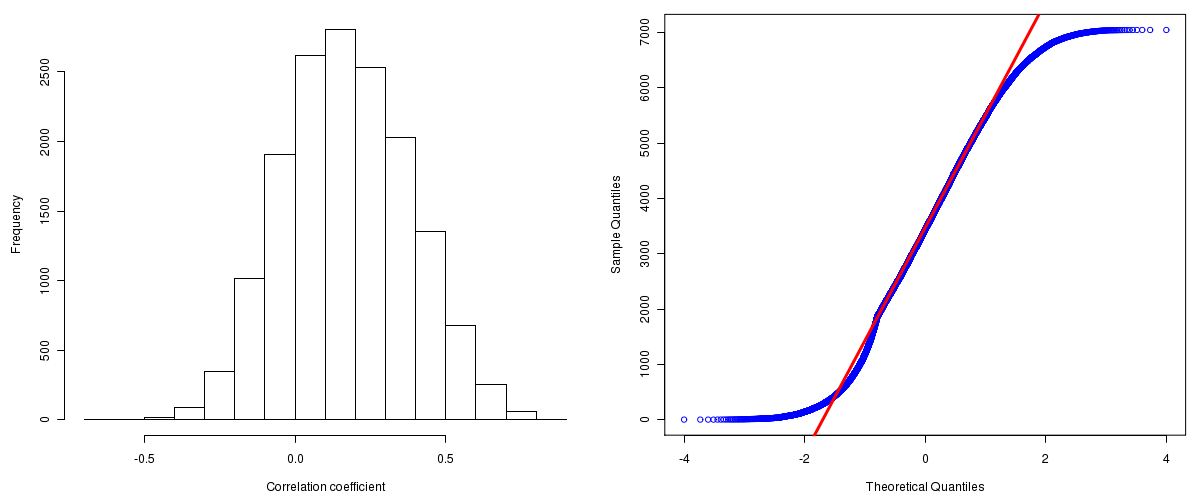
Table 2. Get Full Table Top 20 features (defined by the feature column) ranked by correlation coefficients
| feature | r | p-value | q-value | chrom | start | end | geneid |
|---|---|---|---|---|---|---|---|
| C19orf12 | 0.8565 | 4.44089209850063e-16 | 3.52550004835896e-12 | 83636 | 19q12 | 0.003 | -0.079 |
| POP4 | 0.8257 | 2.79776202205539e-14 | 1.11053251523307e-10 | 10775 | 19q12 | 0.003 | -0.079 |
| SAP30BP | 0.7963 | 1.01518793371724e-12 | 2.02892527783058e-09 | 29115 | 17q25.1 | 0.009 | -0.032 |
| EIF4A3 | 0.7962 | 1.02229336107484e-12 | 2.02892527783058e-09 | 9775 | 17q25.3 | 0.009 | -0.032 |
| ERBB2 | 0.7903 | 1.96154203990773e-12 | 3.1144267427203e-09 | 2064 | 17q12 | 0.009 | -0.032 |
| POFUT1 | 0.7874 | 2.69606559299973e-12 | 3.56721846559787e-09 | 23509 | 20q11.21 | 0.006 | 0.333 |
| RAF1 | 0.784 | 3.85003140479512e-12 | 4.36633180989257e-09 | 5894 | 3p25.2 | -0.002 | 0.042 |
| UBA52 | 0.7811 | 5.23714405176179e-12 | 5.19702775878715e-09 | 7311 | 19p13.11 | 0.003 | -0.079 |
| WHSC2 | 0.7788 | 6.59650112311283e-12 | 5.81864196870266e-09 | 7469 | 4p16.3 | -0.001 | -0.418 |
| ZNF764 | 0.7709 | 1.45046197275178e-11 | 1.06204086456792e-08 | 92595 | 16p11.2 | -0.003 | -0.023 |
| STARD3 | 0.7708 | 1.47157841468015e-11 | 1.06204086456792e-08 | 10948 | 17q12 | 0.009 | -0.032 |
| PSMD8 | 0.7687 | 1.81072934424265e-11 | 1.19790615809823e-08 | 5714 | 19q13.2 | 0.003 | -0.079 |
| POLR2I | 0.7673 | 2.07385220107881e-11 | 1.26644097506396e-08 | 5438 | 19q13.12 | 0.003 | -0.079 |
| HDAC11 | 0.7644 | 2.73929767757863e-11 | 1.55332273023536e-08 | 79885 | 3p25.1 | -0.002 | 0.042 |
| PSMB4 | 0.7606 | 3.89031029612852e-11 | 2.05893903490894e-08 | 5692 | 1q21.3 | 0.002 | 0.240 |
| RPL32 | 0.7561 | 5.91722226772617e-11 | 2.93594830277213e-08 | 6161 | 3p25.2 | -0.002 | 0.042 |
| ASXL1 | 0.7508 | 9.51763112766457e-11 | 4.20667304586044e-08 | 171023 | 20q11.21 | 0.006 | 0.333 |
| PREP | 0.7503 | 9.97686377957052e-11 | 4.20667304586044e-08 | 5550 | 6q21 | -0.001 | -0.370 |
| EDF1 | 0.7502 | 1.00679686809713e-10 | 4.20667304586044e-08 | 8721 | 9q34.3 | -0.002 | -0.003 |
| LSM14A | 0.7482 | 1.19491083694356e-10 | 4.4372103858648e-08 | 26065 | 19q13.11 | 0.003 | -0.079 |
Gene level (TCGA Level III) expression data and copy number data of the corresponding loci derived by using the CNTools package of Bioconductor were used for the calculations. Pearson correlation coefficients were calculated for each pair of genes shared by the two data sets across all the samples that were common.
Pairwise correlations between the log2 copy numbers and expressions of each gene across samples were calculated using Pearson correlation.
In addition to the links below, the full results of the analysis summarized in this report can also be downloaded programmatically using firehose_get, or interactively from either the Broad GDAC website or TCGA Data Coordination Center Portal.