This is a summary of data mirrored from the Genomic Data Commons (GDC) and processed by the GDCtools package. Note that some sample data will be filtered as unsuitable for downstream pipelines, through one of three mechanisms: redactions, replicate filtering, and blacklisting. The report lists the counts and types of the sample data, in both hyperlinked tables and heatmap images; describes the three filtering mechanisms; lists the samples removed by filtering, why they were removed; and (eventually will) catalog how the data have been annotated by the respective projects that submitted them to the GDC.
There were 0 redactions, 1138 replicate aliquots, 0 blacklisted aliquots, and 0 FFPE aliquots. The table below represents the sample counts for those samples that were ingested into firehose after filtering out redactions, replicates, and blacklisted data, and segregating FFPEs.
Table 1. Get Full Table Summary of TCGA Tumor Data. Click on a tumor type to display a tumor type specific Samples Report.
| Cohort | BCR | Clinical | CN | mRNA | miR | MAF | Methylation |
|---|---|---|---|---|---|---|---|
| ACC | 92 | 92 | 90 | 79 | 80 | 92 | 80 |
| BLCA | 412 | 412 | 412 | 408 | 409 | 412 | 412 |
| BRCA | 1097 | 1096 | 1094 | 1085 | 1078 | 1044 | 1094 |
| CESC | 307 | 307 | 295 | 304 | 307 | 305 | 307 |
| CHOL | 51 | 45 | 36 | 36 | 36 | 51 | 36 |
| COAD | 461 | 459 | 450 | 456 | 444 | 432 | 458 |
| COADREAD | 633 | 629 | 614 | 622 | 605 | 589 | 623 |
| DLBC | 58 | 48 | 48 | 48 | 47 | 48 | 48 |
| ESCA | 185 | 185 | 184 | 161 | 184 | 184 | 185 |
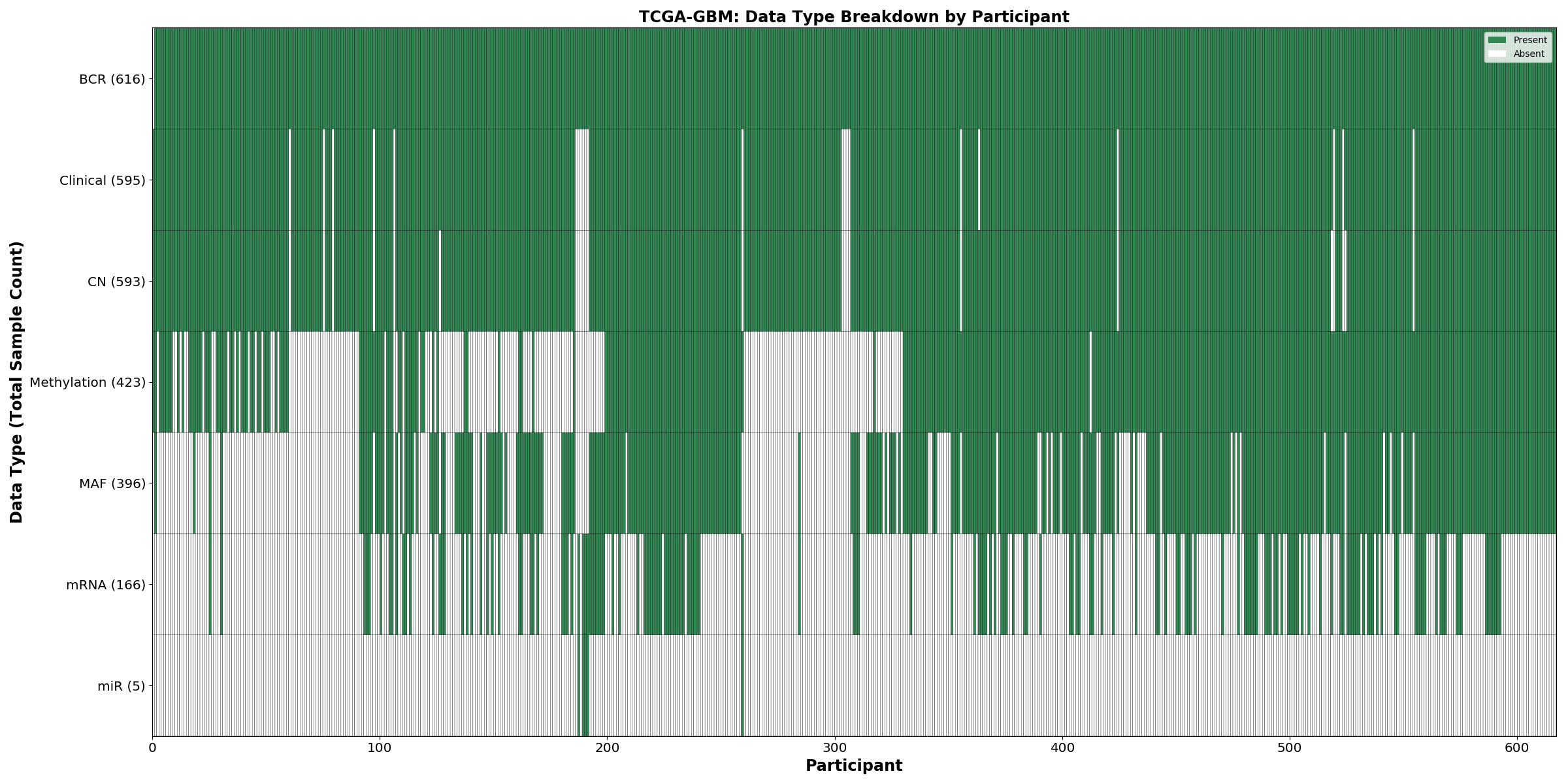
| GBM | 616 | 595 | 590 | 154 | 0 | 396 | 422 |
| GBMLGG | 1131 | 1109 | 1104 | 665 | 512 | 909 | 937 |
| HNSC | 527 | 527 | 517 | 500 | 523 | 510 | 527 |
| KICH | 113 | 113 | 66 | 65 | 66 | 66 | 66 |
| KIPAN | 940 | 940 | 886 | 883 | 873 | 693 | 889 |
| KIRC | 536 | 536 | 530 | 530 | 516 | 339 | 532 |
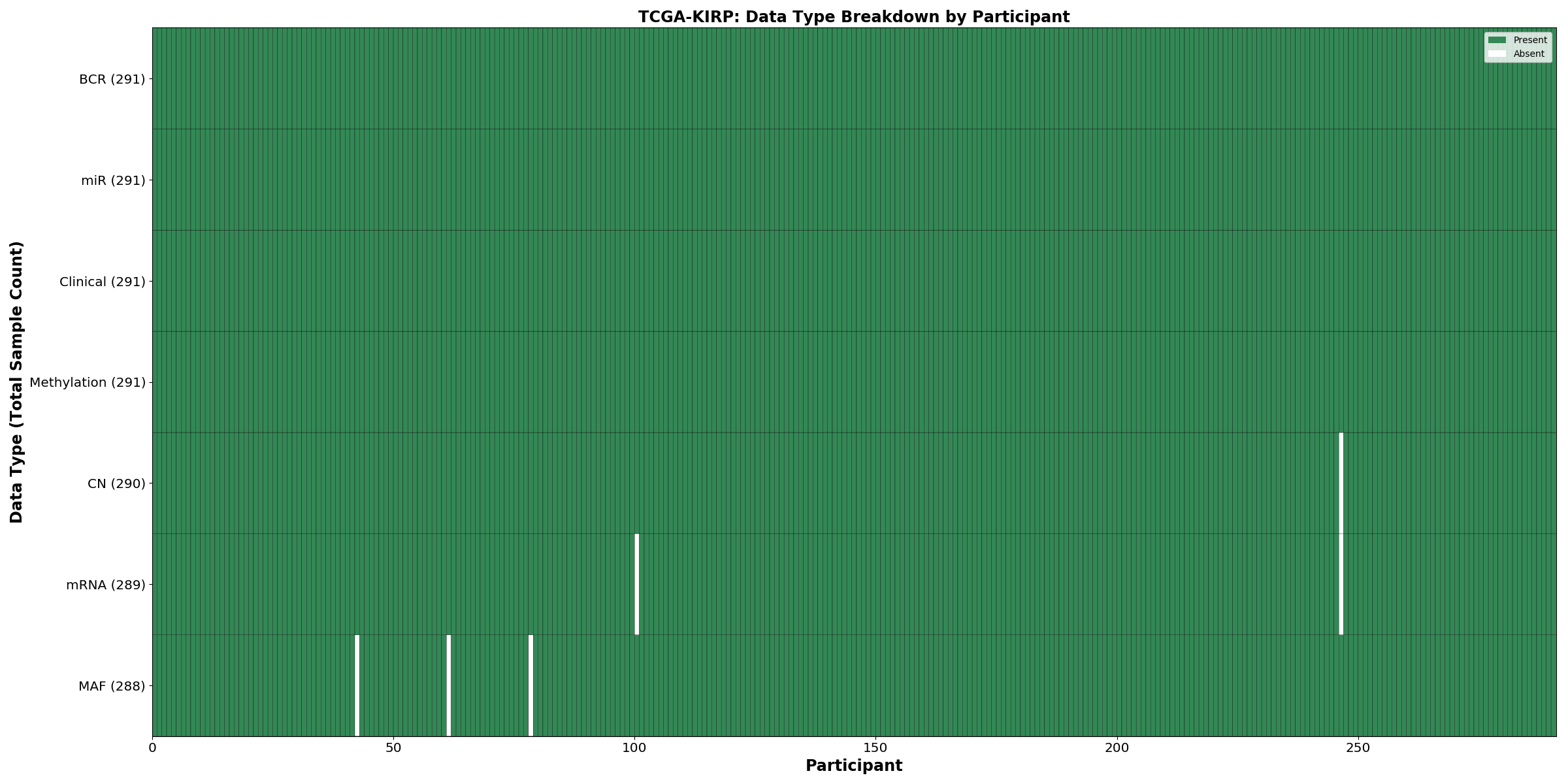
| KIRP | 291 | 291 | 290 | 288 | 291 | 288 | 291 |
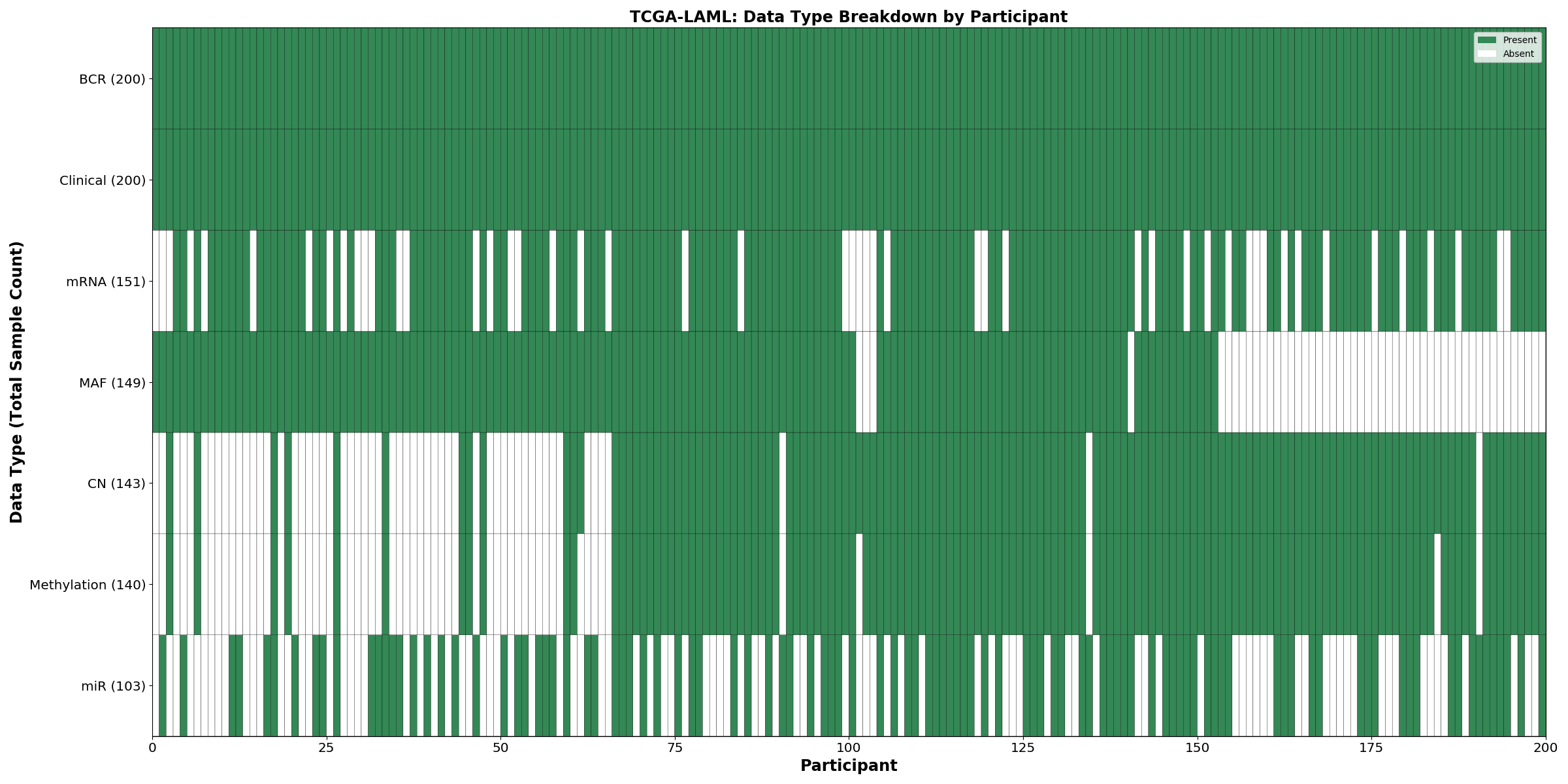
| LAML | 200 | 200 | 143 | 151 | 103 | 149 | 140 |
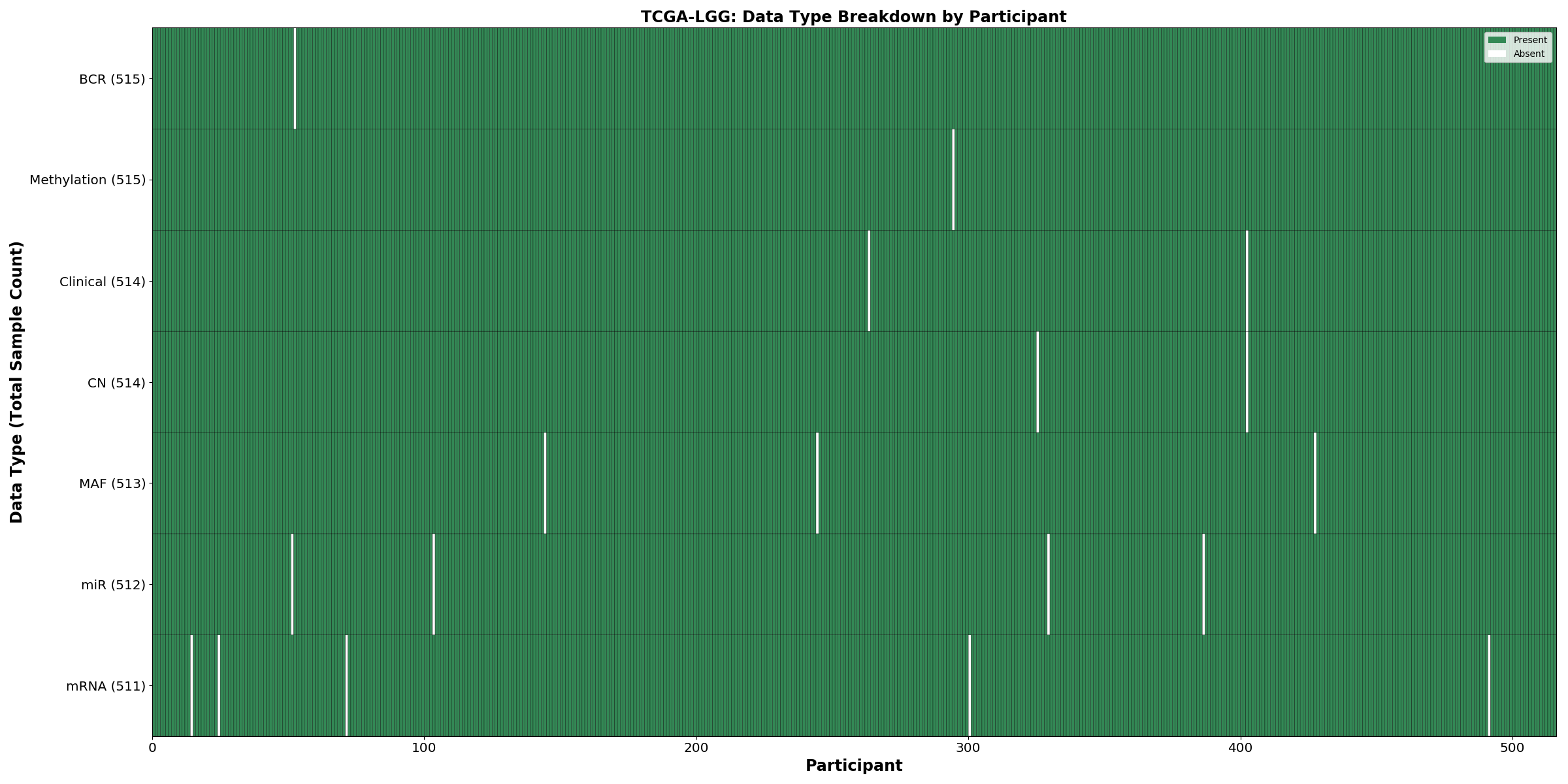
| LGG | 515 | 514 | 514 | 511 | 512 | 513 | 515 |
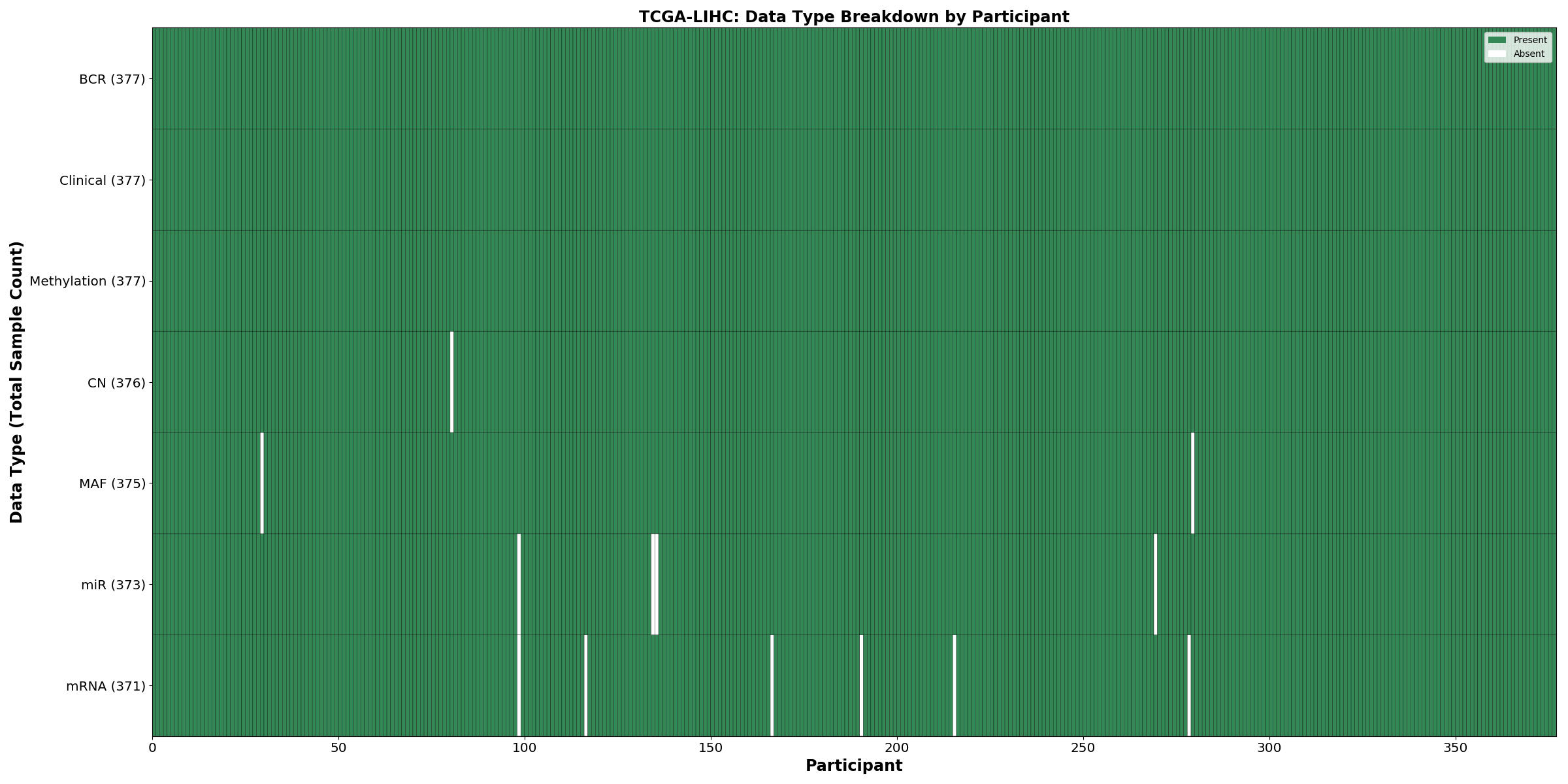
| LIHC | 377 | 377 | 375 | 371 | 372 | 375 | 377 |
| LUAD | 584 | 521 | 518 | 513 | 513 | 569 | 577 |
| LUSC | 503 | 503 | 503 | 501 | 478 | 497 | 502 |
| MESO | 87 | 87 | 87 | 86 | 87 | 83 | 87 |
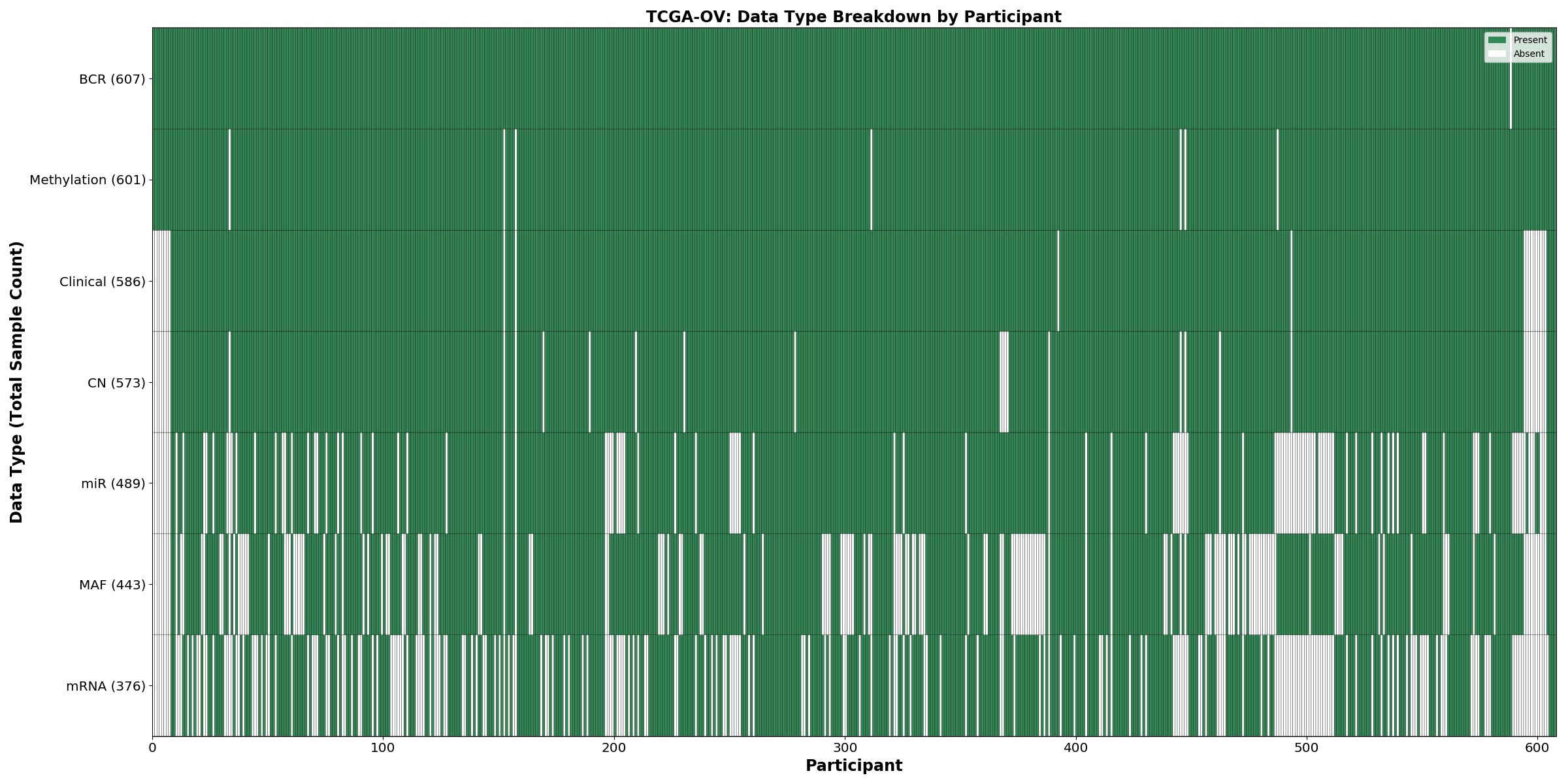
| OV | 607 | 586 | 568 | 374 | 489 | 441 | 591 |
| PAAD | 185 | 185 | 184 | 177 | 178 | 183 | 184 |
| PANGI | 1261 | 1257 | 1240 | 1158 | 1225 | 1214 | 1251 |
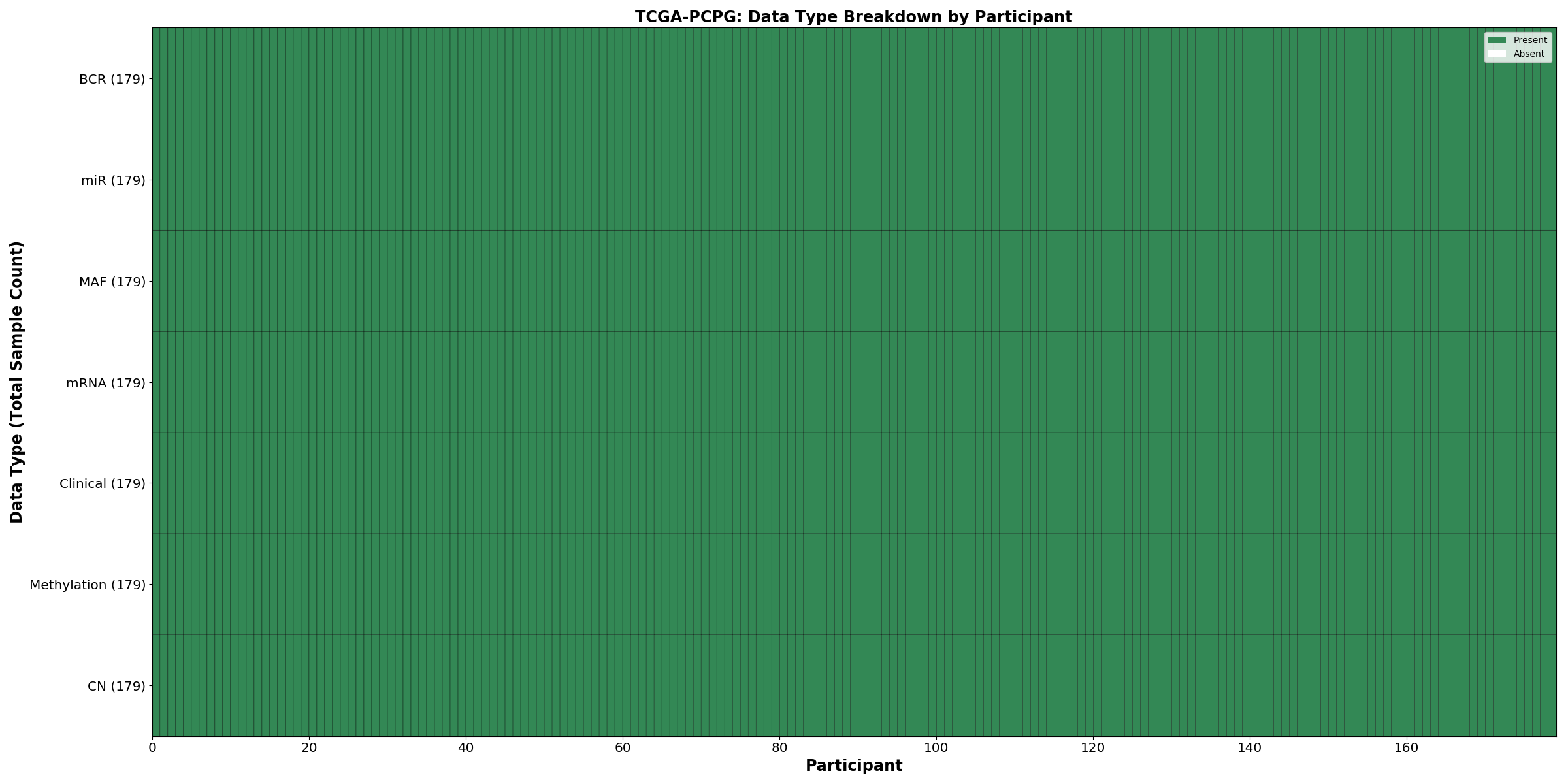
| PCPG | 179 | 179 | 178 | 178 | 179 | 179 | 179 |
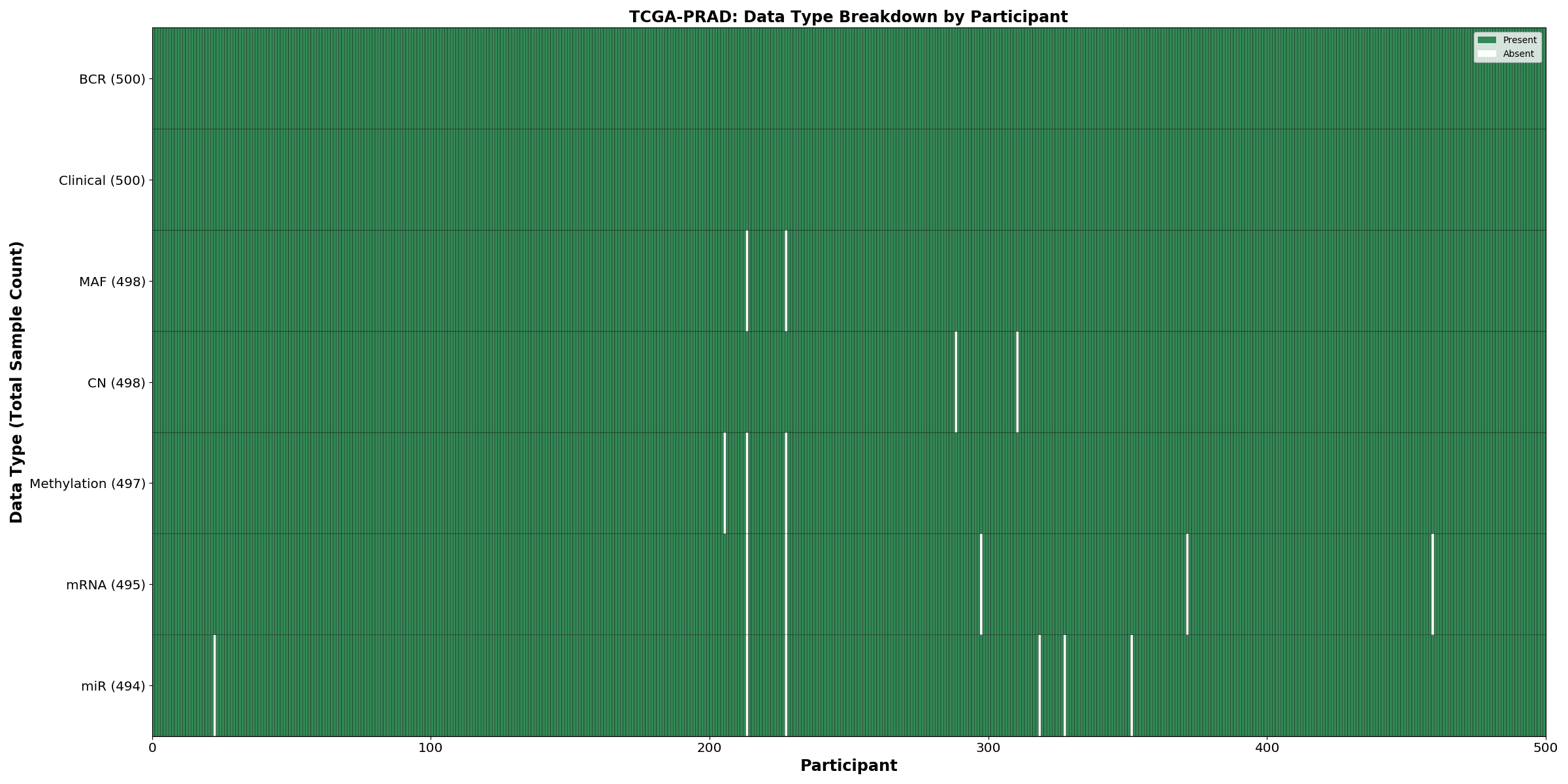
| PRAD | 500 | 500 | 495 | 495 | 494 | 498 | 497 |
| READ | 172 | 170 | 164 | 166 | 161 | 157 | 165 |
| SARC | 261 | 261 | 260 | 259 | 259 | 255 | 261 |
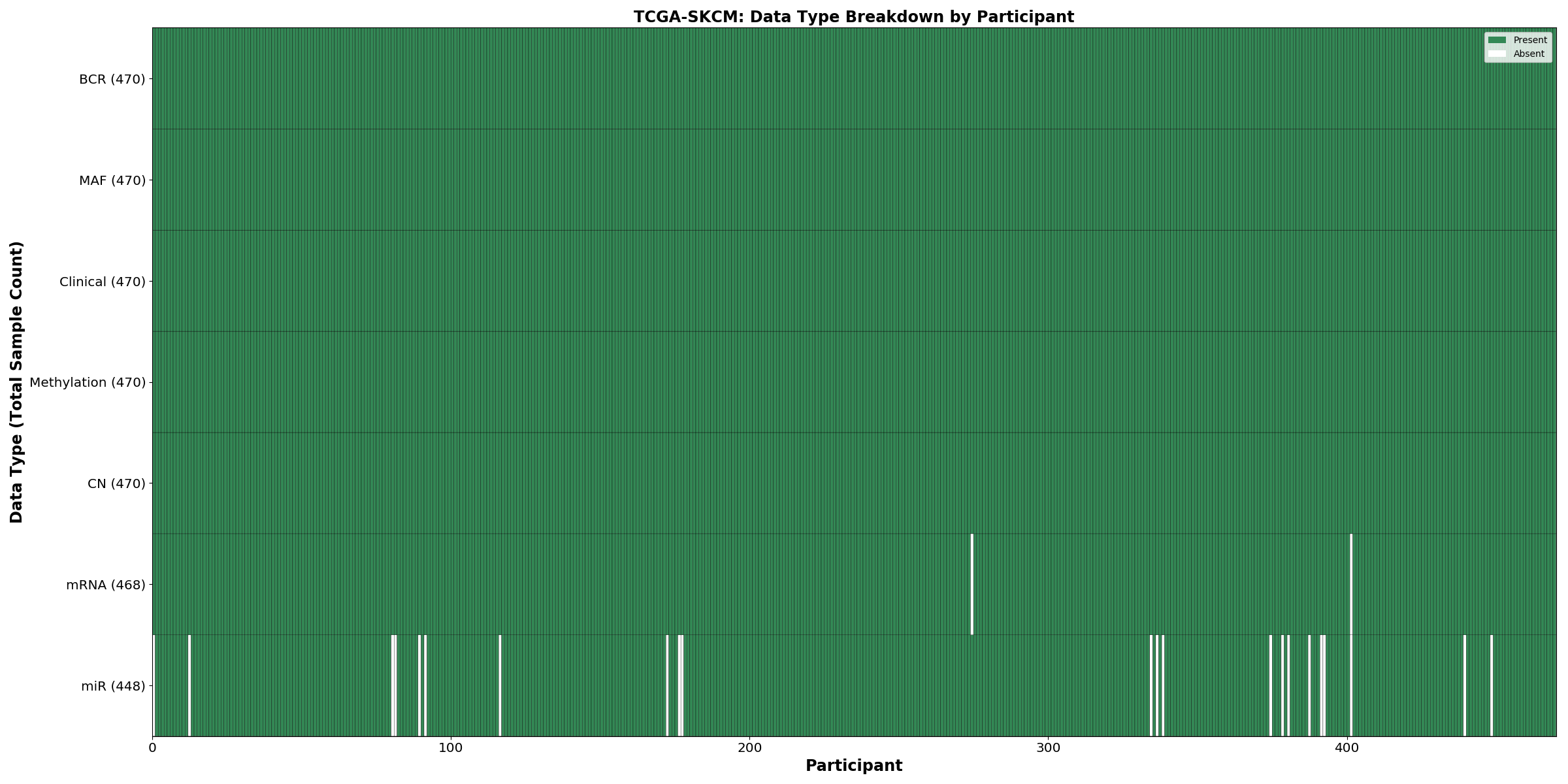
| SKCM | 470 | 470 | 368 | 367 | 352 | 368 | 368 |
| STAD | 443 | 443 | 442 | 375 | 436 | 441 | 443 |
| STES | 628 | 628 | 626 | 536 | 620 | 625 | 628 |
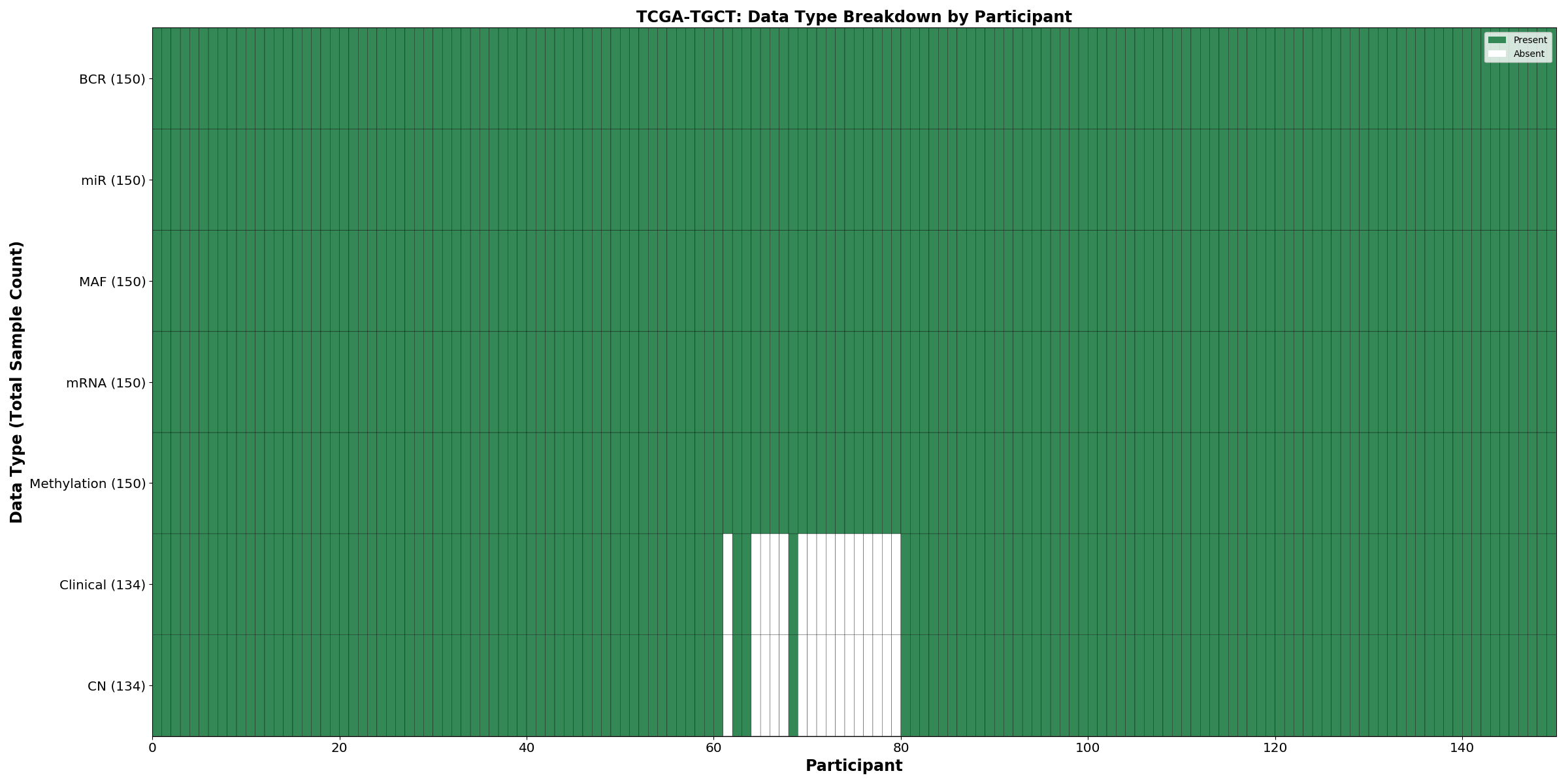
| TGCT | 150 | 134 | 134 | 150 | 150 | 150 | 150 |
| THCA | 506 | 506 | 505 | 502 | 506 | 496 | 506 |
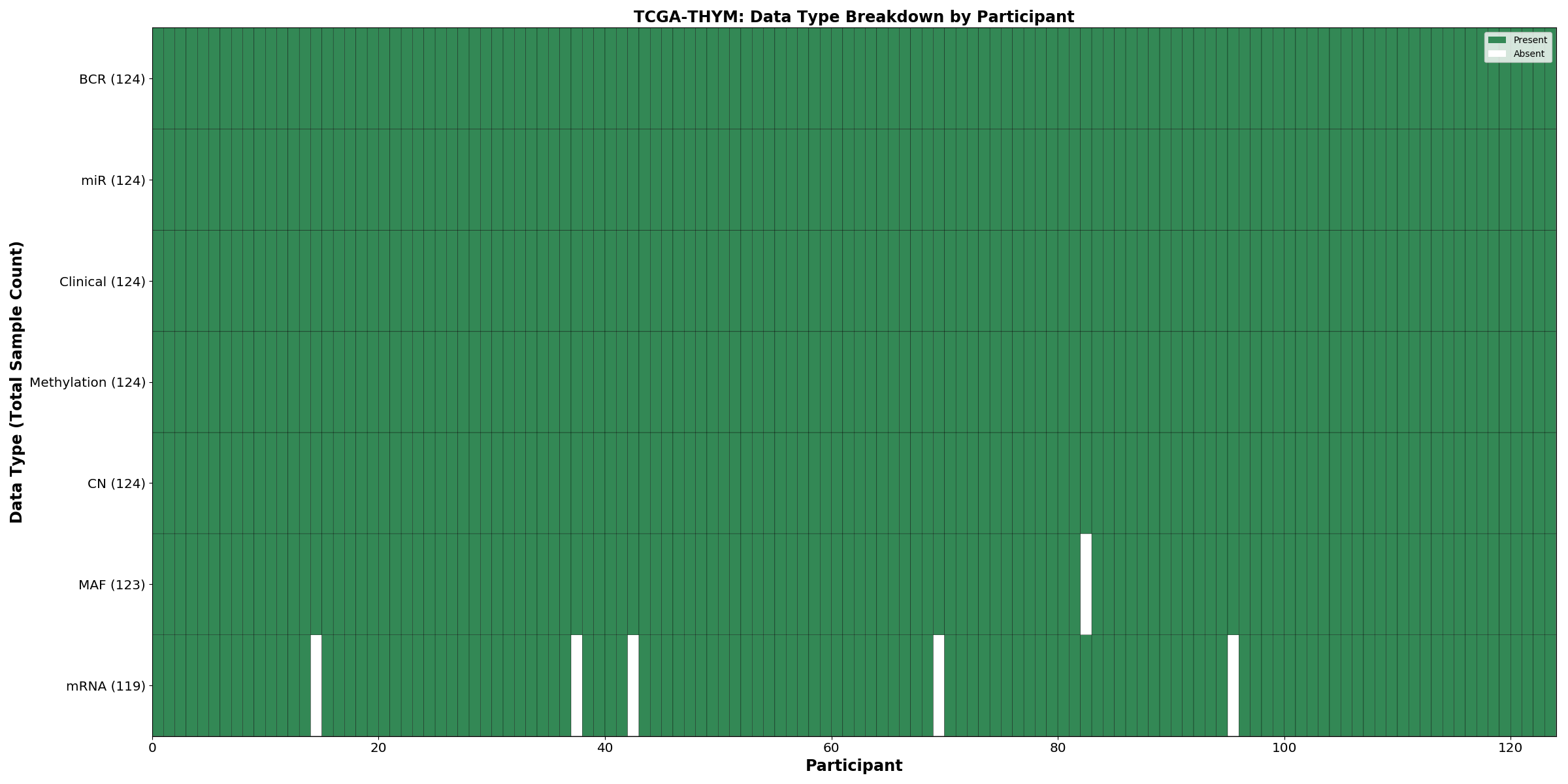
| THYM | 124 | 124 | 124 | 119 | 124 | 123 | 124 |
| UCEC | 559 | 547 | 540 | 543 | 538 | 542 | 546 |
| UCS | 57 | 57 | 56 | 56 | 57 | 57 | 57 |
| UVM | 80 | 80 | 80 | 80 | 80 | 80 | 80 |
| Totals | 11305 | 11150 | 10840 | 10088 | 10049 | 10323 | 10807 |
Figure 1. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}

Figure 2. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}

Figure 3. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
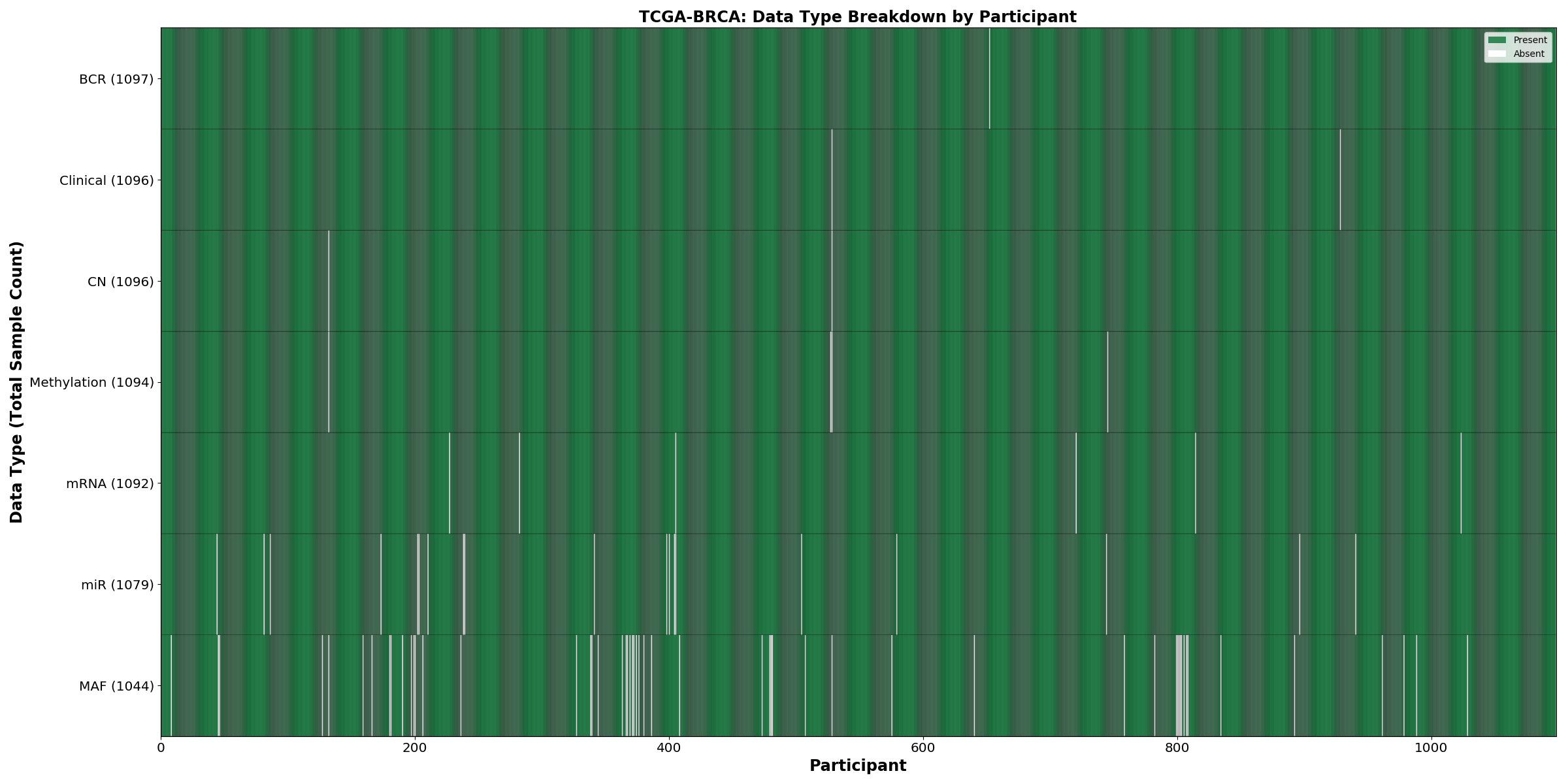{kind=link}

Figure 4. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}

Figure 5. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}

Figure 6. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
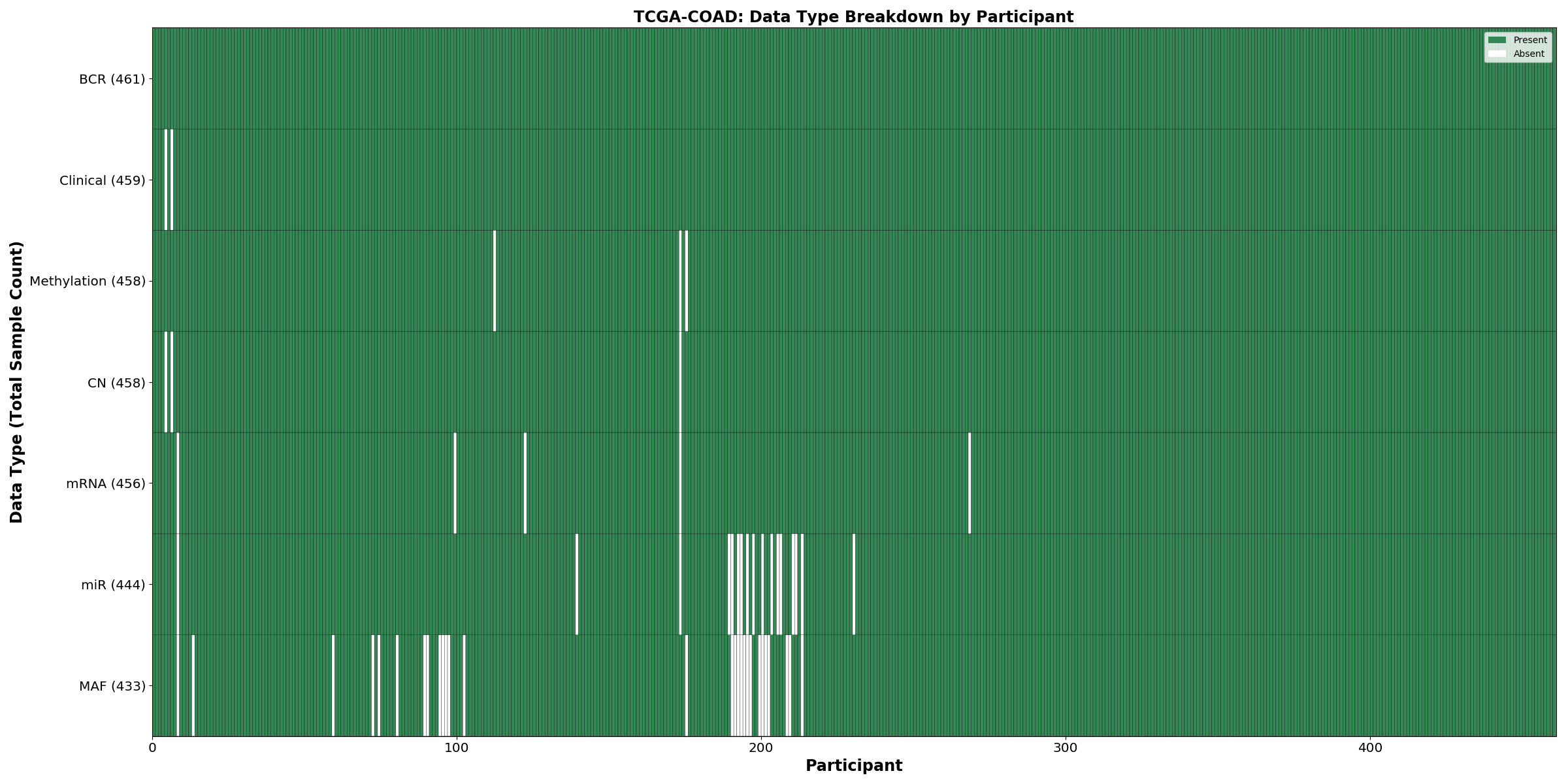{kind=link}

Figure 7. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}

Figure 8. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
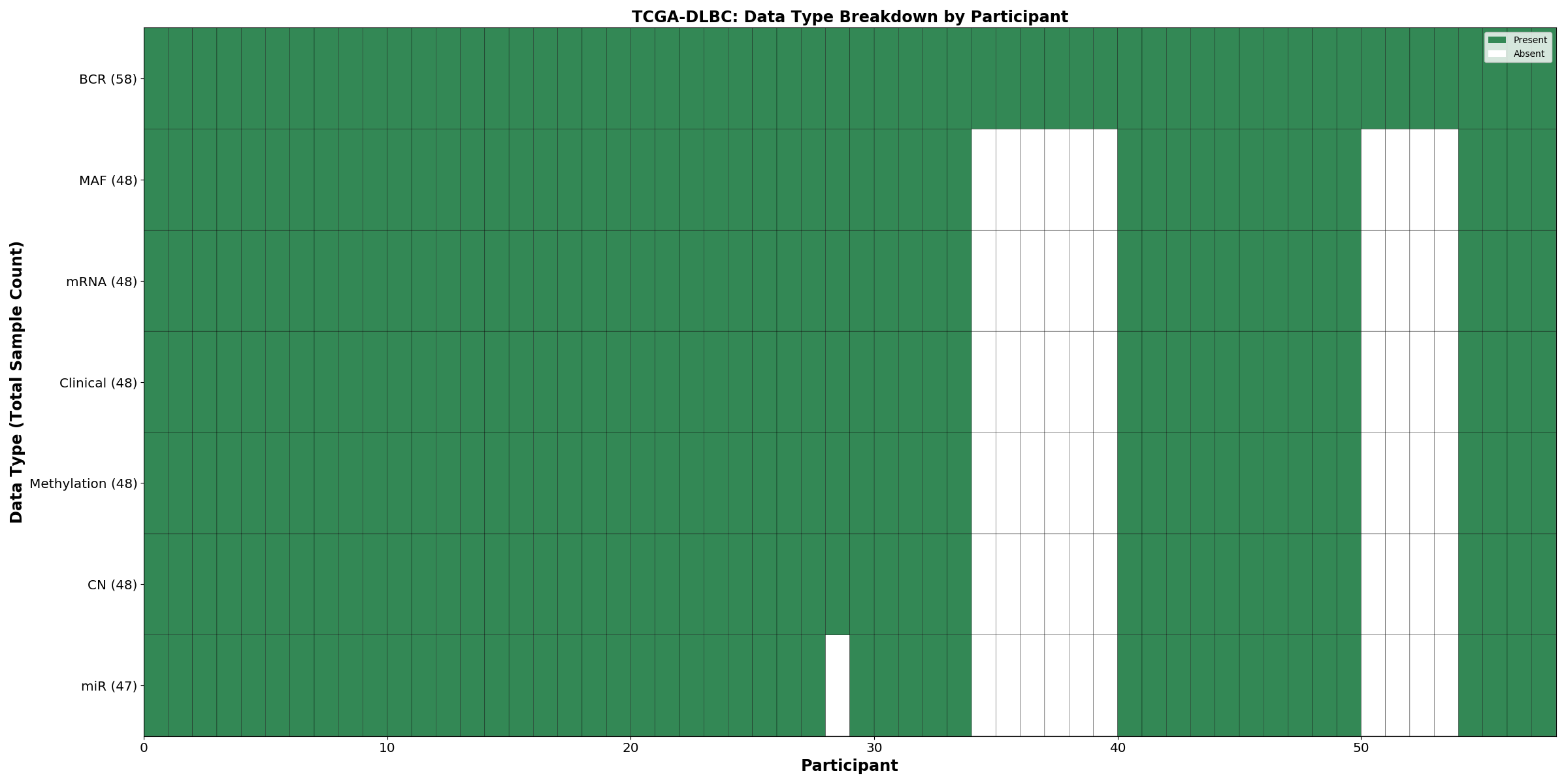{kind=link}

Figure 9. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
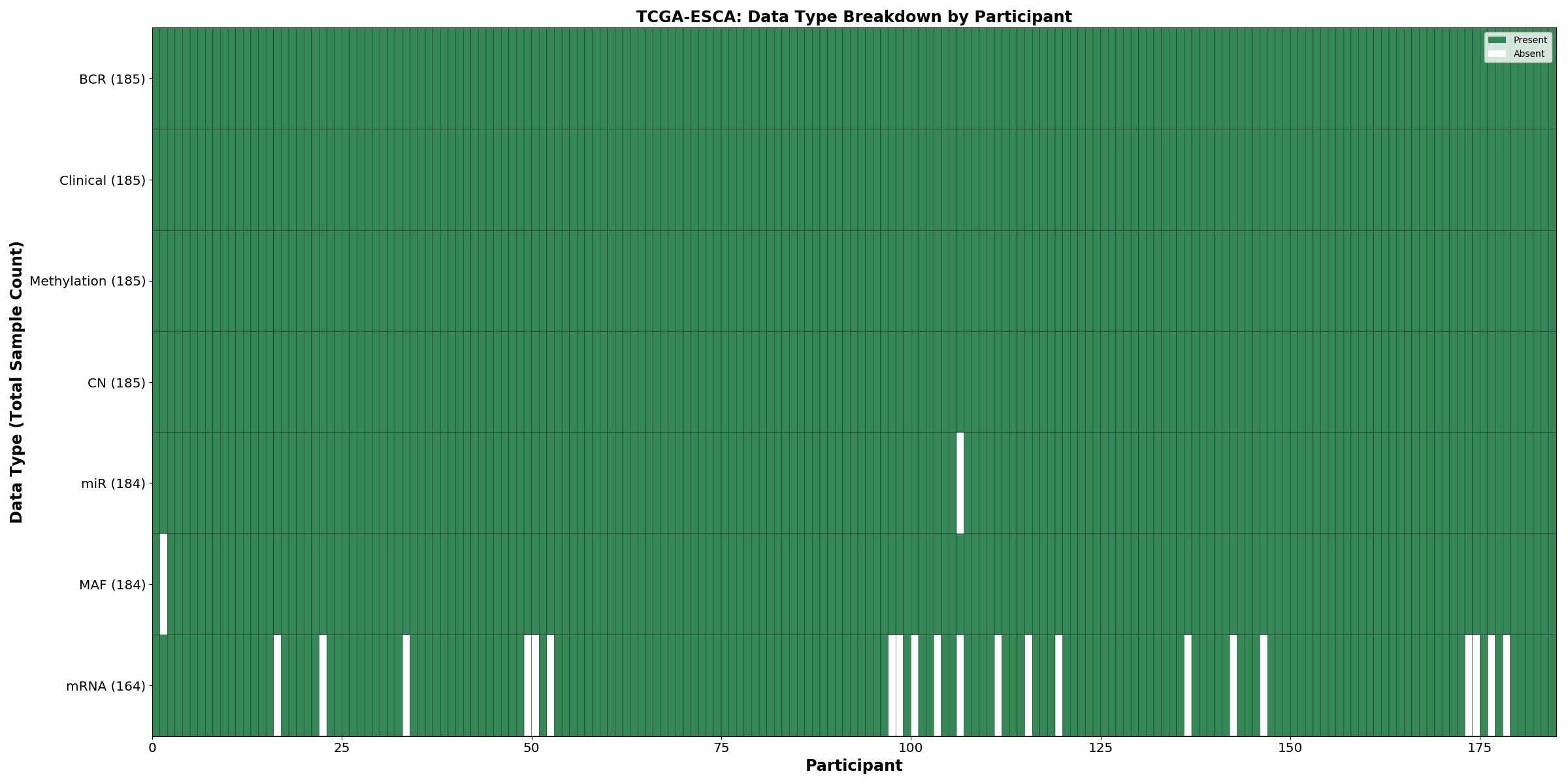{kind=link}

Figure 10. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
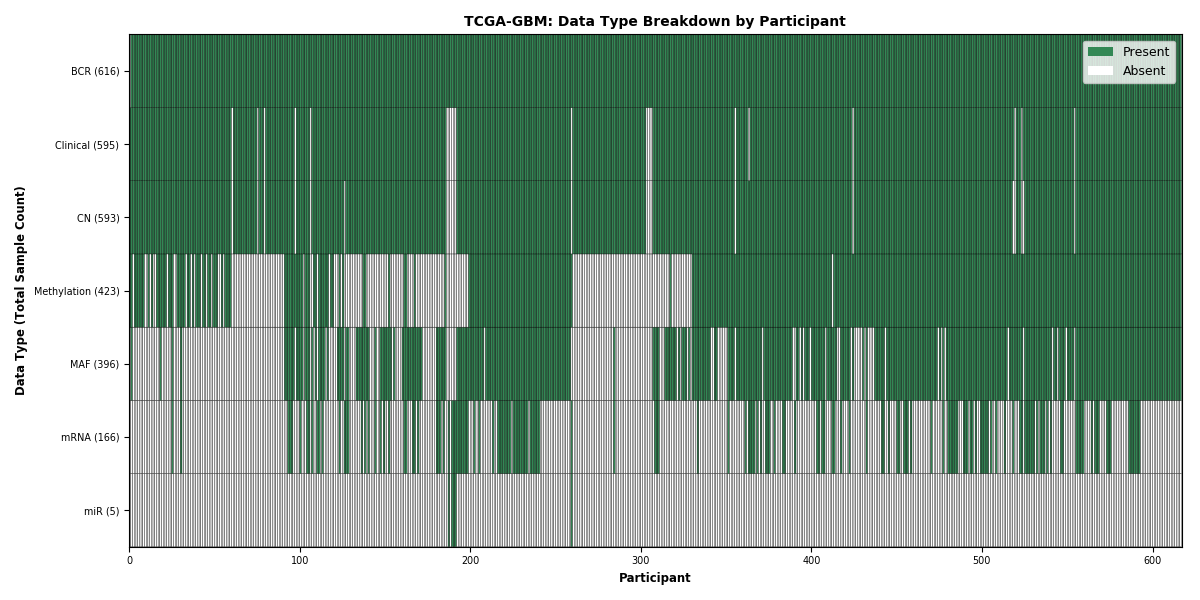
Figure 11. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}

Figure 12. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}

Figure 13. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
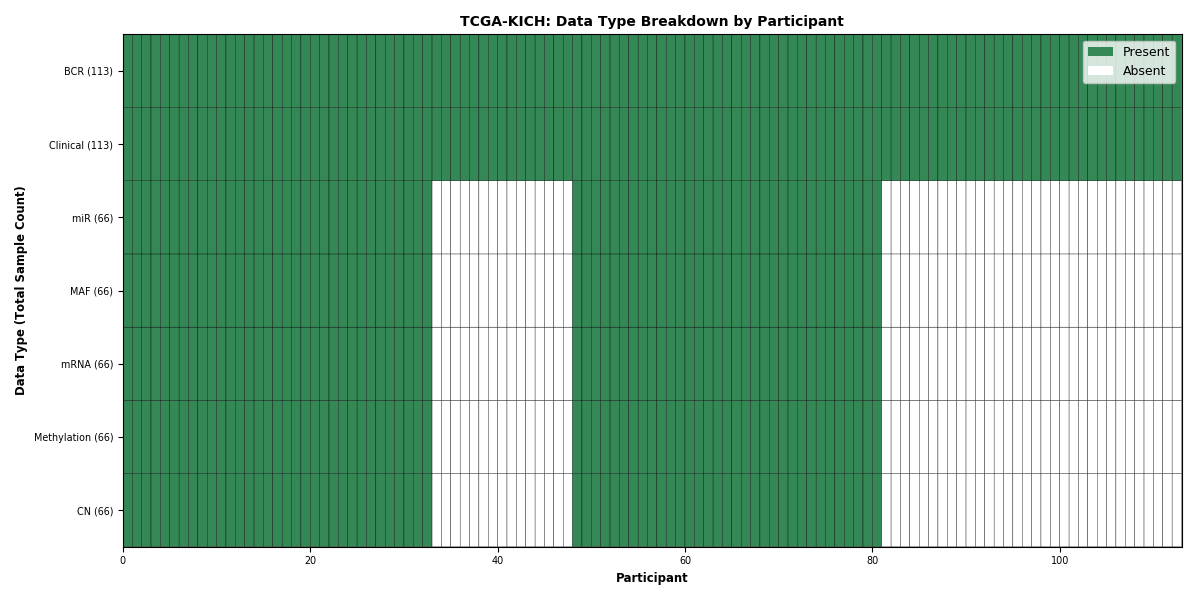
Figure 14. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}

Figure 15. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
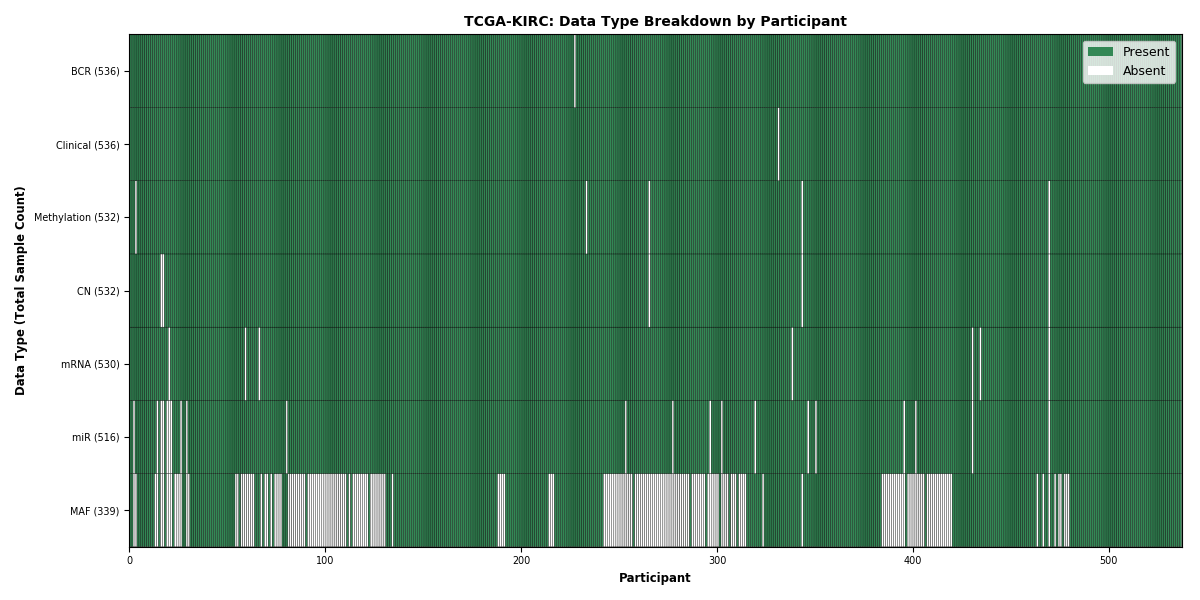
Figure 16. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}

Figure 17. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
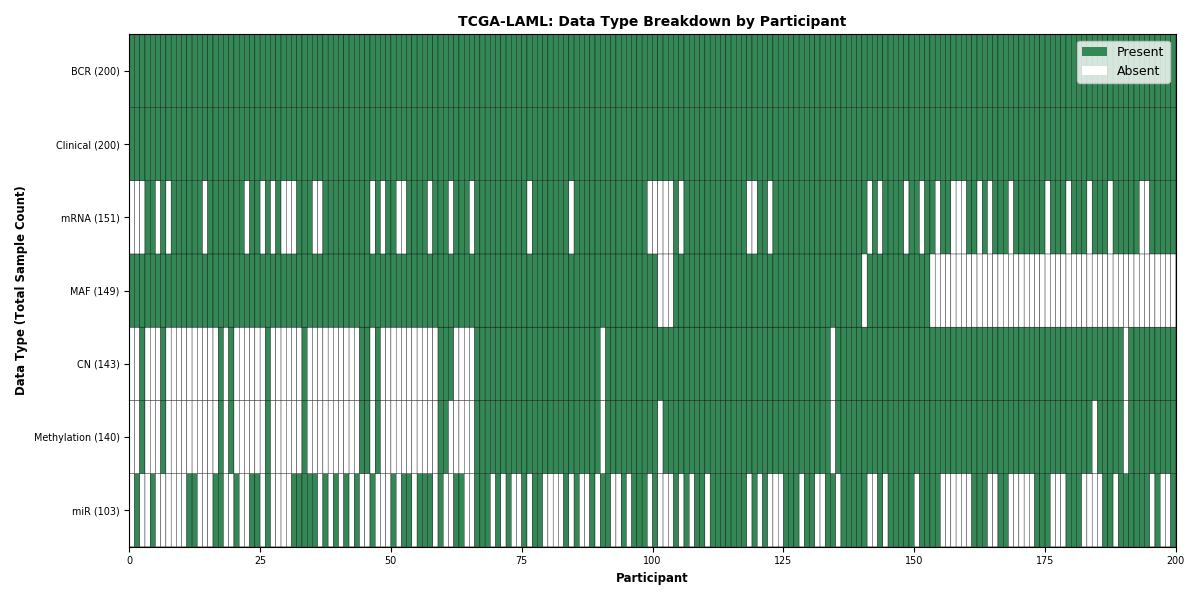
Figure 18. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}

Figure 19. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
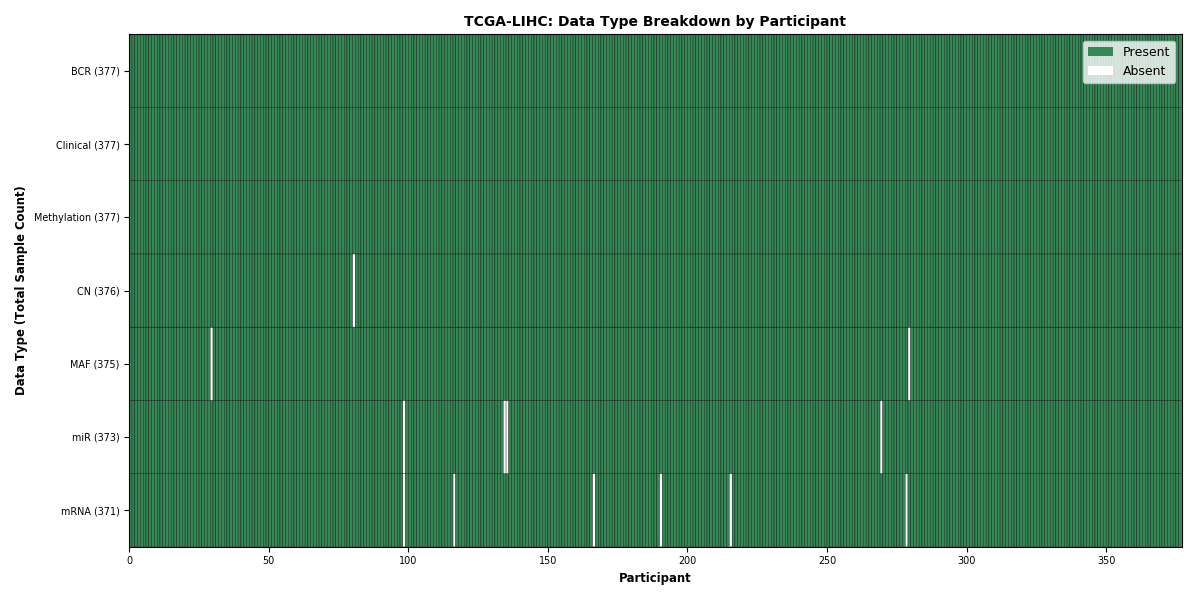
Figure 20. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}

Figure 21. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}

Figure 22. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
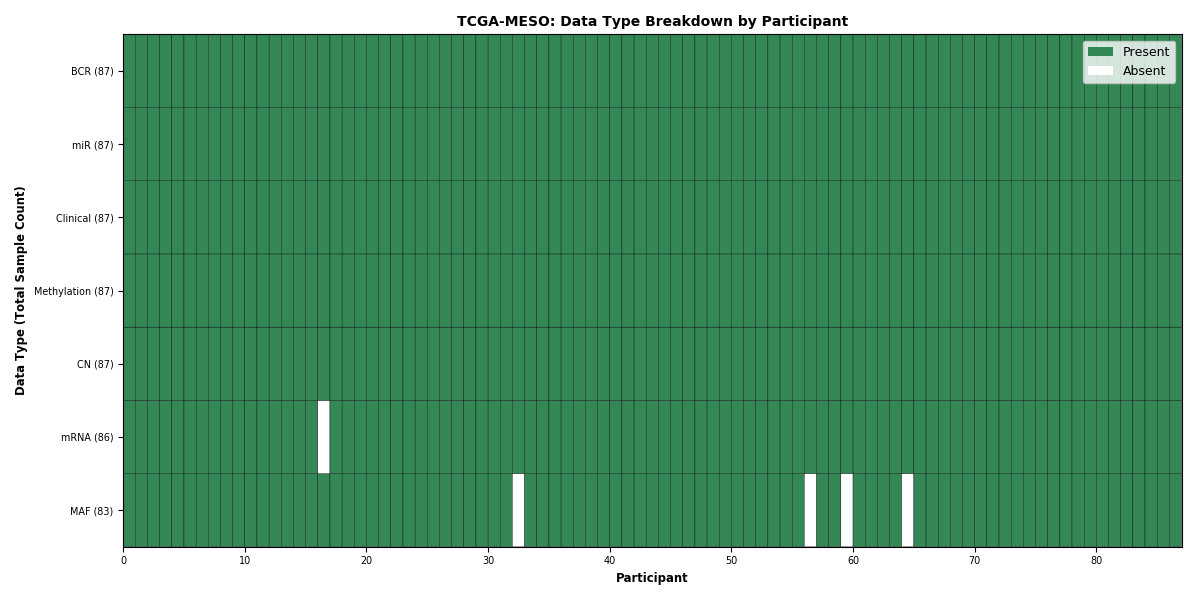
Figure 23. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
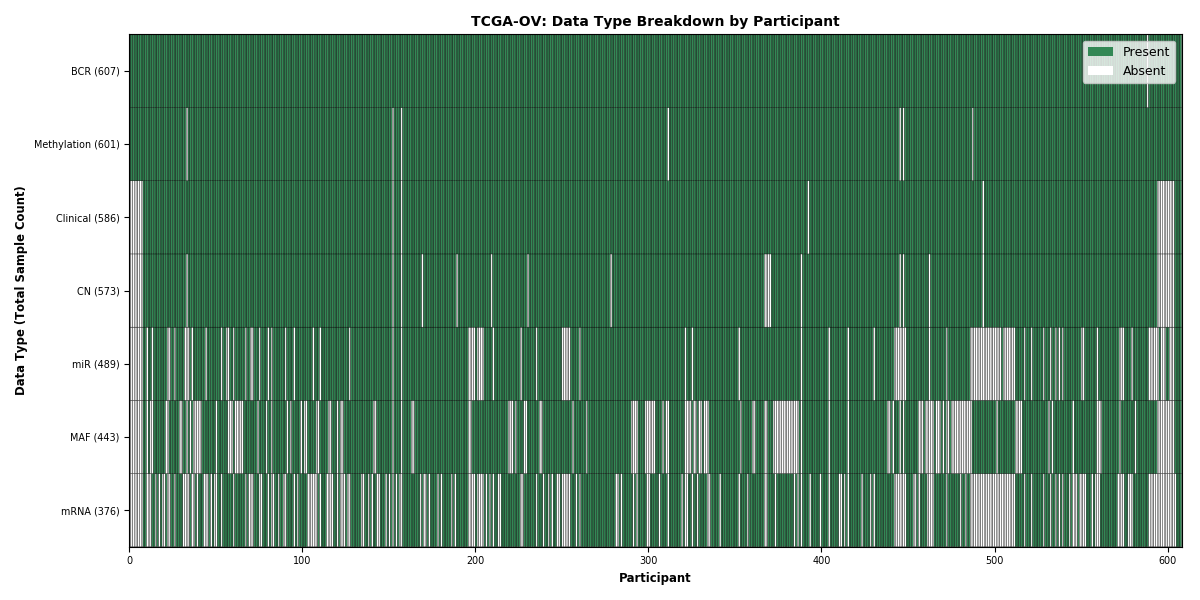
Figure 24. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}

Figure 25. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
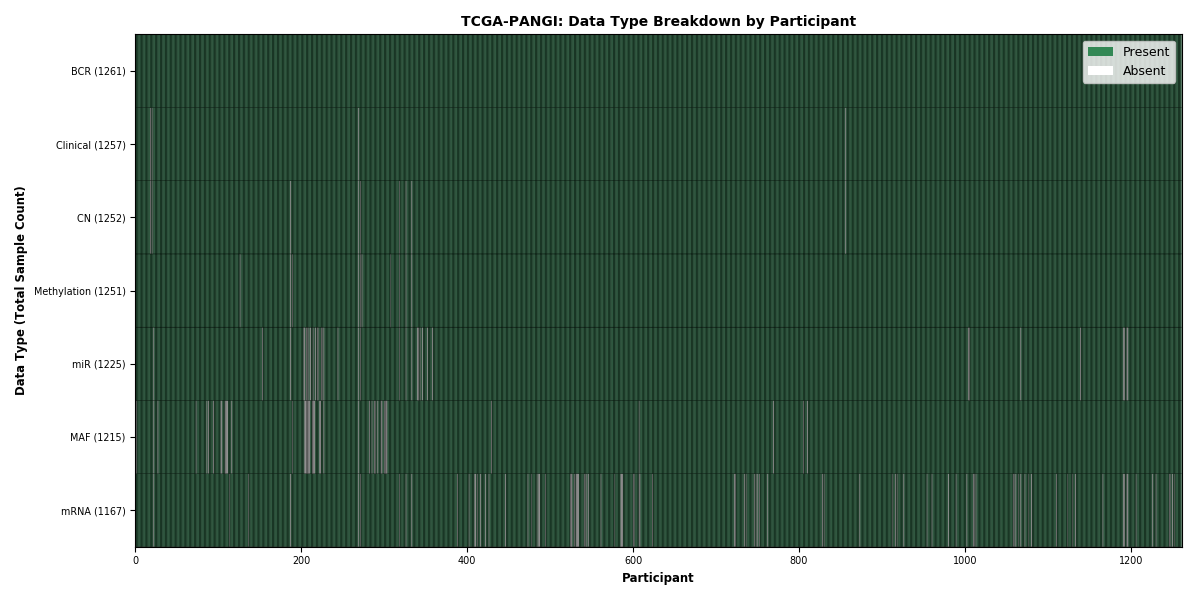
Figure 26. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
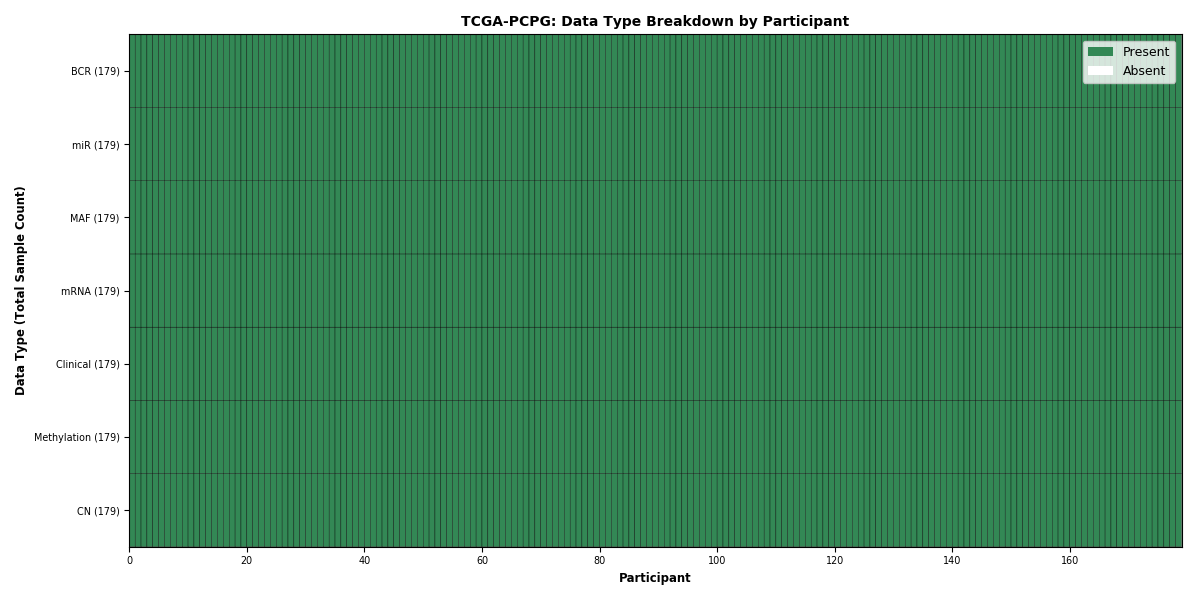
Figure 27. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}

Figure 28. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}

Figure 29. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}

Figure 30. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}

Figure 31. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}

Figure 32. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
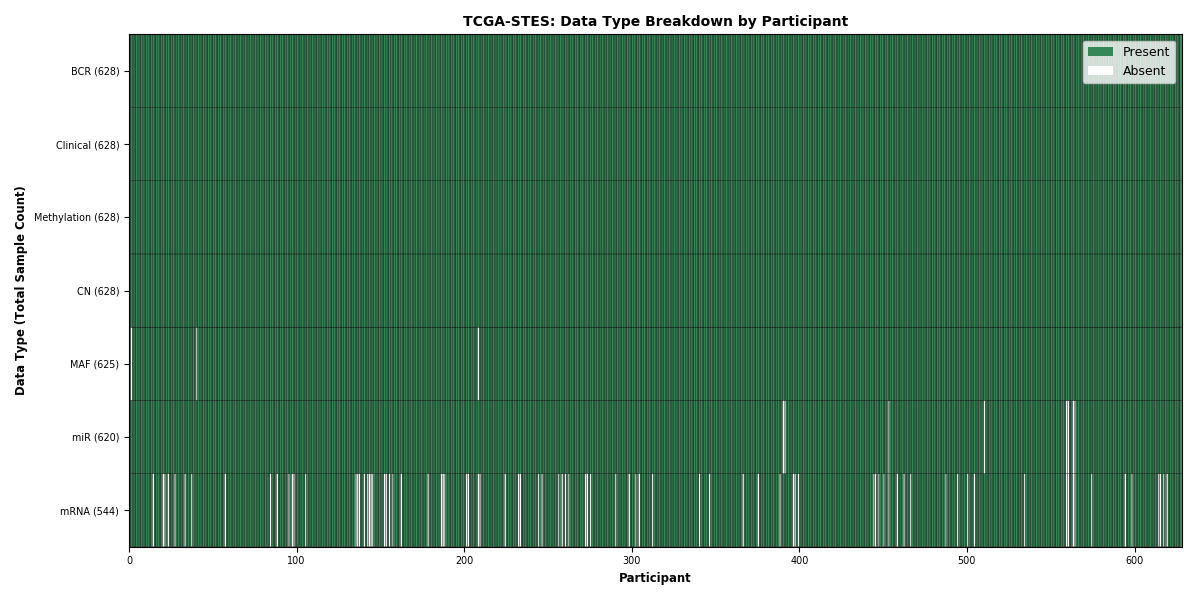
Figure 33. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
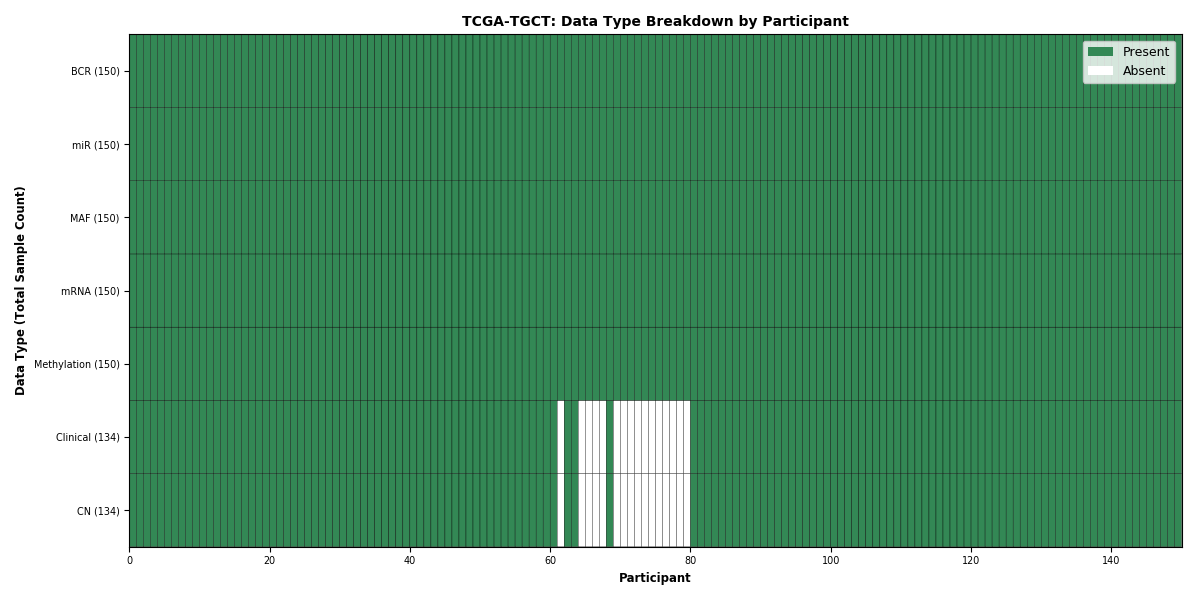
Figure 34. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
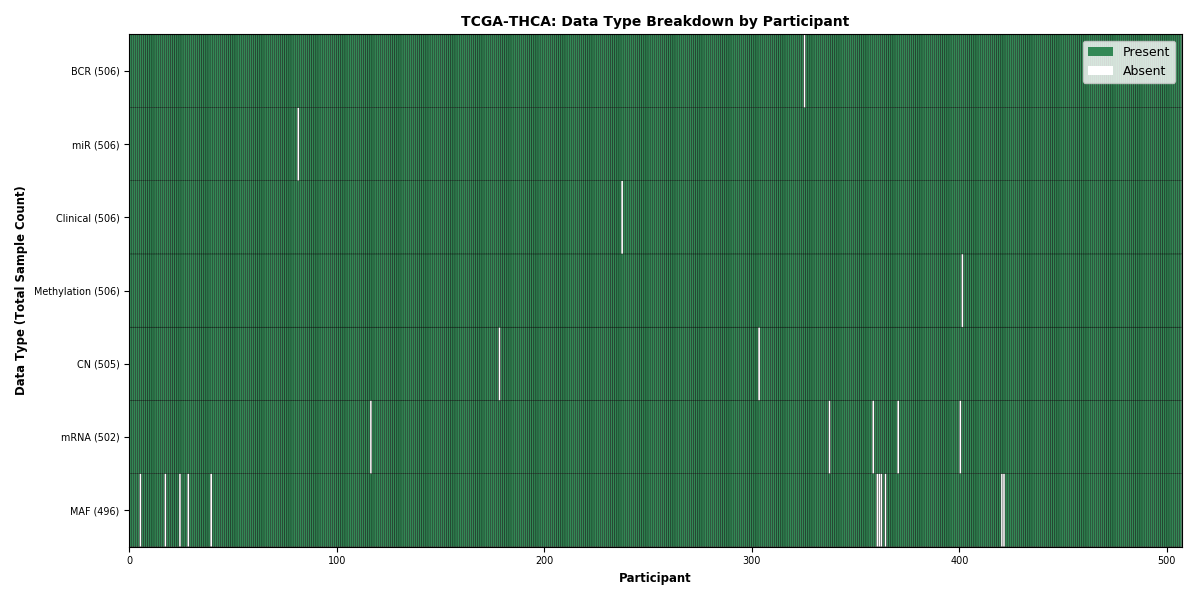
Figure 35. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}

Figure 36. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}

Figure 37. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
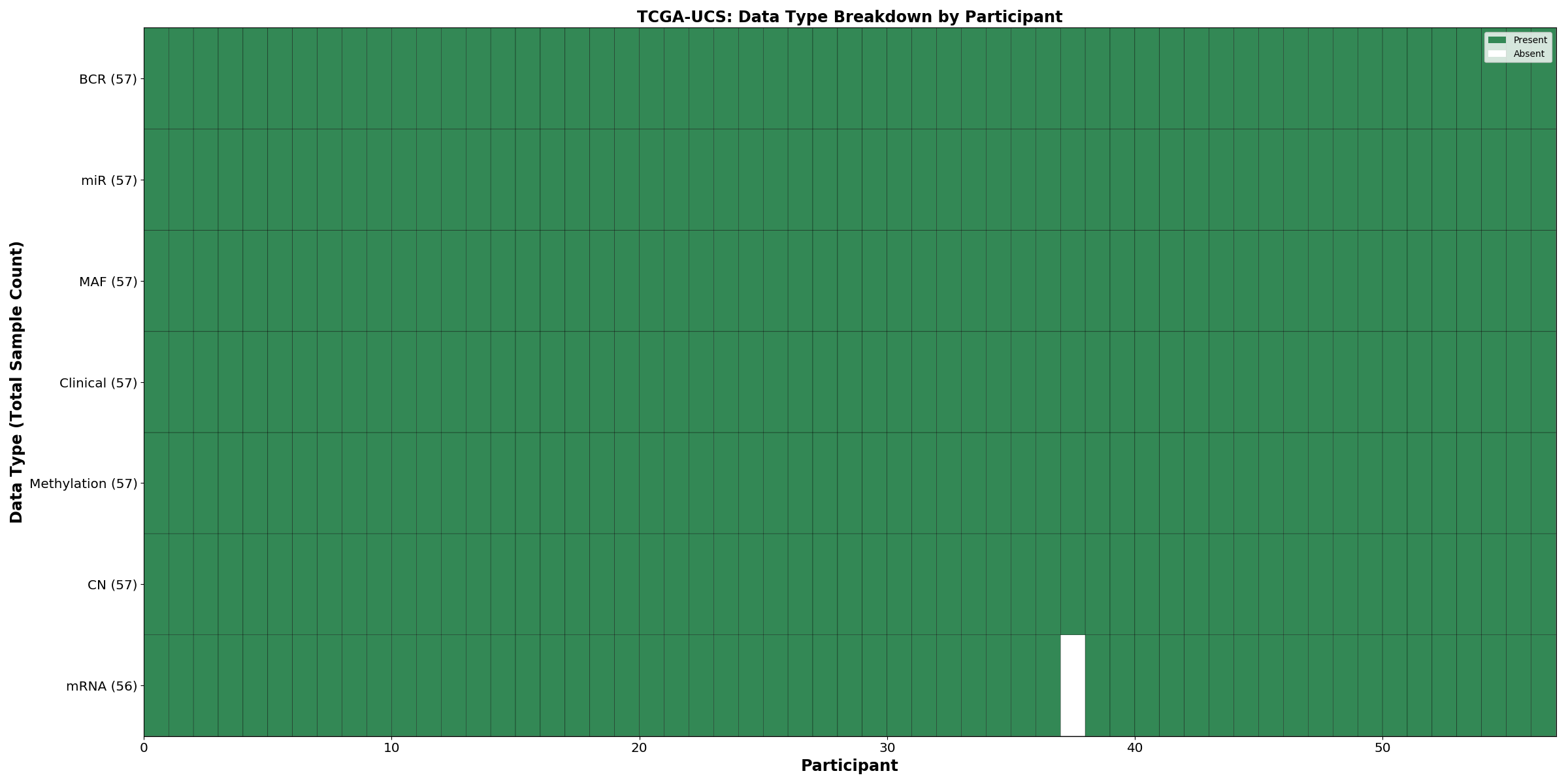{kind=link}

Figure 38. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
NOT IMPLEMENTED YET: redactions are not yet exposed at the GDC. For examples of the annotation-based filtering performed in the past by the Broad GDAC Firehose pipeline, explore this legacy GDAC Firehose sample report
The mRNA preprocess median module chooses the matrix for the platform(Affymetrix HG U133, Affymetrix Exon Array and Agilent Gene Expression) with the largest number of samples.
The mRNAseq preprocessor picks the "scaled_estimate" (RSEM) value from Illumina HiSeq/GA2 mRNAseq level_3 (v2) data set and makes the mRNAseq matrix with log2 transformed for the downstream analysis. If there are overlap samples between two different platforms, samples from illumina hiseq will be selected. The pipeline also creates the matrix with RPKM and log2 transform from HiSeq/GA2 mRNAseq level 3 (v1) data set.
The miRseq preprocessor picks the "RPM" (reads per million miRNA precursor reads) from the Illumina HiSeq/GA miRseq Level_3 data set and makes the matrix with log2 transformed values.
The methylation preprocessor filters methylation data for use in downstream pipelines. To learn more about this preprocessor, please visit the documentation.