This report serves to describe the mutational landscape and properties of a given individual set, as well as rank genes and genesets according to mutational significance. MutSigCV v0.9 was used to generate the results found in this report.
-
Working with individual set: OV-TP
-
Number of patients in set: 467
The input for this pipeline is a set of individuals with the following files associated for each:
-
An annotated .maf file describing the mutations called for the respective individual, and their properties.
-
A .wig file that contains information about the coverage of the sample.
-
MAF used for this analysis:OV-TP.final_analysis_set.maf
-
Blacklist used for this analysis: pancan_mutation_blacklist.v14.hg19.txt
-
Significantly mutated genes (q ≤ 0.1): 5
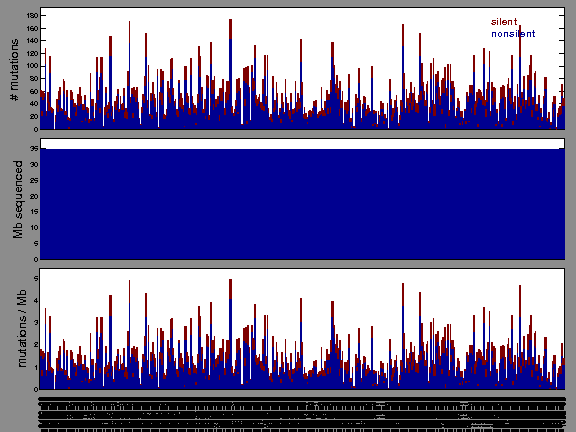
The x axis represents the samples. The y axis represents the exons, one row per exon, and they are sorted by average coverage across samples. For exons with exactly the same average coverage, they are sorted next by the %GC of the exon. (The secondary sort is especially useful for the zero-coverage exons at the bottom). If the figure is unpopulated, then full coverage is assumed (e.g. MutSig CV doesn't use WIGs and assumes full coverage).
Figure 1.

Figure 2. Patients counts and rates file used to generate this plot: OV-TP.patients.counts_and_rates.txt
The mutation spectrum is depicted in the lego plots below in which the 96 possible mutation types are subdivided into six large blocks, color-coded to reflect the base substitution type. Each large block is further subdivided into the 16 possible pairs of 5' and 3' neighbors, as listed in the 4x4 trinucleotide context legend. The height of each block corresponds to the mutation frequency for that kind of mutation (counts of mutations normalized by the base coverage in a given bin). The shape of the spectrum is a signature for dominant mutational mechanisms in different tumor types.
Figure 3. Get High-res Image SNV Mutation rate lego plot for entire set. Each bin is normalized by base coverage for that bin. Colors represent the six SNV types on the upper right. The three-base context for each mutation is labeled in the 4x4 legend on the lower right. The fractional breakdown of SNV counts is shown in the pie chart on the upper left. If this figure is blank, not enough information was provided in the MAF to generate it.
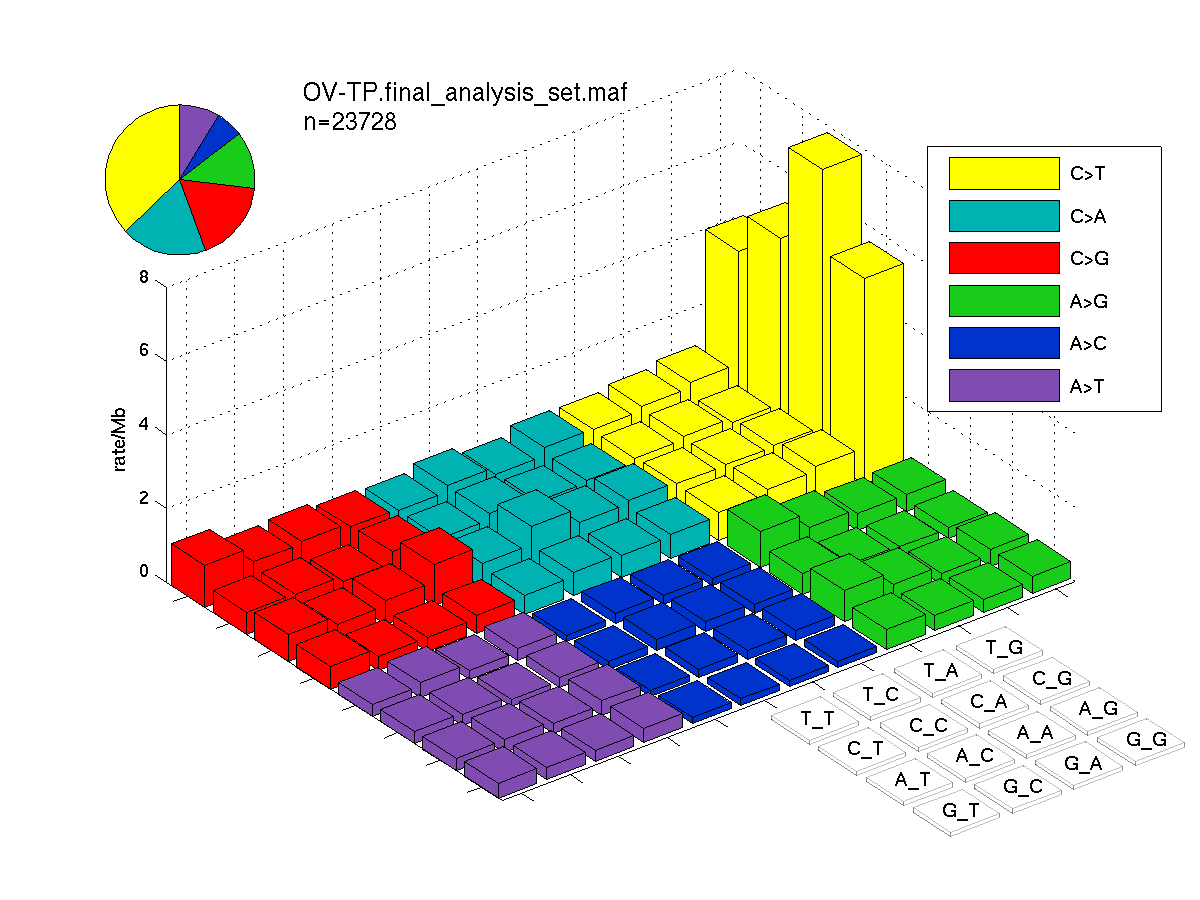
Figure 4. Get High-res Image SNV Mutation rate lego plots for 4 slices of mutation allele fraction (0<=AF<0.1, 0.1<=AF<0.25, 0.25<=AF<0.5, & 0.5<=AF) . The color code and three-base context legends are the same as the previous figure. If this figure is blank, not enough information was provided in the MAF to generate it.

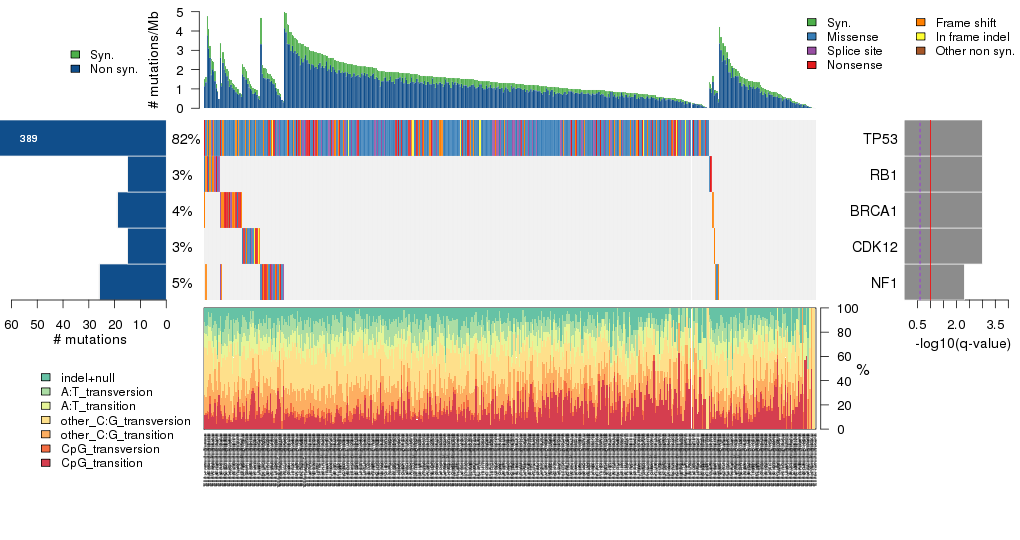
Figure 5. Get High-res Image The matrix in the center of the figure represents individual mutations in patient samples, color-coded by type of mutation, for the significantly mutated genes. The rate of synonymous and non-synonymous mutations is displayed at the top of the matrix. The barplot on the left of the matrix shows the number of mutations in each gene. The percentages represent the fraction of tumors with at least one mutation in the specified gene. The barplot to the right of the matrix displays the q-values for the most significantly mutated genes. The purple boxplots below the matrix (only displayed if required columns are present in the provided MAF) represent the distributions of allelic fractions observed in each sample. The plot at the bottom represents the base substitution distribution of individual samples, using the same categories that were used to calculate significance.
Column Descriptions:
-
nnon = number of (nonsilent) mutations in this gene across the individual set
-
npat = number of patients (individuals) with at least one nonsilent mutation
-
nsite = number of unique sites having a non-silent mutation
-
nflank = number of noncoding mutations from this gene's flanking region, across the individual set
-
nsil = number of silent mutations in this gene across the individual set
-
p = p-value (overall)
-
q = q-value, False Discovery Rate (Benjamini-Hochberg procedure)
Table 1. Get Full Table A Ranked List of Significantly Mutated Genes. Number of significant genes found: 5. Number of genes displayed: 35. Click on a gene name to display its stick figure depicting the distribution of mutations and mutation types across the chosen gene (this feature may not be available for all significant genes).
| gene | Nnon | Nsil | Nflank | nnon | npat | nsite | nsil | nflank | nnei | fMLE | p | score | time | q |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TP53 | 441315 | 128892 | 94348 | 389 | 385 | 177 | 0 | 0 | 4 | 0.91 | 2.4e-15 | 1500 | 0.47 | 4.5e-11 |
| RB1 | 1330016 | 350717 | 222588 | 15 | 15 | 15 | 0 | 0 | 20 | 0.49 | 8.8e-14 | 78 | 0.43 | 8.1e-10 |
| BRCA1 | 2130454 | 538451 | 205642 | 19 | 19 | 19 | 0 | 0 | 14 | 0.57 | 6.1e-13 | 100 | 0.41 | 3.7e-09 |
| CDK12 | 1594338 | 481477 | 121828 | 15 | 15 | 15 | 0 | 0 | 20 | 0.74 | 3.4e-10 | 73 | 0.53 | 1.5e-06 |
| NF1 | 4395404 | 1231946 | 542272 | 26 | 24 | 26 | 0 | 0 | 0 | 0 | 1.1e-06 | 110 | 0.41 | 0.0039 |
| IL21R | 579080 | 174658 | 71448 | 8 | 8 | 8 | 0 | 0 | 20 | 1.1 | 0.000044 | 35 | 0.45 | 0.13 |
| EFEMP1 | 558999 | 148973 | 92058 | 7 | 7 | 7 | 0 | 0 | 20 | 0.92 | 0.000064 | 32 | 0.39 | 0.17 |
| GPX6 | 250779 | 66781 | 47632 | 4 | 4 | 4 | 0 | 0 | 20 | 0.27 | 0.00014 | 19 | 0.38 | 0.32 |
| NRAS | 215287 | 56974 | 37556 | 4 | 4 | 3 | 0 | 0 | 20 | 0.67 | 0.0003 | 19 | 0.41 | 0.61 |
| PTEN | 454858 | 109278 | 79692 | 5 | 5 | 5 | 0 | 0 | 20 | 1.1 | 0.0004 | 25 | 0.46 | 0.69 |
| TOP2A | 1535496 | 391813 | 205184 | 8 | 8 | 8 | 1 | 0 | 20 | 0.51 | 0.00042 | 36 | 0.42 | 0.69 |
| DUSP19 | 243774 | 66314 | 38014 | 4 | 4 | 4 | 0 | 0 | 20 | 0.4 | 0.00059 | 16 | 0.37 | 0.89 |
| DAD1 | 121887 | 39228 | 20152 | 2 | 2 | 2 | 0 | 0 | 20 | 0.86 | 0.00081 | 14 | 0.35 | 1 |
| GPR1 | 387143 | 110679 | 10992 | 4 | 4 | 4 | 0 | 0 | 20 | 0.72 | 0.0012 | 18 | 0.38 | 1 |
| CREBBP | 2516196 | 721982 | 282586 | 11 | 11 | 11 | 1 | 0 | 11 | 0.25 | 0.0012 | 48 | 0.55 | 1 |
| EMR3 | 727586 | 204546 | 144728 | 7 | 7 | 7 | 2 | 0 | 20 | 0.65 | 0.0013 | 26 | 0.39 | 1 |
| GABRA6 | 505761 | 143369 | 83814 | 7 | 7 | 7 | 1 | 0 | 20 | 1.3 | 0.0013 | 24 | 0.6 | 1 |
| FAM171B | 887767 | 256850 | 70990 | 9 | 9 | 9 | 1 | 0 | 20 | 2.1 | 0.0017 | 33 | 0.48 | 1 |
| ITGA2B | 942406 | 296545 | 218008 | 7 | 7 | 7 | 0 | 0 | 20 | 0.82 | 0.0018 | 28 | 0.4 | 1 |
| L1CAM | 1336554 | 384341 | 240450 | 8 | 8 | 8 | 2 | 0 | 20 | 0.67 | 0.002 | 31 | 0.38 | 1 |
| PROKR2 | 417031 | 121887 | 21068 | 6 | 6 | 6 | 1 | 0 | 20 | 1 | 0.0021 | 20 | 0.45 | 1 |
| DEFB118 | 135897 | 39228 | 20152 | 4 | 4 | 4 | 0 | 0 | 12 | 2.9 | 0.0021 | 19 | 0.36 | 1 |
| CACNG6 | 178394 | 62111 | 33892 | 3 | 3 | 3 | 0 | 0 | 20 | 0.87 | 0.0021 | 17 | 0.46 | 1 |
| EOMES | 497355 | 141968 | 52212 | 5 | 5 | 5 | 0 | 0 | 20 | 1 | 0.0024 | 23 | 0.4 | 1 |
| PAGE2 | 112547 | 31289 | 24274 | 2 | 2 | 2 | 0 | 0 | 20 | 1.6 | 0.0027 | 14 | 0.34 | 1 |
| ATP11C | 1281915 | 344179 | 321058 | 7 | 7 | 7 | 0 | 0 | 20 | 0.76 | 0.0028 | 28 | 0.53 | 1 |
| FAM24A | 119552 | 31756 | 19236 | 2 | 2 | 2 | 0 | 0 | 20 | 0.67 | 0.0028 | 11 | 0.32 | 1 |
| TAS2R1 | 324098 | 94801 | 10992 | 6 | 6 | 6 | 0 | 0 | 9 | 0.9 | 0.0029 | 23 | 0.39 | 1 |
| OR5AK2 | 336240 | 95268 | 11908 | 3 | 3 | 3 | 1 | 0 | 17 | 0.41 | 0.003 | 17 | 0.47 | 1 |
| HNF1B | 543588 | 154577 | 71906 | 5 | 5 | 5 | 0 | 0 | 15 | 0.44 | 0.0031 | 23 | 0.38 | 1 |
| PTGDS | 187734 | 54639 | 46258 | 2 | 2 | 2 | 0 | 0 | 20 | 0.46 | 0.0031 | 14 | 0.39 | 1 |
| C9orf171 | 302149 | 92466 | 53128 | 5 | 5 | 5 | 0 | 0 | 20 | 1.5 | 0.0032 | 20 | 0.44 | 1 |
| MARCH4 | 372666 | 107877 | 37098 | 5 | 5 | 5 | 0 | 0 | 11 | 0.79 | 0.0036 | 20 | 0.37 | 1 |
| NF2 | 598227 | 150841 | 128240 | 4 | 4 | 4 | 0 | 0 | 20 | 0.36 | 0.0037 | 20 | 0.4 | 1 |
| PPM1F | 366128 | 116283 | 47174 | 5 | 5 | 4 | 0 | 0 | 20 | 0.73 | 0.0038 | 17 | 0.39 | 1 |
Figure S1. This figure depicts the distribution of mutations and mutation types across the TP53 significant gene.
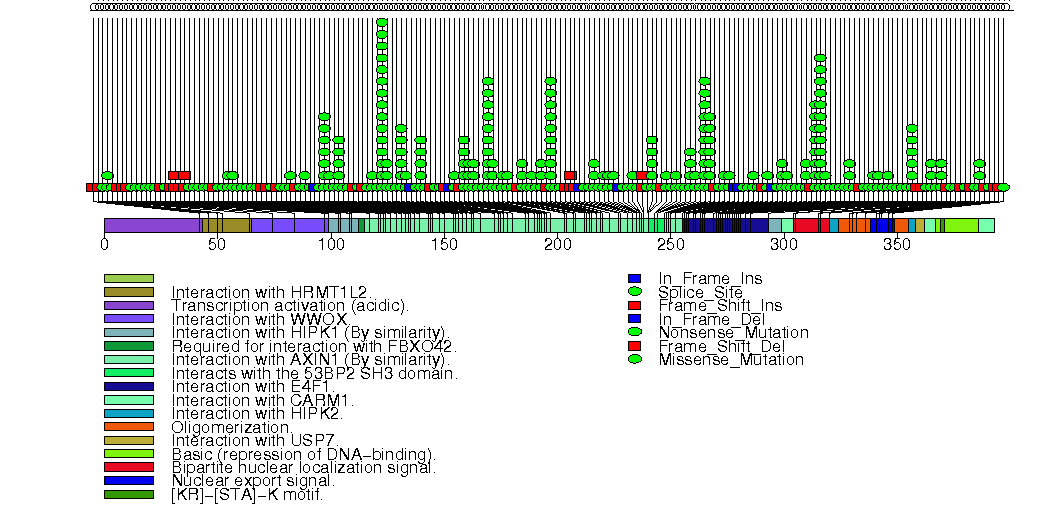
Figure S2. This figure depicts the distribution of mutations and mutation types across the RB1 significant gene.
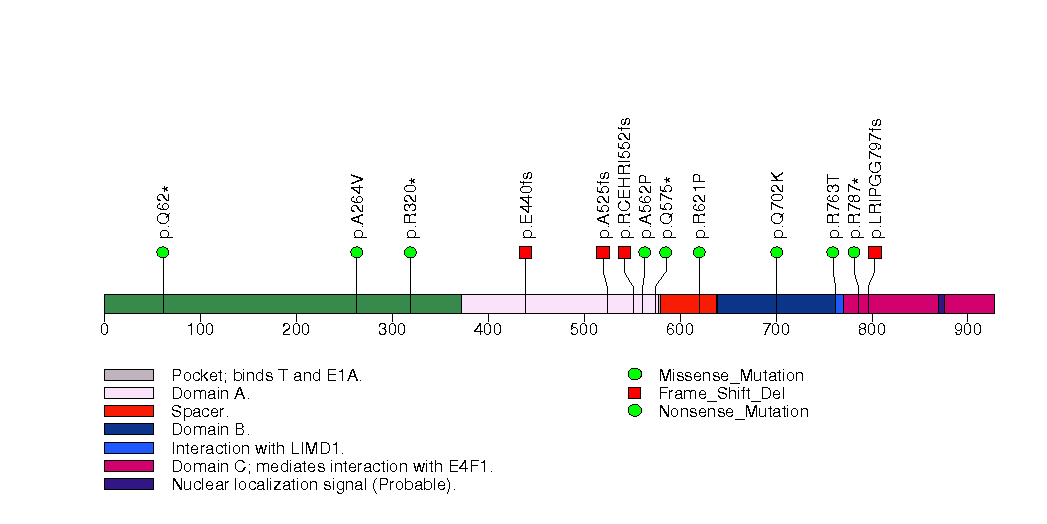
Figure S3. This figure depicts the distribution of mutations and mutation types across the BRCA1 significant gene.
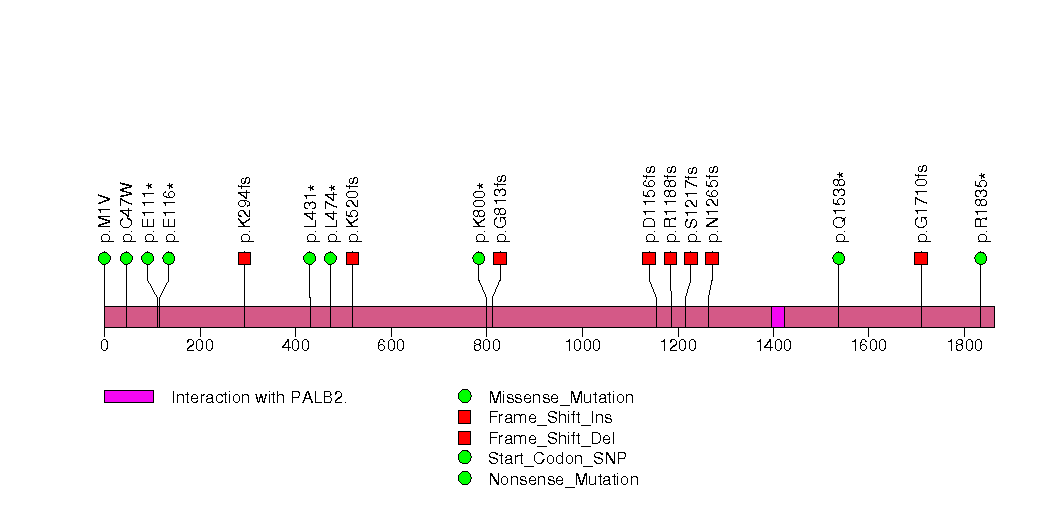
Figure S4. This figure depicts the distribution of mutations and mutation types across the CDK12 significant gene.
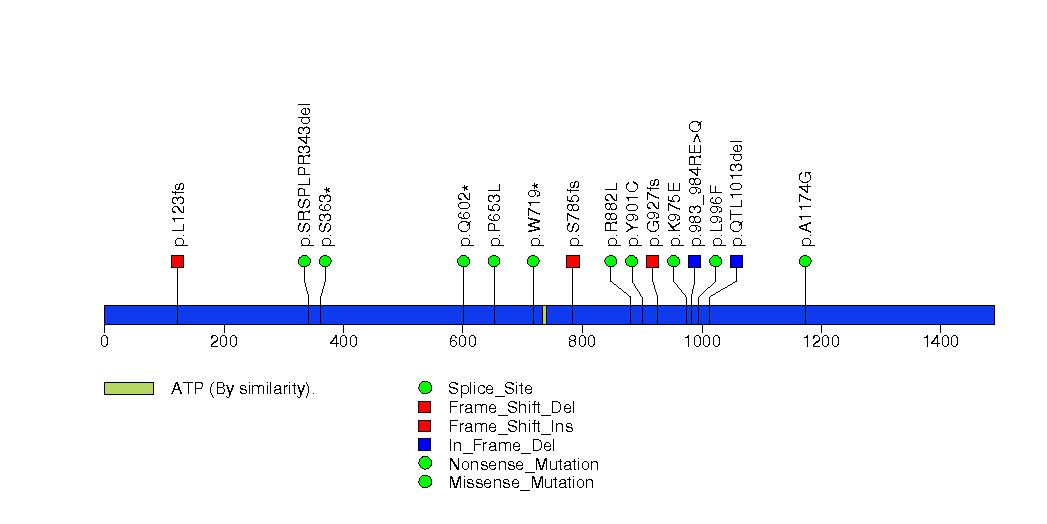
Figure S5. This figure depicts the distribution of mutations and mutation types across the NF1 significant gene.
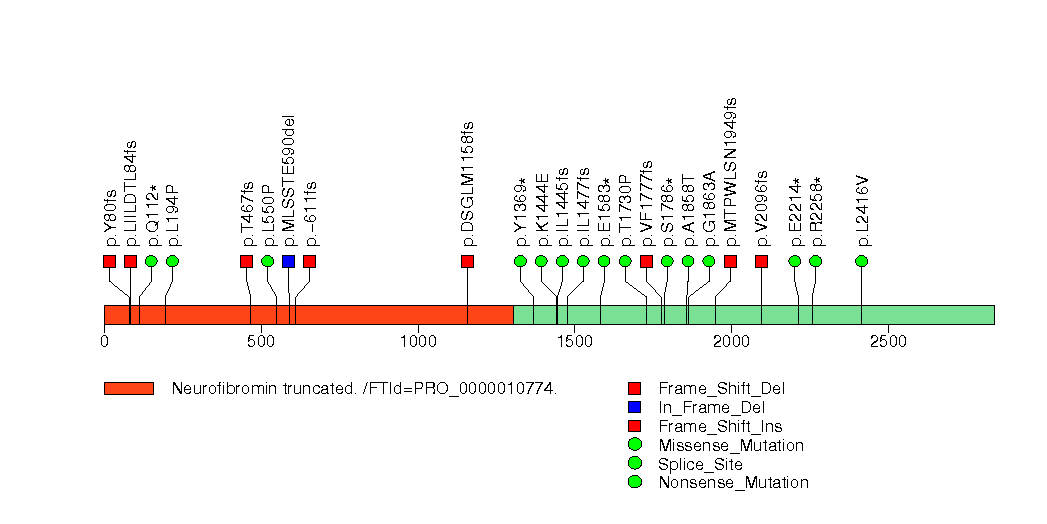
In brief, we tabulate the number of mutations and the number of covered bases for each gene. The counts are broken down by mutation context category: four context categories that are discovered by MutSig, and one for indel and 'null' mutations, which include indels, nonsense mutations, splice-site mutations, and non-stop (read-through) mutations. For each gene, we calculate the probability of seeing the observed constellation of mutations, i.e. the product P1 x P2 x ... x Pm, or a more extreme one, given the background mutation rates calculated across the dataset. [1]
In addition to the links below, the full results of the analysis summarized in this report can also be downloaded programmatically using firehose_get, or interactively from either the Broad GDAC website or TCGA Data Coordination Center Portal.