This pipeline computes the correlation between cancer subtypes identified by different molecular patterns and selected clinical features.
Testing the association between subtypes identified by 8 different clustering approaches and 3 clinical features across 61 patients, 2 significant findings detected with P value < 0.05 and Q value < 0.25.
-
5 subtypes identified in current cancer cohort by 'Copy Number Ratio CNMF subtypes'. These subtypes correlate to 'GENDER'.
-
3 subtypes identified in current cancer cohort by 'METHLYATION CNMF'. These subtypes do not correlate to any clinical features.
-
CNMF clustering analysis on sequencing-based mRNA expression data identified 4 subtypes that do not correlate to any clinical features.
-
Consensus hierarchical clustering analysis on sequencing-based mRNA expression data identified 4 subtypes that do not correlate to any clinical features.
-
3 subtypes identified in current cancer cohort by 'MIRSEQ CNMF'. These subtypes do not correlate to any clinical features.
-
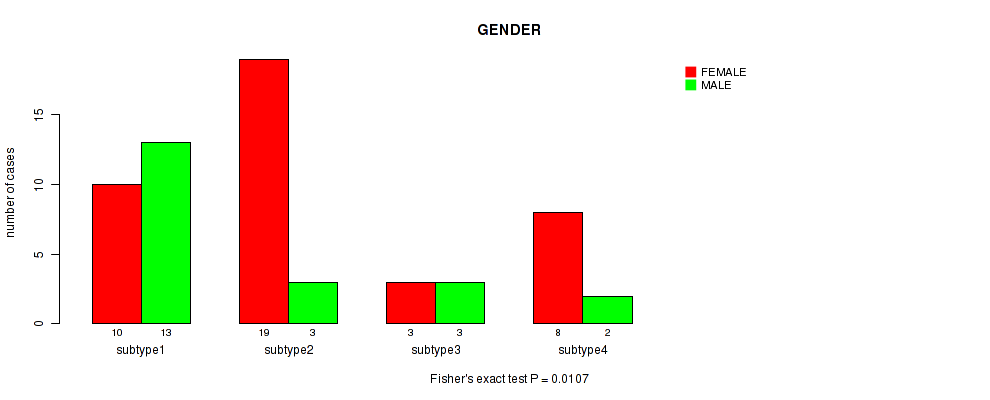
4 subtypes identified in current cancer cohort by 'MIRSEQ CHIERARCHICAL'. These subtypes correlate to 'GENDER'.
-
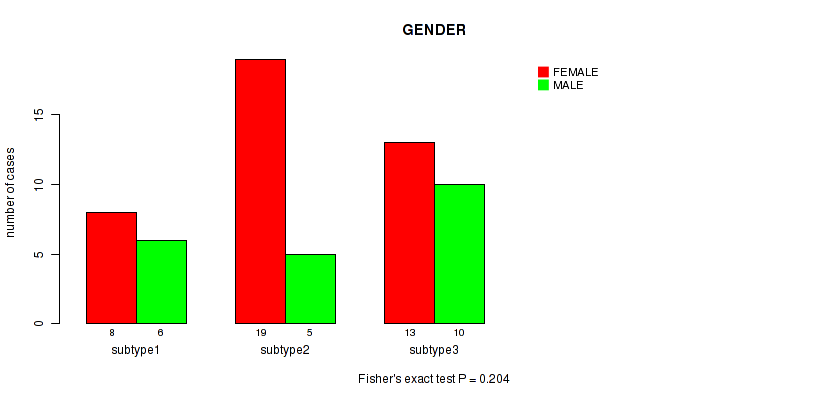
3 subtypes identified in current cancer cohort by 'MIRseq Mature CNMF subtypes'. These subtypes do not correlate to any clinical features.
-
3 subtypes identified in current cancer cohort by 'MIRseq Mature cHierClus subtypes'. These subtypes do not correlate to any clinical features.
Table 1. Get Full Table Overview of the association between subtypes identified by 8 different clustering approaches and 3 clinical features. Shown in the table are P values (Q values). Thresholded by P value < 0.05 and Q value < 0.25, 2 significant findings detected.
|
Clinical Features |
AGE | GENDER | RACE |
| Statistical Tests | Kruskal-Wallis (anova) | Fisher's exact test | Fisher's exact test |
| Copy Number Ratio CNMF subtypes |
0.603 (1.00) |
0.00732 (0.176) |
0.89 (1.00) |
| METHLYATION CNMF |
0.673 (1.00) |
0.129 (1.00) |
0.388 (1.00) |
| RNAseq CNMF subtypes |
0.546 (1.00) |
0.0382 (0.802) |
0.214 (1.00) |
| RNAseq cHierClus subtypes |
0.544 (1.00) |
0.0619 (1.00) |
0.445 (1.00) |
| MIRSEQ CNMF |
0.616 (1.00) |
0.145 (1.00) |
0.489 (1.00) |
| MIRSEQ CHIERARCHICAL |
0.513 (1.00) |
0.0107 (0.245) |
0.543 (1.00) |
| MIRseq Mature CNMF subtypes |
0.239 (1.00) |
0.204 (1.00) |
0.224 (1.00) |
| MIRseq Mature cHierClus subtypes |
0.338 (1.00) |
0.0186 (0.409) |
0.409 (1.00) |
Table S1. Description of clustering approach #1: 'Copy Number Ratio CNMF subtypes'
| Cluster Labels | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| Number of samples | 4 | 7 | 21 | 18 | 7 |
P value = 0.603 (Kruskal-Wallis (anova)), Q value = 1
Table S2. Clustering Approach #1: 'Copy Number Ratio CNMF subtypes' versus Clinical Feature #1: 'AGE'
| nPatients | Mean (Std.Dev) | |
|---|---|---|
| ALL | 57 | 49.2 (13.8) |
| subtype1 | 4 | 43.8 (18.1) |
| subtype2 | 7 | 52.9 (12.5) |
| subtype3 | 21 | 52.0 (14.5) |
| subtype4 | 18 | 47.4 (14.4) |
| subtype5 | 7 | 45.0 (9.4) |
Figure S1. Get High-res Image Clustering Approach #1: 'Copy Number Ratio CNMF subtypes' versus Clinical Feature #1: 'AGE'
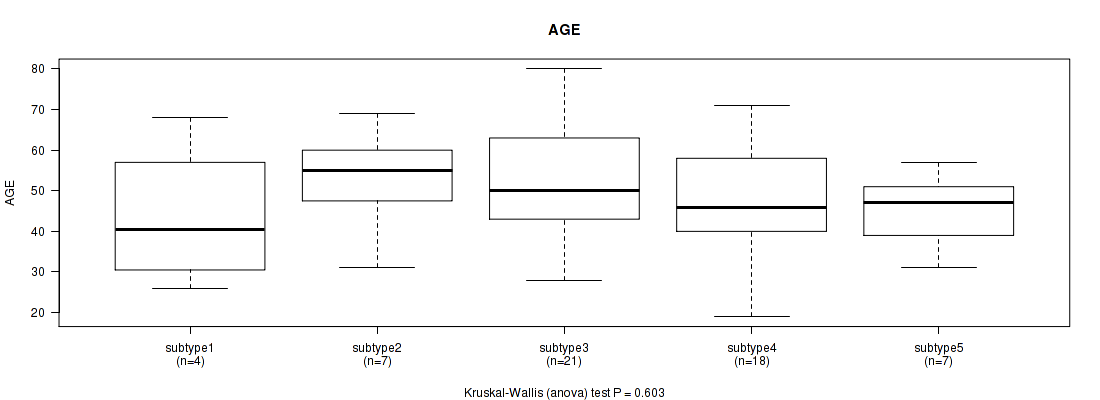
P value = 0.00732 (Fisher's exact test), Q value = 0.18
Table S3. Clustering Approach #1: 'Copy Number Ratio CNMF subtypes' versus Clinical Feature #2: 'GENDER'
| nPatients | FEMALE | MALE |
|---|---|---|
| ALL | 37 | 20 |
| subtype1 | 3 | 1 |
| subtype2 | 2 | 5 |
| subtype3 | 19 | 2 |
| subtype4 | 9 | 9 |
| subtype5 | 4 | 3 |
Figure S2. Get High-res Image Clustering Approach #1: 'Copy Number Ratio CNMF subtypes' versus Clinical Feature #2: 'GENDER'
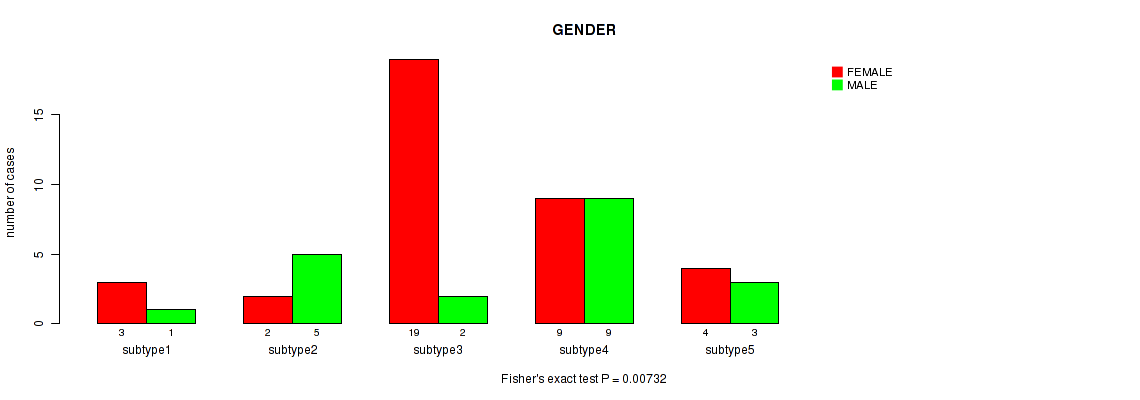
P value = 0.89 (Fisher's exact test), Q value = 1
Table S4. Clustering Approach #1: 'Copy Number Ratio CNMF subtypes' versus Clinical Feature #3: 'RACE'
| nPatients | AMERICAN INDIAN OR ALASKA NATIVE | ASIAN | BLACK OR AFRICAN AMERICAN | WHITE |
|---|---|---|---|---|
| ALL | 1 | 2 | 7 | 45 |
| subtype1 | 0 | 0 | 0 | 3 |
| subtype2 | 0 | 0 | 1 | 6 |
| subtype3 | 1 | 1 | 3 | 15 |
| subtype4 | 0 | 0 | 3 | 15 |
| subtype5 | 0 | 1 | 0 | 6 |
Figure S3. Get High-res Image Clustering Approach #1: 'Copy Number Ratio CNMF subtypes' versus Clinical Feature #3: 'RACE'
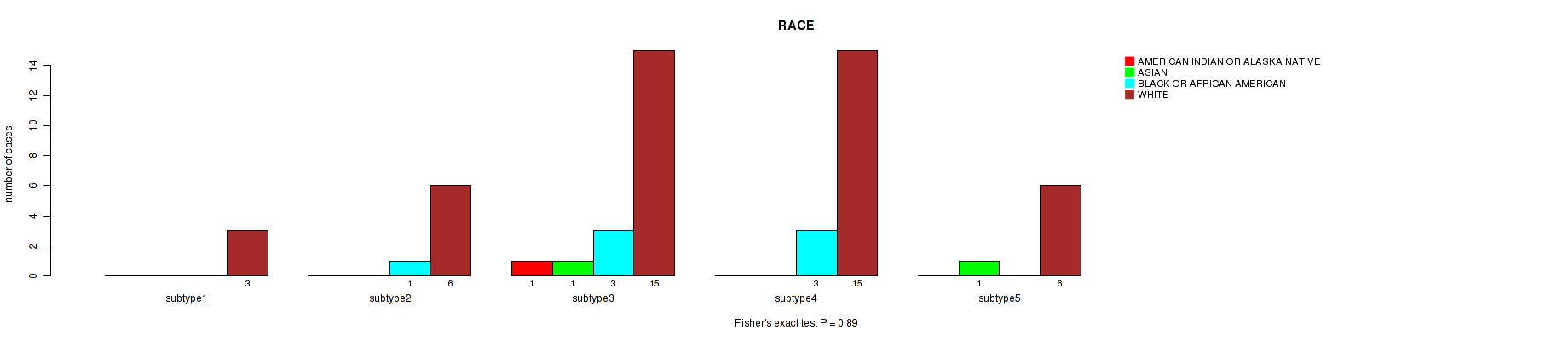
Table S5. Description of clustering approach #2: 'METHLYATION CNMF'
| Cluster Labels | 1 | 2 | 3 |
|---|---|---|---|
| Number of samples | 14 | 28 | 19 |
P value = 0.673 (Kruskal-Wallis (anova)), Q value = 1
Table S6. Clustering Approach #2: 'METHLYATION CNMF' versus Clinical Feature #1: 'AGE'
| nPatients | Mean (Std.Dev) | |
|---|---|---|
| ALL | 61 | 49.3 (13.8) |
| subtype1 | 14 | 46.2 (13.7) |
| subtype2 | 28 | 51.2 (14.0) |
| subtype3 | 19 | 48.8 (13.8) |
Figure S4. Get High-res Image Clustering Approach #2: 'METHLYATION CNMF' versus Clinical Feature #1: 'AGE'
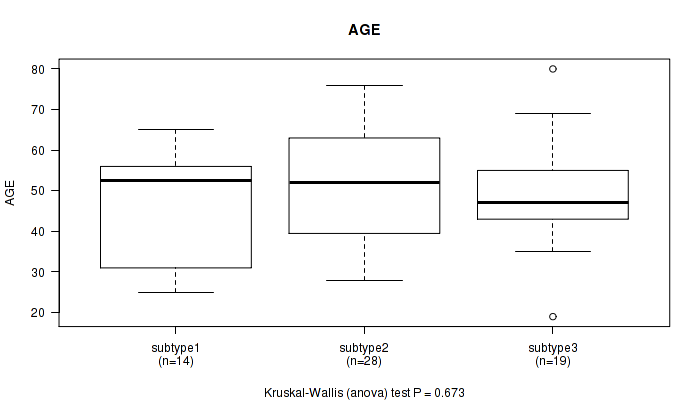
P value = 0.129 (Fisher's exact test), Q value = 1
Table S7. Clustering Approach #2: 'METHLYATION CNMF' versus Clinical Feature #2: 'GENDER'
| nPatients | FEMALE | MALE |
|---|---|---|
| ALL | 40 | 21 |
| subtype1 | 7 | 7 |
| subtype2 | 22 | 6 |
| subtype3 | 11 | 8 |
Figure S5. Get High-res Image Clustering Approach #2: 'METHLYATION CNMF' versus Clinical Feature #2: 'GENDER'
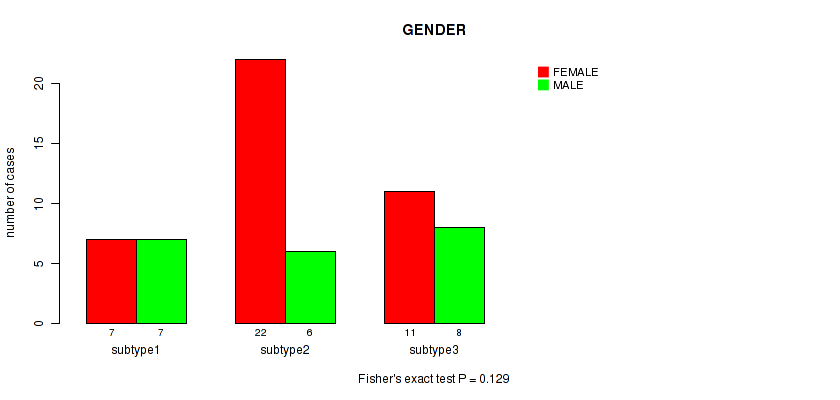
P value = 0.388 (Fisher's exact test), Q value = 1
Table S8. Clustering Approach #2: 'METHLYATION CNMF' versus Clinical Feature #3: 'RACE'
| nPatients | AMERICAN INDIAN OR ALASKA NATIVE | ASIAN | BLACK OR AFRICAN AMERICAN | WHITE |
|---|---|---|---|---|
| ALL | 1 | 3 | 7 | 48 |
| subtype1 | 0 | 1 | 1 | 11 |
| subtype2 | 1 | 0 | 5 | 21 |
| subtype3 | 0 | 2 | 1 | 16 |
Figure S6. Get High-res Image Clustering Approach #2: 'METHLYATION CNMF' versus Clinical Feature #3: 'RACE'
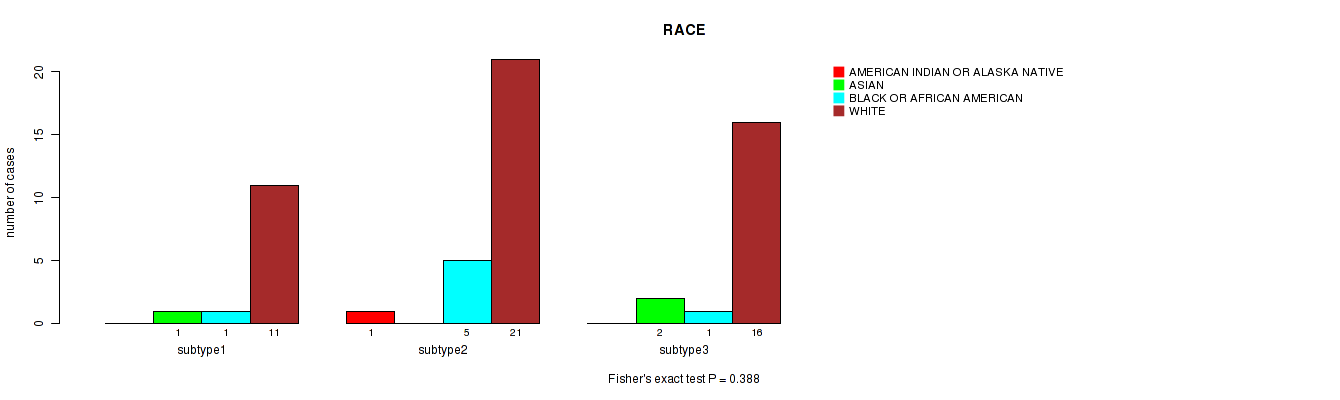
Table S9. Description of clustering approach #3: 'RNAseq CNMF subtypes'
| Cluster Labels | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| Number of samples | 13 | 21 | 18 | 9 |
P value = 0.546 (Kruskal-Wallis (anova)), Q value = 1
Table S10. Clustering Approach #3: 'RNAseq CNMF subtypes' versus Clinical Feature #1: 'AGE'
| nPatients | Mean (Std.Dev) | |
|---|---|---|
| ALL | 61 | 49.3 (13.8) |
| subtype1 | 13 | 48.3 (14.2) |
| subtype2 | 21 | 50.7 (12.8) |
| subtype3 | 18 | 46.0 (13.4) |
| subtype4 | 9 | 54.2 (16.5) |
Figure S7. Get High-res Image Clustering Approach #3: 'RNAseq CNMF subtypes' versus Clinical Feature #1: 'AGE'
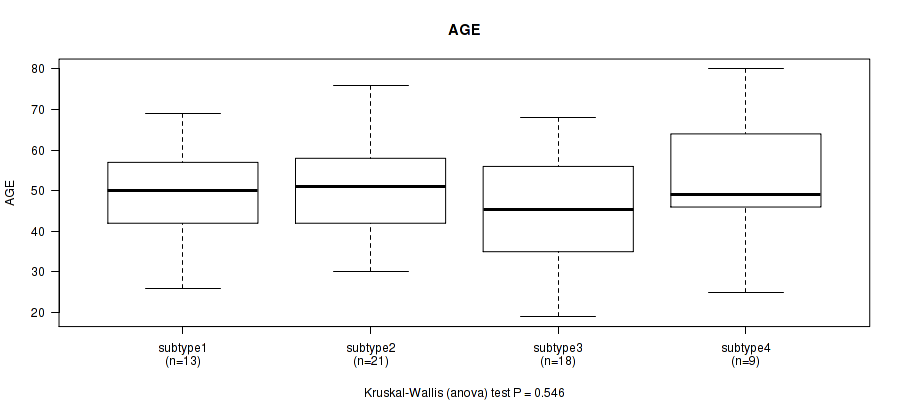
P value = 0.0382 (Fisher's exact test), Q value = 0.8
Table S11. Clustering Approach #3: 'RNAseq CNMF subtypes' versus Clinical Feature #2: 'GENDER'
| nPatients | FEMALE | MALE |
|---|---|---|
| ALL | 40 | 21 |
| subtype1 | 10 | 3 |
| subtype2 | 15 | 6 |
| subtype3 | 7 | 11 |
| subtype4 | 8 | 1 |
Figure S8. Get High-res Image Clustering Approach #3: 'RNAseq CNMF subtypes' versus Clinical Feature #2: 'GENDER'
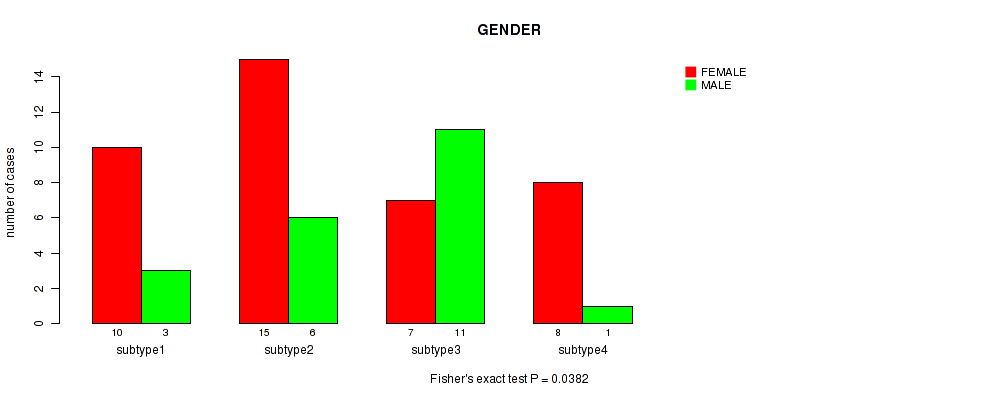
P value = 0.214 (Fisher's exact test), Q value = 1
Table S12. Clustering Approach #3: 'RNAseq CNMF subtypes' versus Clinical Feature #3: 'RACE'
| nPatients | AMERICAN INDIAN OR ALASKA NATIVE | ASIAN | BLACK OR AFRICAN AMERICAN | WHITE |
|---|---|---|---|---|
| ALL | 1 | 3 | 7 | 48 |
| subtype1 | 0 | 1 | 2 | 8 |
| subtype2 | 1 | 0 | 3 | 17 |
| subtype3 | 0 | 1 | 0 | 17 |
| subtype4 | 0 | 1 | 2 | 6 |
Figure S9. Get High-res Image Clustering Approach #3: 'RNAseq CNMF subtypes' versus Clinical Feature #3: 'RACE'
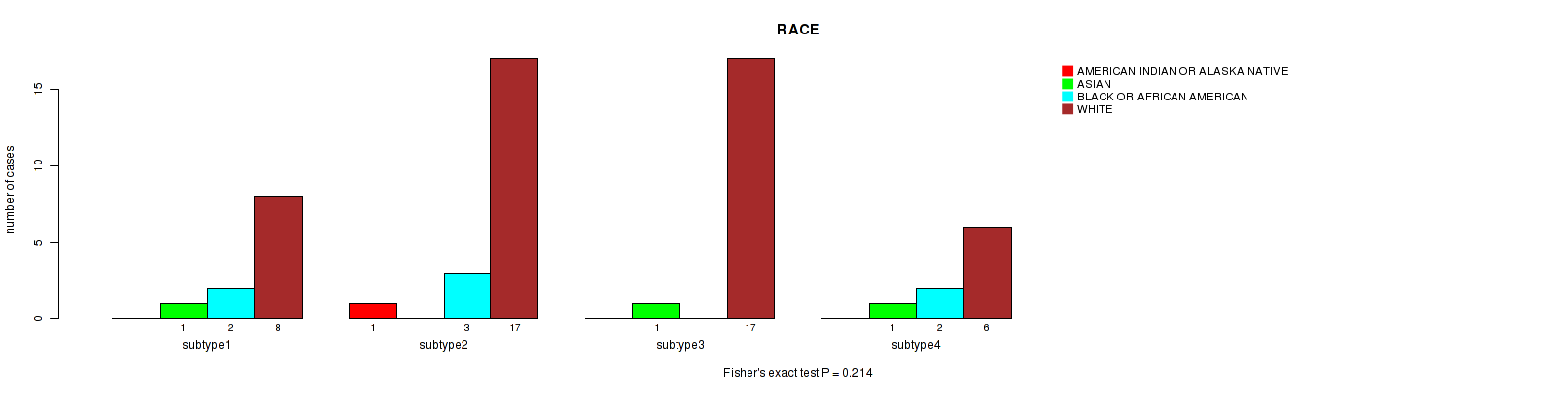
Table S13. Description of clustering approach #4: 'RNAseq cHierClus subtypes'
| Cluster Labels | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| Number of samples | 14 | 25 | 13 | 9 |
P value = 0.544 (Kruskal-Wallis (anova)), Q value = 1
Table S14. Clustering Approach #4: 'RNAseq cHierClus subtypes' versus Clinical Feature #1: 'AGE'
| nPatients | Mean (Std.Dev) | |
|---|---|---|
| ALL | 61 | 49.3 (13.8) |
| subtype1 | 14 | 50.1 (11.7) |
| subtype2 | 25 | 50.4 (13.5) |
| subtype3 | 13 | 43.8 (14.6) |
| subtype4 | 9 | 53.1 (16.2) |
Figure S10. Get High-res Image Clustering Approach #4: 'RNAseq cHierClus subtypes' versus Clinical Feature #1: 'AGE'
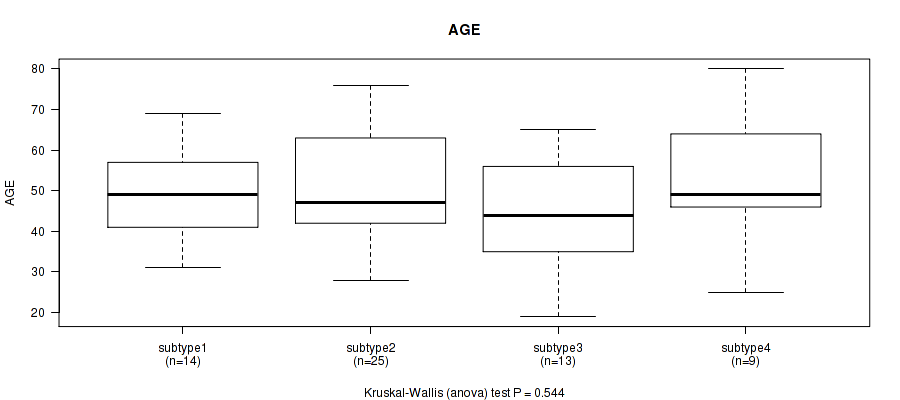
P value = 0.0619 (Fisher's exact test), Q value = 1
Table S15. Clustering Approach #4: 'RNAseq cHierClus subtypes' versus Clinical Feature #2: 'GENDER'
| nPatients | FEMALE | MALE |
|---|---|---|
| ALL | 40 | 21 |
| subtype1 | 8 | 6 |
| subtype2 | 20 | 5 |
| subtype3 | 5 | 8 |
| subtype4 | 7 | 2 |
Figure S11. Get High-res Image Clustering Approach #4: 'RNAseq cHierClus subtypes' versus Clinical Feature #2: 'GENDER'
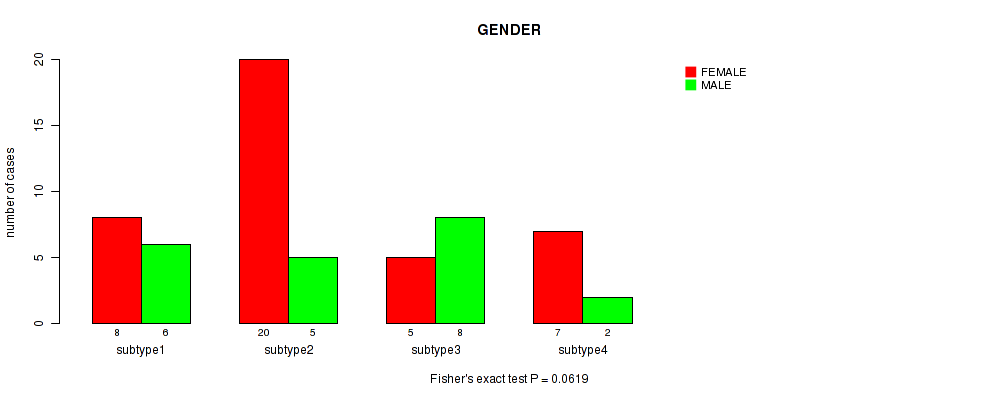
P value = 0.445 (Fisher's exact test), Q value = 1
Table S16. Clustering Approach #4: 'RNAseq cHierClus subtypes' versus Clinical Feature #3: 'RACE'
| nPatients | AMERICAN INDIAN OR ALASKA NATIVE | ASIAN | BLACK OR AFRICAN AMERICAN | WHITE |
|---|---|---|---|---|
| ALL | 1 | 3 | 7 | 48 |
| subtype1 | 0 | 1 | 1 | 12 |
| subtype2 | 1 | 0 | 5 | 18 |
| subtype3 | 0 | 1 | 0 | 11 |
| subtype4 | 0 | 1 | 1 | 7 |
Figure S12. Get High-res Image Clustering Approach #4: 'RNAseq cHierClus subtypes' versus Clinical Feature #3: 'RACE'
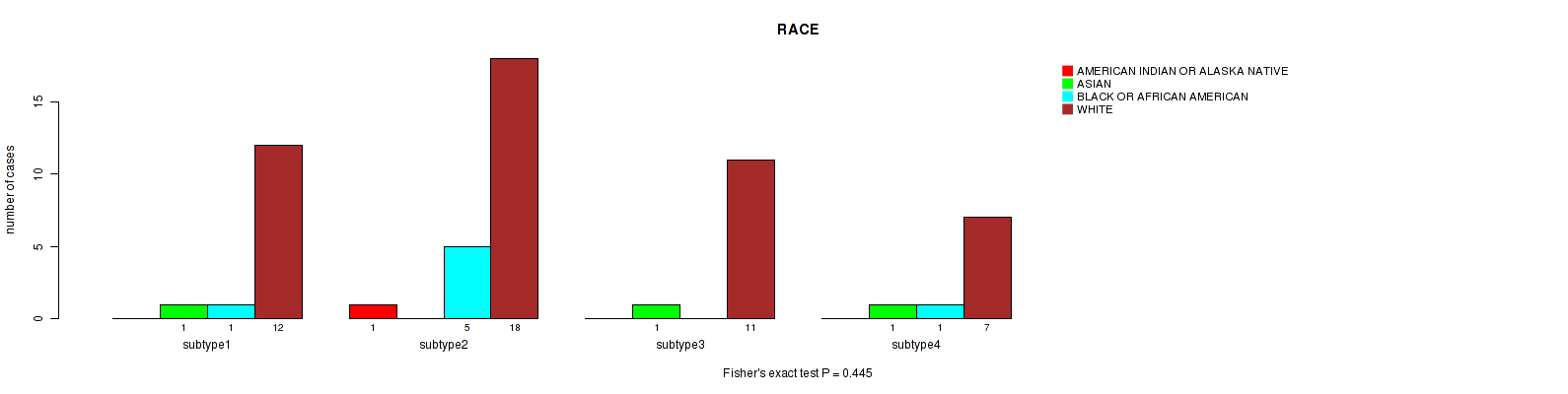
Table S17. Description of clustering approach #5: 'MIRSEQ CNMF'
| Cluster Labels | 1 | 2 | 3 |
|---|---|---|---|
| Number of samples | 25 | 20 | 16 |
P value = 0.616 (Kruskal-Wallis (anova)), Q value = 1
Table S18. Clustering Approach #5: 'MIRSEQ CNMF' versus Clinical Feature #1: 'AGE'
| nPatients | Mean (Std.Dev) | |
|---|---|---|
| ALL | 61 | 49.3 (13.8) |
| subtype1 | 25 | 46.9 (13.7) |
| subtype2 | 20 | 50.1 (13.6) |
| subtype3 | 16 | 52.1 (14.3) |
Figure S13. Get High-res Image Clustering Approach #5: 'MIRSEQ CNMF' versus Clinical Feature #1: 'AGE'
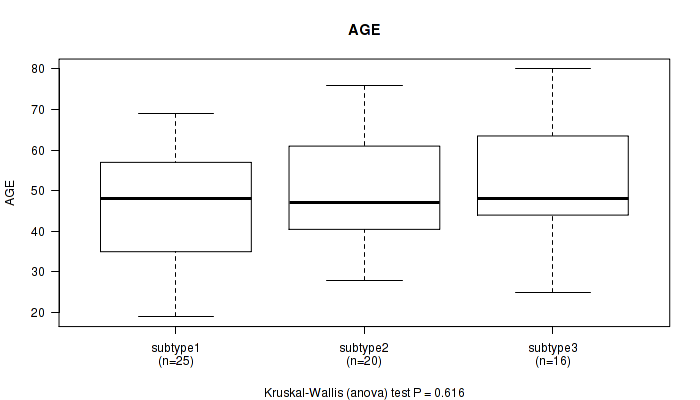
P value = 0.145 (Fisher's exact test), Q value = 1
Table S19. Clustering Approach #5: 'MIRSEQ CNMF' versus Clinical Feature #2: 'GENDER'
| nPatients | FEMALE | MALE |
|---|---|---|
| ALL | 40 | 21 |
| subtype1 | 13 | 12 |
| subtype2 | 16 | 4 |
| subtype3 | 11 | 5 |
Figure S14. Get High-res Image Clustering Approach #5: 'MIRSEQ CNMF' versus Clinical Feature #2: 'GENDER'
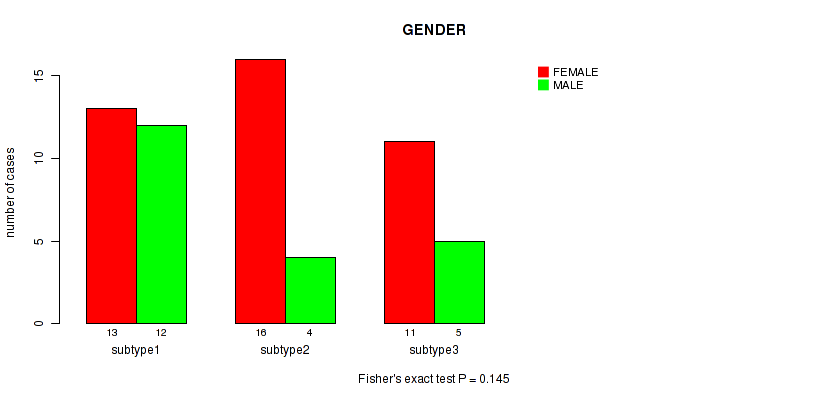
P value = 0.489 (Fisher's exact test), Q value = 1
Table S20. Clustering Approach #5: 'MIRSEQ CNMF' versus Clinical Feature #3: 'RACE'
| nPatients | AMERICAN INDIAN OR ALASKA NATIVE | ASIAN | BLACK OR AFRICAN AMERICAN | WHITE |
|---|---|---|---|---|
| ALL | 1 | 3 | 7 | 48 |
| subtype1 | 1 | 2 | 1 | 20 |
| subtype2 | 0 | 0 | 3 | 16 |
| subtype3 | 0 | 1 | 3 | 12 |
Figure S15. Get High-res Image Clustering Approach #5: 'MIRSEQ CNMF' versus Clinical Feature #3: 'RACE'
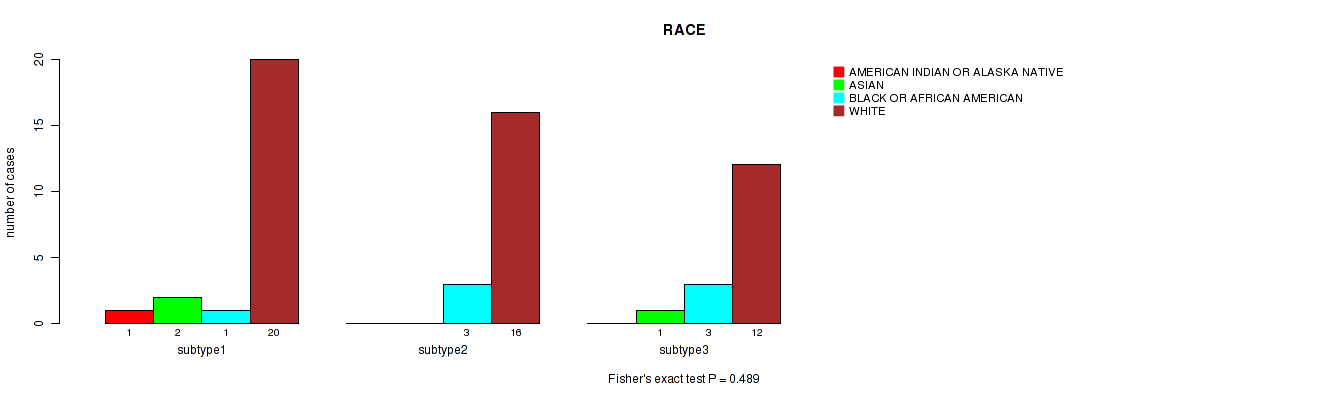
Table S21. Description of clustering approach #6: 'MIRSEQ CHIERARCHICAL'
| Cluster Labels | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| Number of samples | 23 | 22 | 6 | 10 |
P value = 0.513 (Kruskal-Wallis (anova)), Q value = 1
Table S22. Clustering Approach #6: 'MIRSEQ CHIERARCHICAL' versus Clinical Feature #1: 'AGE'
| nPatients | Mean (Std.Dev) | |
|---|---|---|
| ALL | 61 | 49.3 (13.8) |
| subtype1 | 23 | 46.3 (12.7) |
| subtype2 | 22 | 50.3 (14.4) |
| subtype3 | 6 | 48.3 (12.2) |
| subtype4 | 10 | 54.6 (15.6) |
Figure S16. Get High-res Image Clustering Approach #6: 'MIRSEQ CHIERARCHICAL' versus Clinical Feature #1: 'AGE'
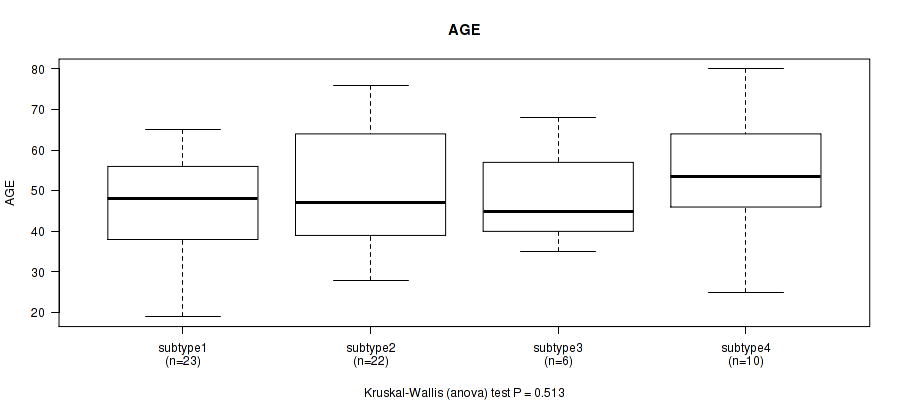
P value = 0.0107 (Fisher's exact test), Q value = 0.25
Table S23. Clustering Approach #6: 'MIRSEQ CHIERARCHICAL' versus Clinical Feature #2: 'GENDER'
| nPatients | FEMALE | MALE |
|---|---|---|
| ALL | 40 | 21 |
| subtype1 | 10 | 13 |
| subtype2 | 19 | 3 |
| subtype3 | 3 | 3 |
| subtype4 | 8 | 2 |
Figure S17. Get High-res Image Clustering Approach #6: 'MIRSEQ CHIERARCHICAL' versus Clinical Feature #2: 'GENDER'
P value = 0.543 (Fisher's exact test), Q value = 1
Table S24. Clustering Approach #6: 'MIRSEQ CHIERARCHICAL' versus Clinical Feature #3: 'RACE'
| nPatients | AMERICAN INDIAN OR ALASKA NATIVE | ASIAN | BLACK OR AFRICAN AMERICAN | WHITE |
|---|---|---|---|---|
| ALL | 1 | 3 | 7 | 48 |
| subtype1 | 0 | 2 | 1 | 19 |
| subtype2 | 1 | 0 | 3 | 17 |
| subtype3 | 0 | 0 | 1 | 5 |
| subtype4 | 0 | 1 | 2 | 7 |
Figure S18. Get High-res Image Clustering Approach #6: 'MIRSEQ CHIERARCHICAL' versus Clinical Feature #3: 'RACE'
Table S25. Description of clustering approach #7: 'MIRseq Mature CNMF subtypes'
| Cluster Labels | 1 | 2 | 3 |
|---|---|---|---|
| Number of samples | 14 | 24 | 23 |
P value = 0.239 (Kruskal-Wallis (anova)), Q value = 1
Table S26. Clustering Approach #7: 'MIRseq Mature CNMF subtypes' versus Clinical Feature #1: 'AGE'
| nPatients | Mean (Std.Dev) | |
|---|---|---|
| ALL | 61 | 49.3 (13.8) |
| subtype1 | 14 | 43.3 (15.8) |
| subtype2 | 24 | 52.0 (13.3) |
| subtype3 | 23 | 50.2 (12.3) |
Figure S19. Get High-res Image Clustering Approach #7: 'MIRseq Mature CNMF subtypes' versus Clinical Feature #1: 'AGE'
P value = 0.204 (Fisher's exact test), Q value = 1
Table S27. Clustering Approach #7: 'MIRseq Mature CNMF subtypes' versus Clinical Feature #2: 'GENDER'
| nPatients | FEMALE | MALE |
|---|---|---|
| ALL | 40 | 21 |
| subtype1 | 8 | 6 |
| subtype2 | 19 | 5 |
| subtype3 | 13 | 10 |
Figure S20. Get High-res Image Clustering Approach #7: 'MIRseq Mature CNMF subtypes' versus Clinical Feature #2: 'GENDER'
P value = 0.224 (Fisher's exact test), Q value = 1
Table S28. Clustering Approach #7: 'MIRseq Mature CNMF subtypes' versus Clinical Feature #3: 'RACE'
| nPatients | AMERICAN INDIAN OR ALASKA NATIVE | ASIAN | BLACK OR AFRICAN AMERICAN | WHITE |
|---|---|---|---|---|
| ALL | 1 | 3 | 7 | 48 |
| subtype1 | 0 | 1 | 0 | 12 |
| subtype2 | 0 | 0 | 5 | 18 |
| subtype3 | 1 | 2 | 2 | 18 |
Figure S21. Get High-res Image Clustering Approach #7: 'MIRseq Mature CNMF subtypes' versus Clinical Feature #3: 'RACE'
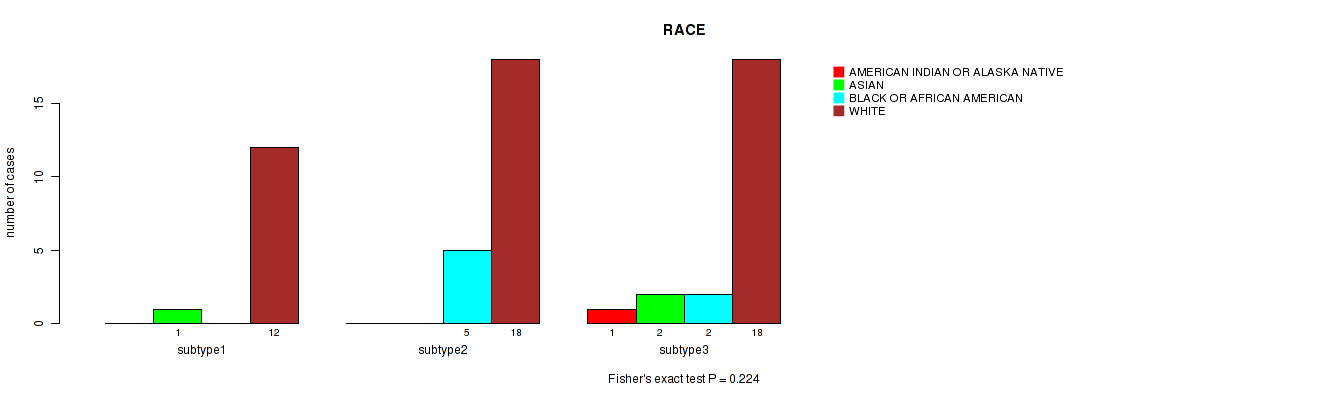
Table S29. Description of clustering approach #8: 'MIRseq Mature cHierClus subtypes'
| Cluster Labels | 1 | 2 | 3 |
|---|---|---|---|
| Number of samples | 24 | 21 | 16 |
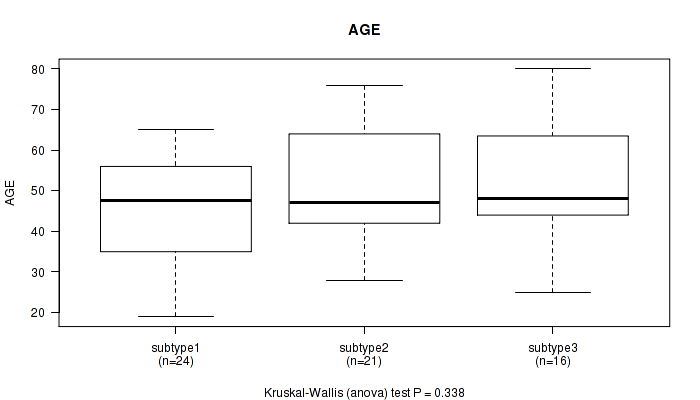
P value = 0.338 (Kruskal-Wallis (anova)), Q value = 1
Table S30. Clustering Approach #8: 'MIRseq Mature cHierClus subtypes' versus Clinical Feature #1: 'AGE'
| nPatients | Mean (Std.Dev) | |
|---|---|---|
| ALL | 61 | 49.3 (13.8) |
| subtype1 | 24 | 45.6 (12.8) |
| subtype2 | 21 | 51.3 (14.1) |
| subtype3 | 16 | 52.2 (14.3) |
Figure S22. Get High-res Image Clustering Approach #8: 'MIRseq Mature cHierClus subtypes' versus Clinical Feature #1: 'AGE'
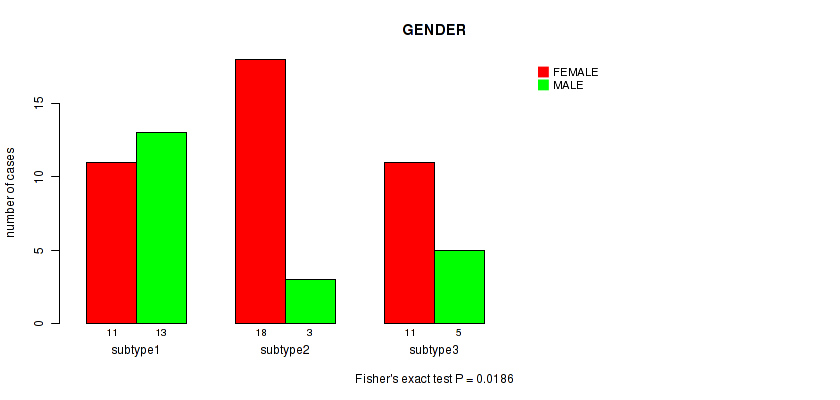
P value = 0.0186 (Fisher's exact test), Q value = 0.41
Table S31. Clustering Approach #8: 'MIRseq Mature cHierClus subtypes' versus Clinical Feature #2: 'GENDER'
| nPatients | FEMALE | MALE |
|---|---|---|
| ALL | 40 | 21 |
| subtype1 | 11 | 13 |
| subtype2 | 18 | 3 |
| subtype3 | 11 | 5 |
Figure S23. Get High-res Image Clustering Approach #8: 'MIRseq Mature cHierClus subtypes' versus Clinical Feature #2: 'GENDER'
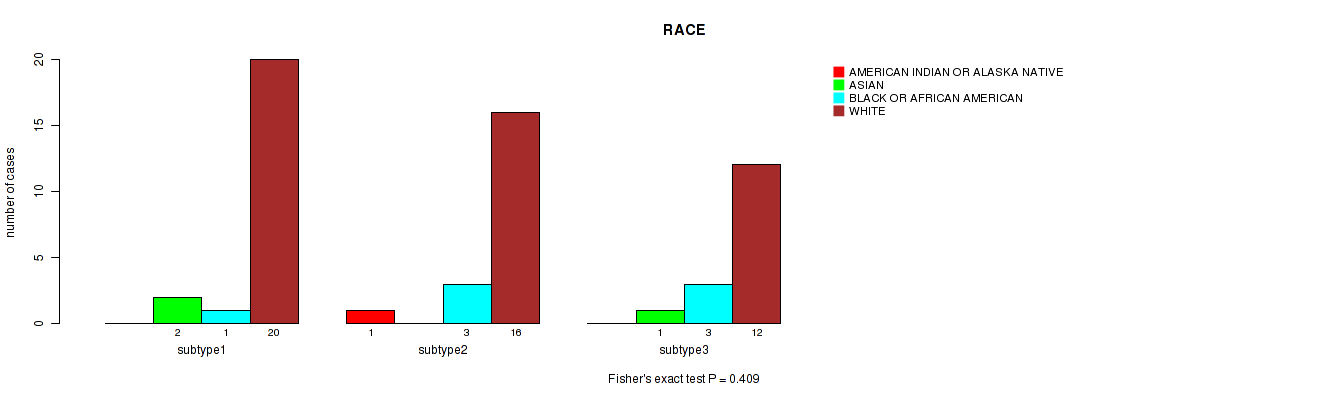
P value = 0.409 (Fisher's exact test), Q value = 1
Table S32. Clustering Approach #8: 'MIRseq Mature cHierClus subtypes' versus Clinical Feature #3: 'RACE'
| nPatients | AMERICAN INDIAN OR ALASKA NATIVE | ASIAN | BLACK OR AFRICAN AMERICAN | WHITE |
|---|---|---|---|---|
| ALL | 1 | 3 | 7 | 48 |
| subtype1 | 0 | 2 | 1 | 20 |
| subtype2 | 1 | 0 | 3 | 16 |
| subtype3 | 0 | 1 | 3 | 12 |
Figure S24. Get High-res Image Clustering Approach #8: 'MIRseq Mature cHierClus subtypes' versus Clinical Feature #3: 'RACE'
-
Cluster data file = PCPG-TP.mergedcluster.txt
-
Clinical data file = PCPG-TP.merged_data.txt
-
Number of patients = 61
-
Number of clustering approaches = 8
-
Number of selected clinical features = 3
-
Exclude small clusters that include fewer than K patients, K = 3
consensus non-negative matrix factorization clustering approach (Brunet et al. 2004)
Resampling-based clustering method (Monti et al. 2003)
For binary clinical features, two-tailed Fisher's exact tests (Fisher 1922) were used to estimate the P values using the 'fisher.test' function in R
For multiple hypothesis correction, Q value is the False Discovery Rate (FDR) analogue of the P value (Benjamini and Hochberg 1995), defined as the minimum FDR at which the test may be called significant. We used the 'Benjamini and Hochberg' method of 'p.adjust' function in R to convert P values into Q values.
In addition to the links below, the full results of the analysis summarized in this report can also be downloaded programmatically using firehose_get, or interactively from either the Broad GDAC website or TCGA Data Coordination Center Portal.