This report serves to describe the mutational landscape and properties of a given individual set, as well as rank genes and genesets according to mutational significance. MutSig 2CV v3.1 was used to generate the results found in this report.
-
Working with individual set: LUSC-TP
-
Number of patients in set: 178
The input for this pipeline is a set of individuals with the following files associated for each:
-
An annotated .maf file describing the mutations called for the respective individual, and their properties.
-
A .wig file that contains information about the coverage of the sample.
-
MAF used for this analysis:LUSC-TP.final_analysis_set.maf
-
Blacklist used for this analysis: pancan_mutation_blacklist.v14.hg19.txt
-
Significantly mutated genes (q ≤ 0.1): 16
The mutation spectrum is depicted in the lego plots below in which the 96 possible mutation types are subdivided into six large blocks, color-coded to reflect the base substitution type. Each large block is further subdivided into the 16 possible pairs of 5' and 3' neighbors, as listed in the 4x4 trinucleotide context legend. The height of each block corresponds to the mutation frequency for that kind of mutation (counts of mutations normalized by the base coverage in a given bin). The shape of the spectrum is a signature for dominant mutational mechanisms in different tumor types.
Figure 1. Get High-res Image SNV Mutation rate lego plot for entire set. Each bin is normalized by base coverage for that bin. Colors represent the six SNV types on the upper right. The three-base context for each mutation is labeled in the 4x4 legend on the lower right. The fractional breakdown of SNV counts is shown in the pie chart on the upper left. If this figure is blank, not enough information was provided in the MAF to generate it.
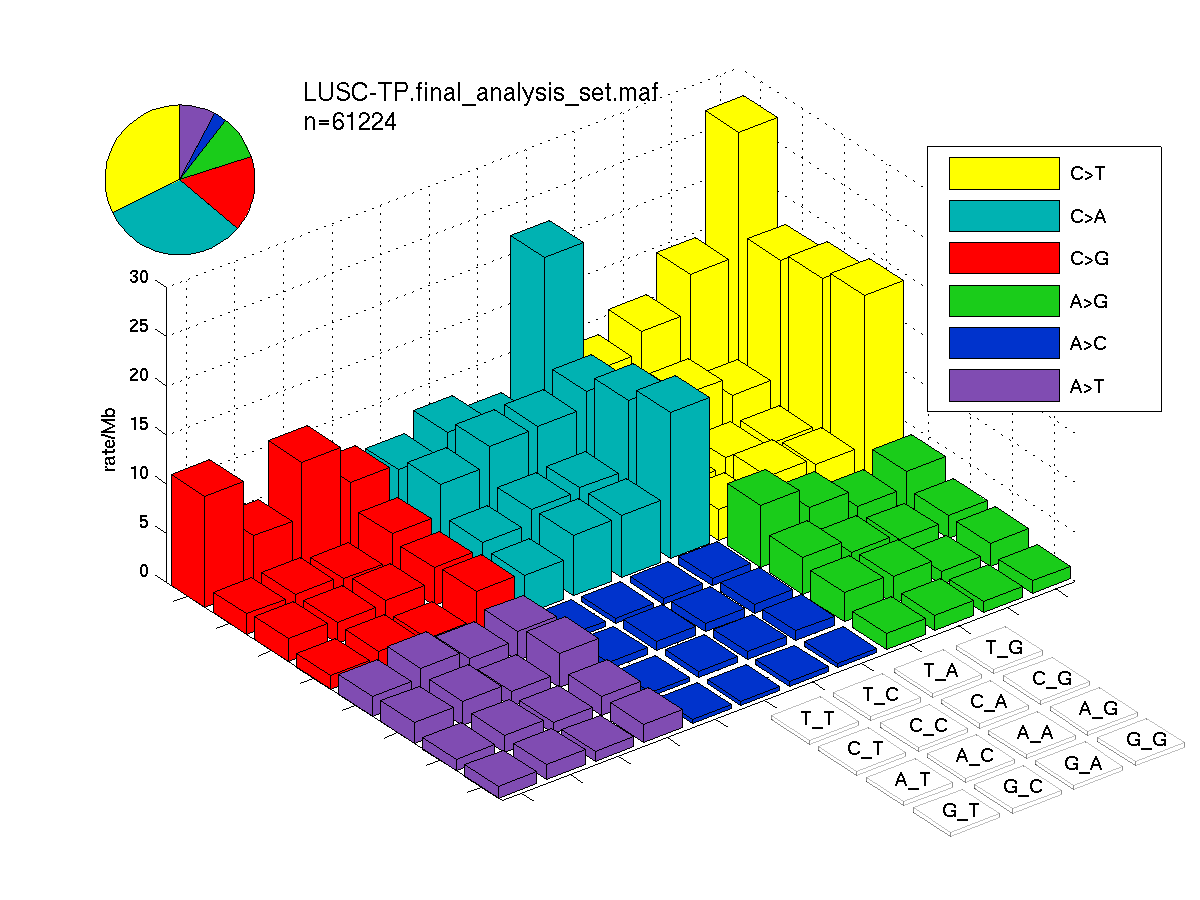
Figure 2. Get High-res Image SNV Mutation rate lego plots for 4 slices of mutation allele fraction (0<=AF<0.1, 0.1<=AF<0.25, 0.25<=AF<0.5, & 0.5<=AF) . The color code and three-base context legends are the same as the previous figure. If this figure is blank, not enough information was provided in the MAF to generate it.
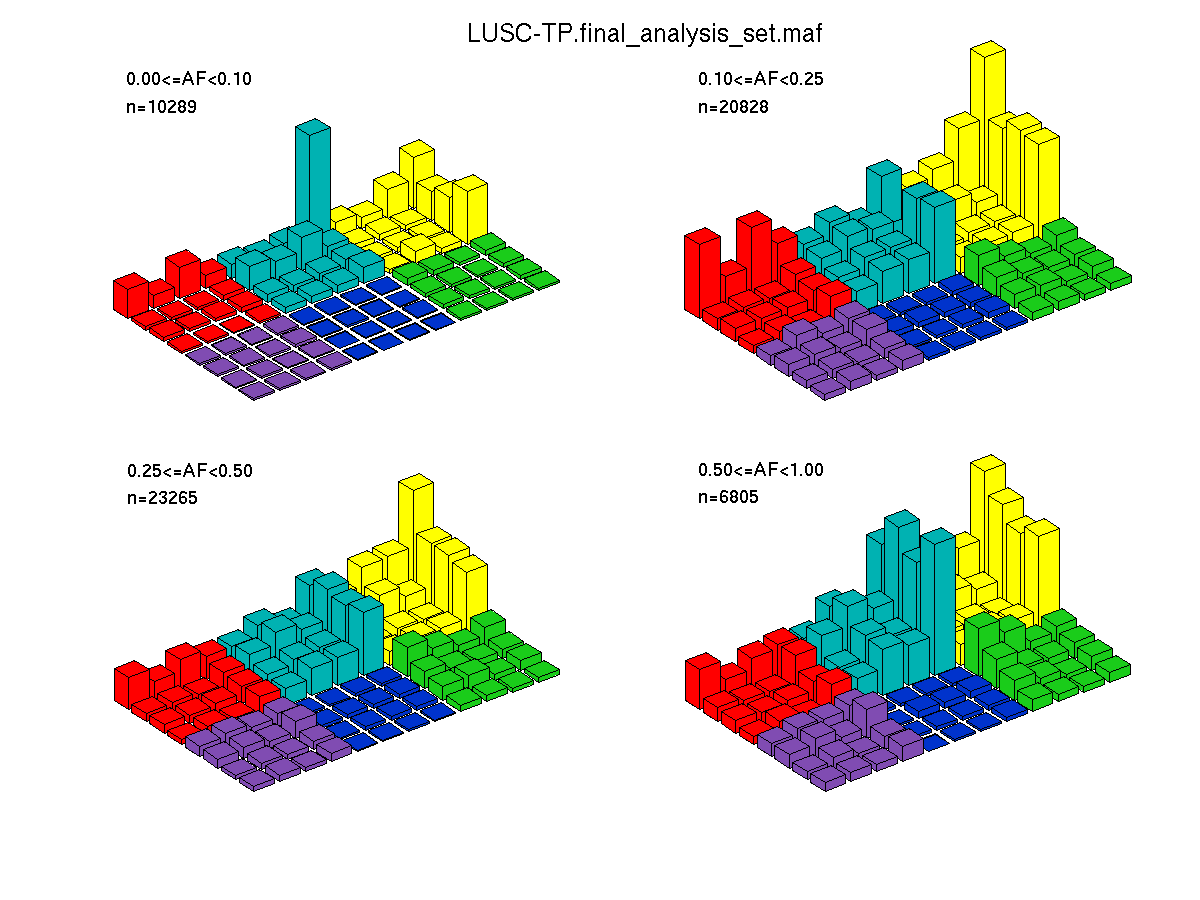
Figure 3. Get High-res Image The matrix in the center of the figure represents individual mutations in patient samples, color-coded by type of mutation, for the significantly mutated genes. The rate of synonymous and non-synonymous mutations is displayed at the top of the matrix. The barplot on the left of the matrix shows the number of mutations in each gene. The percentages represent the fraction of tumors with at least one mutation in the specified gene. The barplot to the right of the matrix displays the q-values for the most significantly mutated genes. The purple boxplots below the matrix (only displayed if required columns are present in the provided MAF) represent the distributions of allelic fractions observed in each sample. The plot at the bottom represents the base substitution distribution of individual samples, using the same categories that were used to calculate significance.

Column Descriptions:
-
nnon = number of (nonsilent) mutations in this gene across the individual set
-
npat = number of patients (individuals) with at least one nonsilent mutation
-
nsite = number of unique sites having a non-silent mutation
-
nsil = number of silent mutations in this gene across the individual set
-
p = p-value (overall)
-
q = q-value, False Discovery Rate (Benjamini-Hochberg procedure)
Table 1. Get Full Table A Ranked List of Significantly Mutated Genes. Number of significant genes found: 16. Number of genes displayed: 35. Click on a gene name to display its stick figure depicting the distribution of mutations and mutation types across the chosen gene (this feature may not be available for all significant genes).
| rank | gene | longname | codelen | nnei | nncd | nsil | nmis | nstp | nspl | nind | nnon | npat | nsite | pCV | pCL | pFN | p | q |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | TP53 | tumor protein p53 | 1890 | 25 | 0 | 1 | 96 | 20 | 17 | 17 | 150 | 145 | 97 | 1e-16 | 1e-05 | 1e-05 | 1e-16 | 9.1e-13 |
| 2 | CDKN2A | cyclin-dependent kinase inhibitor 2A (melanoma, p16, inhibits CDK4) | 1002 | 1 | 0 | 1 | 11 | 8 | 3 | 4 | 26 | 26 | 23 | 2.1e-15 | 0.43 | 1e-05 | 1e-16 | 9.1e-13 |
| 3 | NFE2L2 | nuclear factor (erythroid-derived 2)-like 2 | 1834 | 18 | 0 | 0 | 27 | 0 | 0 | 1 | 28 | 27 | 15 | 8.7e-13 | 1e-05 | 1e-05 | 3.3e-16 | 2e-12 |
| 4 | MLL2 | myeloid/lymphoid or mixed-lineage leukemia 2 | 16826 | 1 | 0 | 4 | 21 | 12 | 6 | 3 | 42 | 36 | 42 | 1.3e-13 | 1 | 0.41 | 2.8e-12 | 1.3e-08 |
| 5 | KEAP1 | kelch-like ECH-associated protein 1 | 1895 | 30 | 0 | 0 | 22 | 1 | 0 | 1 | 24 | 22 | 21 | 5.6e-12 | 0.064 | 0.19 | 1e-11 | 3.6e-08 |
| 6 | PTEN | phosphatase and tensin homolog (mutated in multiple advanced cancers 1) | 1244 | 34 | 0 | 0 | 8 | 6 | 0 | 2 | 16 | 14 | 15 | 6.3e-12 | 0.087 | 0.48 | 2.5e-11 | 7.7e-08 |
| 7 | PIK3CA | phosphoinositide-3-kinase, catalytic, alpha polypeptide | 3287 | 16 | 0 | 1 | 28 | 0 | 1 | 0 | 29 | 27 | 16 | 5.7e-06 | 1e-05 | 0.0037 | 1.4e-09 | 3.6e-06 |
| 8 | RB1 | retinoblastoma 1 (including osteosarcoma) | 3713 | 14 | 0 | 0 | 2 | 2 | 5 | 3 | 12 | 12 | 12 | 2.9e-10 | 1 | 0.77 | 6.6e-09 | 0.000015 |
| 9 | CYP11B1 | cytochrome P450, family 11, subfamily B, polypeptide 1 | 1546 | 24 | 0 | 0 | 15 | 0 | 0 | 0 | 15 | 15 | 15 | 7e-08 | 1 | 0.93 | 1.2e-06 | 0.0025 |
| 10 | NOTCH1 | Notch homolog 1, translocation-associated (Drosophila) | 7800 | 16 | 0 | 3 | 8 | 6 | 1 | 1 | 16 | 14 | 16 | 2.2e-06 | 1 | 0.0082 | 1.6e-06 | 0.003 |
| 11 | ASB5 | ankyrin repeat and SOCS box-containing 5 | 1016 | 14 | 0 | 0 | 8 | 0 | 1 | 0 | 9 | 9 | 9 | 0.000038 | 1 | 0.0079 | 1e-05 | 0.017 |
| 12 | IRF6 | interferon regulatory factor 6 | 1432 | 18 | 0 | 0 | 3 | 2 | 1 | 0 | 6 | 6 | 6 | 0.000017 | 0.066 | 0.95 | 0.000019 | 0.029 |
| 13 | EP300 | E1A binding protein p300 | 7365 | 7 | 0 | 2 | 8 | 0 | 1 | 0 | 9 | 8 | 8 | 0.17 | 0.00012 | 0.19 | 0.000024 | 0.034 |
| 14 | CPS1 | carbamoyl-phosphate synthetase 1, mitochondrial | 4748 | 23 | 1 | 2 | 26 | 0 | 2 | 0 | 28 | 24 | 27 | 7.6e-06 | 0.27 | 0.75 | 0.000033 | 0.043 |
| 15 | ARID1A | AT rich interactive domain 1A (SWI-like) | 6934 | 1 | 0 | 2 | 7 | 1 | 2 | 4 | 14 | 13 | 14 | 5.2e-06 | 1 | 0.93 | 0.000068 | 0.083 |
| 16 | SLC28A1 | solute carrier family 28 (sodium-coupled nucleoside transporter), member 1 | 2087 | 29 | 0 | 1 | 5 | 1 | 3 | 0 | 9 | 9 | 9 | 0.000064 | 1 | 0.033 | 0.000086 | 0.098 |
| 17 | POLR2B | polymerase (RNA) II (DNA directed) polypeptide B, 140kDa | 4561 | 26 | 0 | 0 | 3 | 1 | 2 | 0 | 6 | 6 | 6 | 0.000011 | 1 | 0.97 | 0.00014 | 0.15 |
| 18 | HRAS | v-Ha-ras Harvey rat sarcoma viral oncogene homolog | 659 | 570 | 0 | 0 | 5 | 0 | 0 | 0 | 5 | 5 | 4 | 0.053 | 0.0016 | 0.043 | 0.00015 | 0.15 |
| 19 | PI16 | peptidase inhibitor 16 | 1416 | 89 | 0 | 1 | 5 | 1 | 1 | 0 | 7 | 7 | 7 | 0.00018 | 1 | 0.073 | 0.00034 | 0.33 |
| 20 | EGFR | epidermal growth factor receptor (erythroblastic leukemia viral (v-erb-b) oncogene homolog, avian) | 3999 | 35 | 0 | 1 | 6 | 0 | 1 | 0 | 7 | 6 | 6 | 0.34 | 0.012 | 0.004 | 0.00038 | 0.33 |
| 21 | TAF2 | TAF2 RNA polymerase II, TATA box binding protein (TBP)-associated factor, 150kDa | 3810 | 7 | 0 | 1 | 7 | 2 | 1 | 0 | 10 | 9 | 10 | 0.000067 | 1 | 0.37 | 0.00038 | 0.33 |
| 22 | PDZD7 | PDZ domain containing 7 | 1586 | 18 | 0 | 0 | 3 | 0 | 1 | 0 | 4 | 4 | 3 | 0.0015 | 0.023 | 0.14 | 0.00041 | 0.34 |
| 23 | HLA-A | major histocompatibility complex, class I, A | 1128 | 217 | 0 | 0 | 1 | 4 | 2 | 0 | 7 | 6 | 7 | 0.0032 | 1 | 0.0038 | 0.00045 | 0.36 |
| 24 | SGK223 | 4225 | 2 | 0 | 0 | 3 | 0 | 1 | 2 | 6 | 6 | 6 | 0.0001 | 1 | 0.43 | 0.00052 | 0.39 | |
| 25 | FAT1 | FAT tumor suppressor homolog 1 (Drosophila) | 13871 | 23 | 0 | 8 | 13 | 11 | 1 | 0 | 25 | 21 | 24 | 0.00025 | 0.19 | 0.87 | 0.00055 | 0.39 |
| 26 | REG1B | regenerating islet-derived 1 beta (pancreatic stone protein, pancreatic thread protein) | 521 | 6 | 0 | 1 | 8 | 2 | 1 | 0 | 11 | 11 | 9 | 0.0067 | 0.0034 | 0.24 | 0.00056 | 0.39 |
| 27 | AKAP11 | A kinase (PRKA) anchor protein 11 | 5750 | 0 | 0 | 0 | 3 | 2 | 2 | 0 | 7 | 7 | 7 | 0.000055 | 1 | 0.82 | 0.00059 | 0.4 |
| 28 | IBTK | inhibitor of Bruton agammaglobulinemia tyrosine kinase | 4170 | 3 | 0 | 0 | 3 | 1 | 2 | 0 | 6 | 5 | 6 | 0.014 | 0.013 | 0.17 | 0.00062 | 0.4 |
| 29 | DHTKD1 | dehydrogenase E1 and transketolase domain containing 1 | 2826 | 0 | 0 | 0 | 4 | 2 | 1 | 0 | 7 | 7 | 6 | 0.0027 | 0.037 | 0.4 | 0.00063 | 0.4 |
| 30 | ABI3BP | ABI gene family, member 3 (NESH) binding protein | 3366 | 13 | 0 | 1 | 5 | 3 | 2 | 0 | 10 | 9 | 10 | 0.0003 | 1 | 0.081 | 0.00067 | 0.41 |
| 31 | MUC5B | mucin 5B, oligomeric mucus/gel-forming | 17492 | 36 | 0 | 8 | 29 | 2 | 2 | 1 | 34 | 29 | 34 | 0.000085 | 1 | 0.56 | 0.00088 | 0.52 |
| 32 | CCDC83 | coiled-coil domain containing 83 | 1379 | 13 | 0 | 0 | 5 | 1 | 1 | 0 | 7 | 6 | 7 | 0.00019 | 1 | 0.43 | 0.0011 | 0.64 |
| 33 | KDM6A | lysine (K)-specific demethylase 6A | 4318 | 7 | 0 | 0 | 1 | 2 | 4 | 0 | 7 | 7 | 7 | 0.0013 | 0.16 | 0.24 | 0.0013 | 0.71 |
| 34 | COL7A1 | collagen, type VII, alpha 1 (epidermolysis bullosa, dystrophic, dominant and recessive) | 9304 | 10 | 0 | 2 | 8 | 3 | 1 | 1 | 13 | 13 | 13 | 0.00093 | 1 | 0.1 | 0.0013 | 0.71 |
| 35 | CUL3 | cullin 3 | 2367 | 69 | 0 | 1 | 6 | 2 | 4 | 0 | 12 | 11 | 12 | 0.0007 | 0.18 | 0.87 | 0.0014 | 0.75 |
Figure S1. This figure depicts the distribution of mutations and mutation types across the TP53 significant gene.
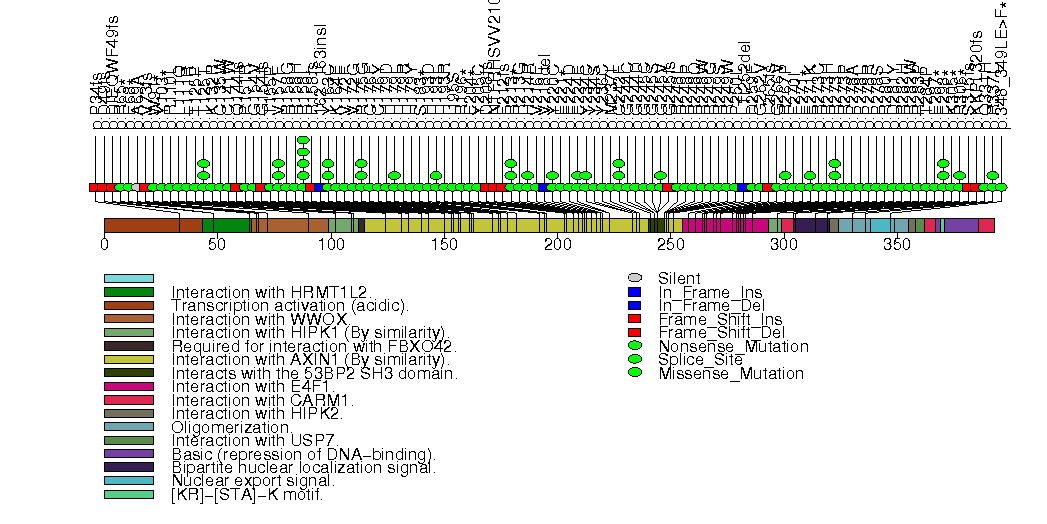
Figure S2. This figure depicts the distribution of mutations and mutation types across the CDKN2A significant gene.

Figure S3. This figure depicts the distribution of mutations and mutation types across the NFE2L2 significant gene.
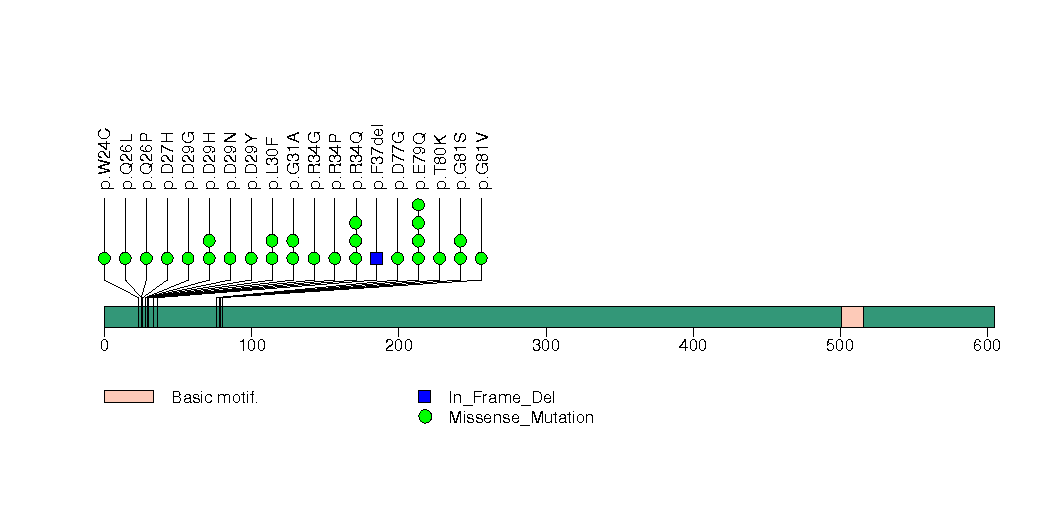
Figure S4. This figure depicts the distribution of mutations and mutation types across the KEAP1 significant gene.
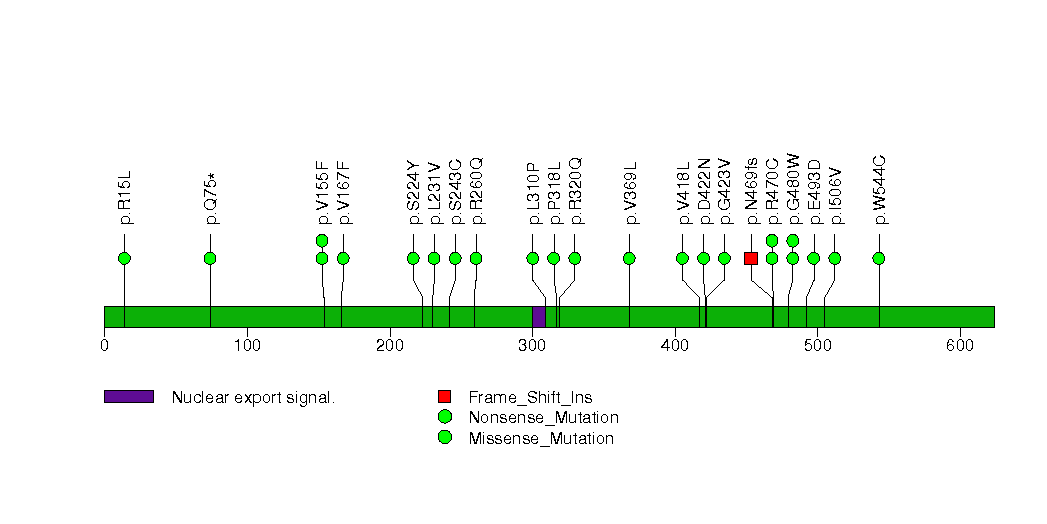
Figure S5. This figure depicts the distribution of mutations and mutation types across the PTEN significant gene.
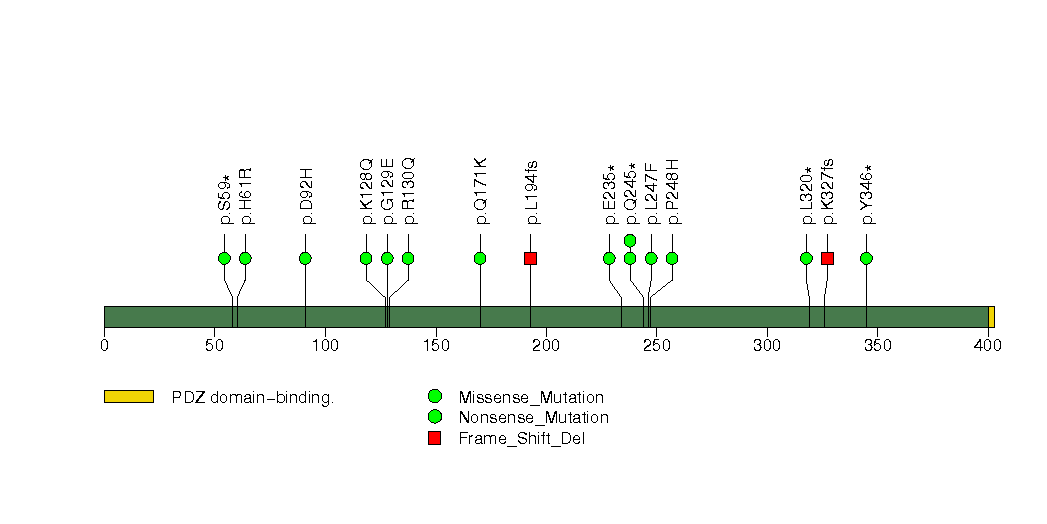
Figure S6. This figure depicts the distribution of mutations and mutation types across the PIK3CA significant gene.

Figure S7. This figure depicts the distribution of mutations and mutation types across the RB1 significant gene.
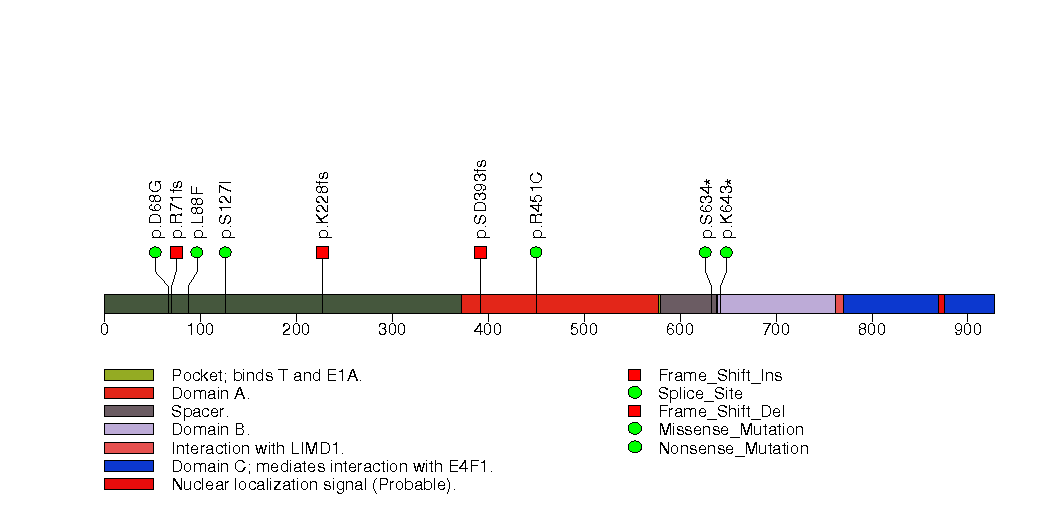
Figure S8. This figure depicts the distribution of mutations and mutation types across the CYP11B1 significant gene.
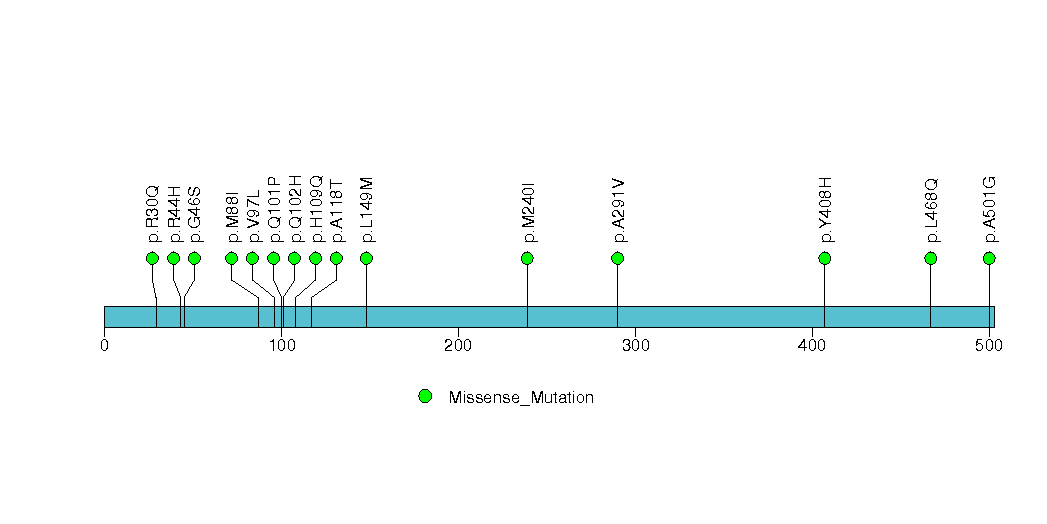
Figure S9. This figure depicts the distribution of mutations and mutation types across the NOTCH1 significant gene.
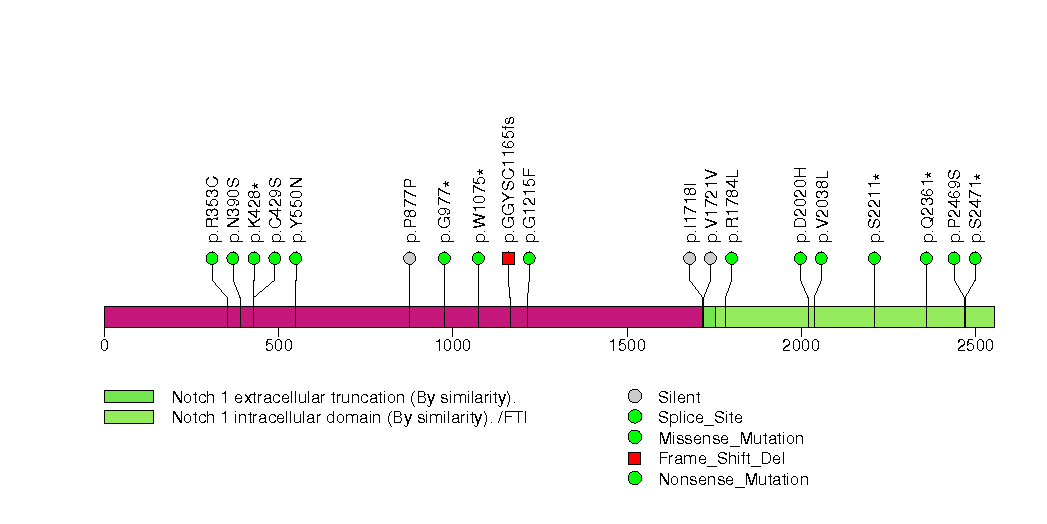
Figure S10. This figure depicts the distribution of mutations and mutation types across the ASB5 significant gene.
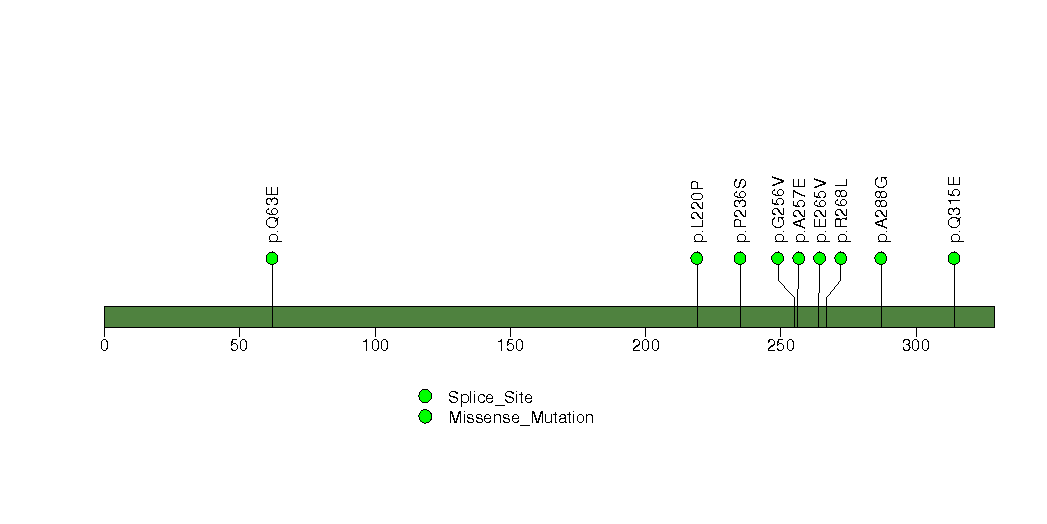
Figure S11. This figure depicts the distribution of mutations and mutation types across the IRF6 significant gene.
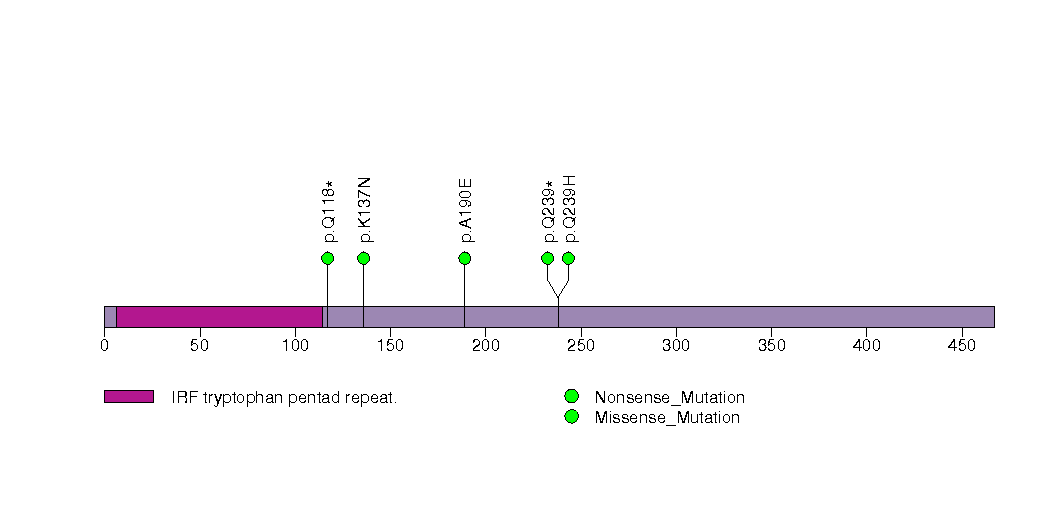
Figure S12. This figure depicts the distribution of mutations and mutation types across the EP300 significant gene.
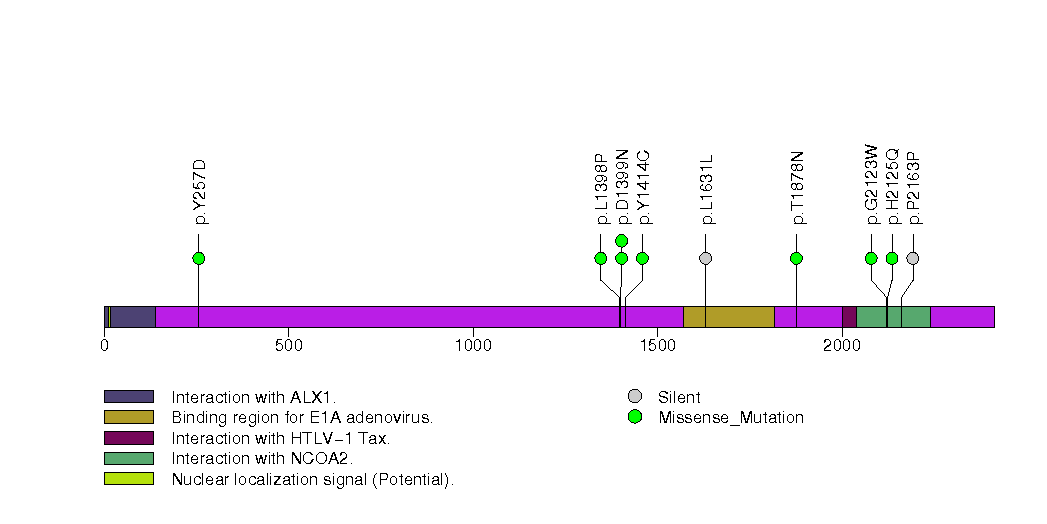
Figure S13. This figure depicts the distribution of mutations and mutation types across the CPS1 significant gene.
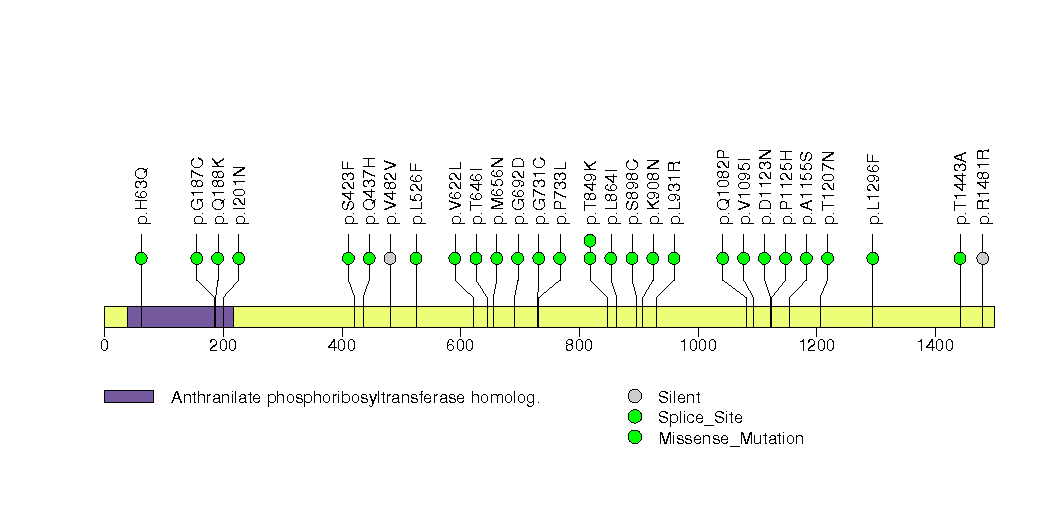
Figure S14. This figure depicts the distribution of mutations and mutation types across the ARID1A significant gene.
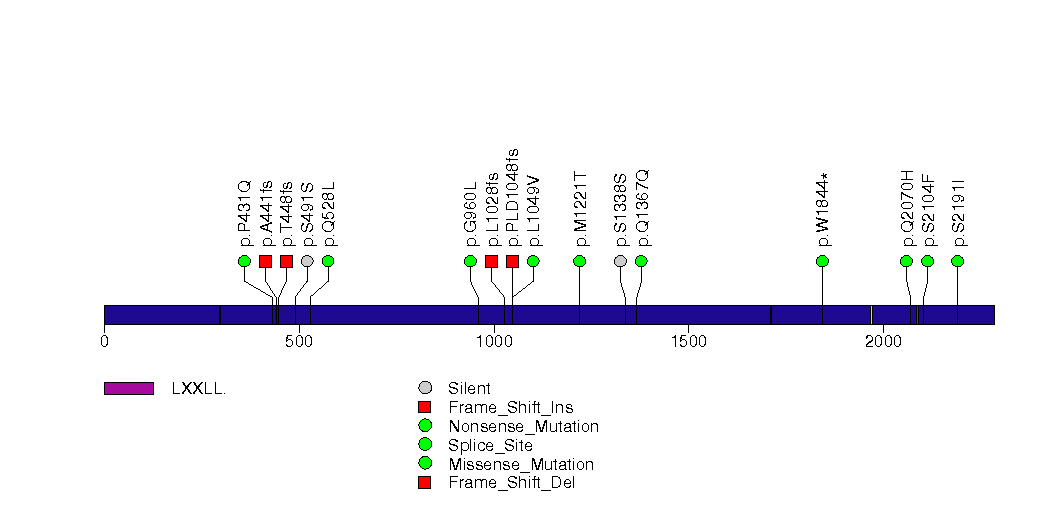
Figure S15. This figure depicts the distribution of mutations and mutation types across the SLC28A1 significant gene.
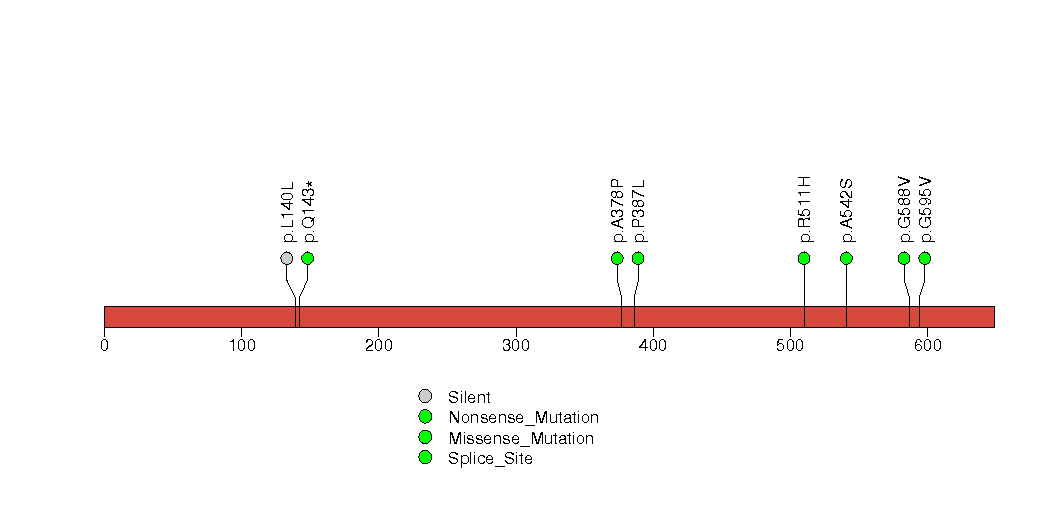
MutSig and its evolving algorithms have existed since the youth of clinical sequencing, with early versions used in multiple publications. [1][2][3]
"Three significance metrics [are] calculated for each gene, using the […] methods MutSigCV [4], MutSigCL, and MutSigFN [5]. These measure the significance of mutation burden, clustering, and functional impact, respectively […]. MutSigCV determines the P value for observing the given quantity of non-silent mutations in the gene, given the background model determined by silent (and noncoding) mutations in the same gene and the neighbouring genes of covariate space that form its 'bagel'. […] MutSigCL and MutSigFN measure the significance of the positional clustering of the mutations observed, as well as the significance of the tendency for mutations to occur at positions that are highly evolutionarily conserved (using conservation as a proxy for probably functional impact). MutSigCL and MutSigFN are permutation-based methods and their P values are calculated as follows: The observed nonsilent coding mutations in the gene are permuted T times (to simulate the null hypothesis, T = 108 for the most significant genes), randomly reassigning their positions, but preserving their mutational 'category', as determined by local sequence context. We [use] the following context categories: transitions at CpG dinucleotides, transitions at other C-G base pairs, transversions at C-G base pairs, mutations at A-T base pairs, and indels. Indels are unconstrained in terms of where they can move to in the permutations. For each of the random permutations, two scores are calculated: SCL and SFN, measuring the amount of clustering and function impact (measured by conservation) respectively. SCL is defined to be the fraction of mutations occurring in hotspots. A hotspot is defined as a 3-base-pair region of the gene containing many mutations: at least 2, and at least 2% of the total mutations. SFN is defined to be the mean of the base-pair-level conservation values for the position of each non-silent mutation […]. To determine a PCL, the P value for the observed degree of positional clustering, the observed value of SCL (computed for the mutations actually observed), [is] compared to the distribution of SCL obtained from the random permutations, and the P value [is] defined to be the fraction of random permutations in which SCL [is] at least as large as the observed SCL. The P value for the conservation of the mutated positions, PFN, [is] computed analogously." [6]
In addition to the links below, the full results of the analysis summarized in this report can also be downloaded programmatically using firehose_get, or interactively from either the Broad GDAC website or TCGA Data Coordination Center Portal.