The Broad GDAC mirrors data from the DCC on a daily basis. Although all data is mirrored, not every sample is ingested into Firehose. There are three main mechanisms that filter samples to ensure that only the most scientifically relevant samples make it into our standard data and analyses runs. These three mechanisms are redactions, replicate filtering, and blacklisting. This report summarizes the data that is ingested into Firehose, describes the three filtering mechanisms, lists those samples that are removed, and gives all available annotations from the DCC's Annotation Manager.
There were 159 redactions, 3165 replicate aliquots, 23 blacklisted aliquots, and 684 FFPE aliquots. The table below represents the sample counts for those samples that were ingested into firehose after filtering out redactions, replicates, and blacklisted data, and segregating FFPEs.
Table 1. Get Full Table Summary of TCGA Tumor Data. Click on a tumor type to display a tumor type specific Samples Report.
| Cohort | BCR | Clinical | CN | LowP | Methylation | mRNA | mRNASeq | miR | miRSeq | RPPA | MAF |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ACC | 92 | 92 | 90 | 0 | 80 | 0 | 79 | 0 | 80 | 46 | 90 |
| BLCA | 412 | 318 | 410 | 112 | 367 | 0 | 407 | 0 | 409 | 127 | 130 |
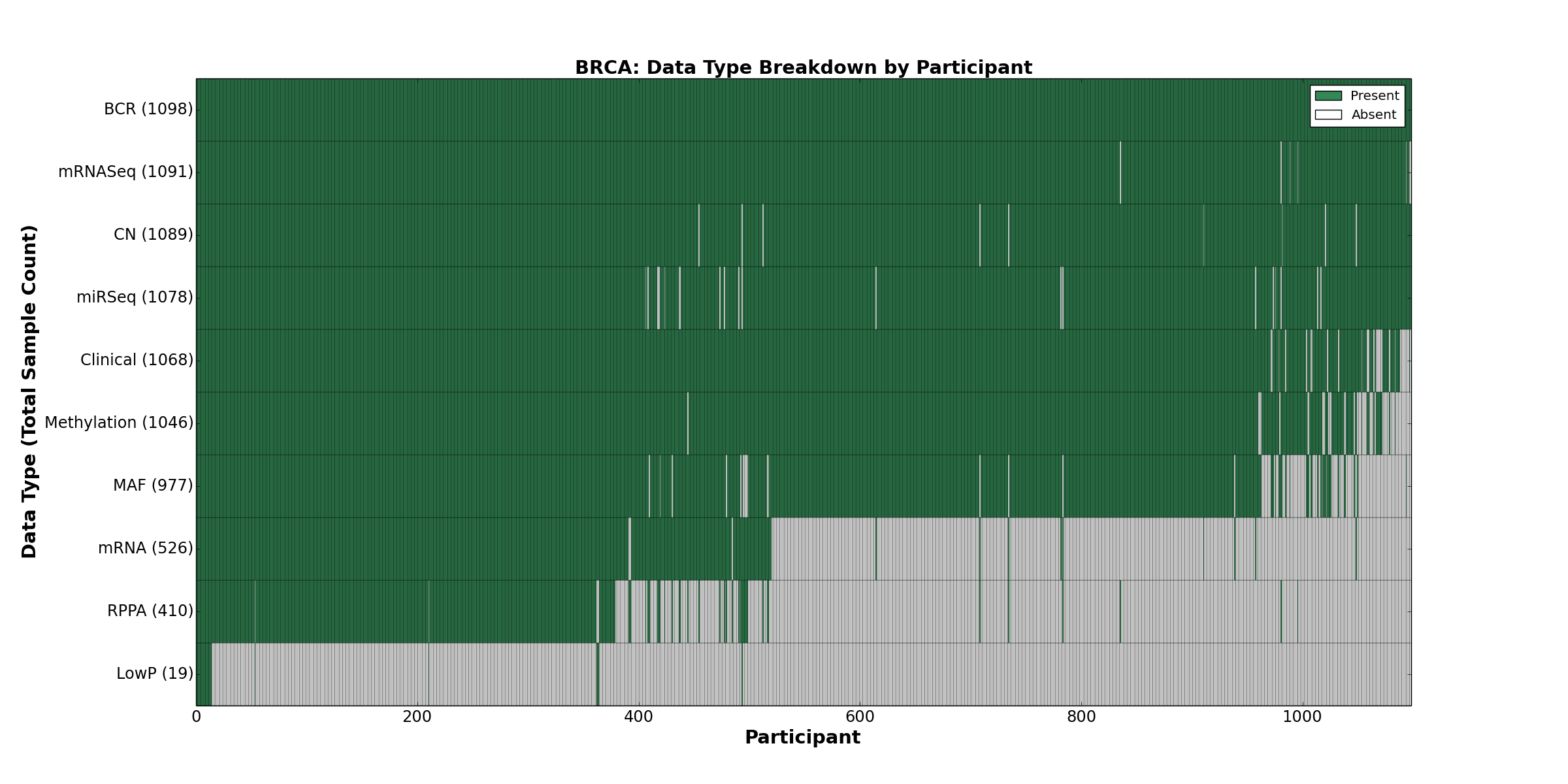
| BRCA | 1098 | 1068 | 1089 | 19 | 1046 | 526 | 1091 | 0 | 1078 | 410 | 977 |
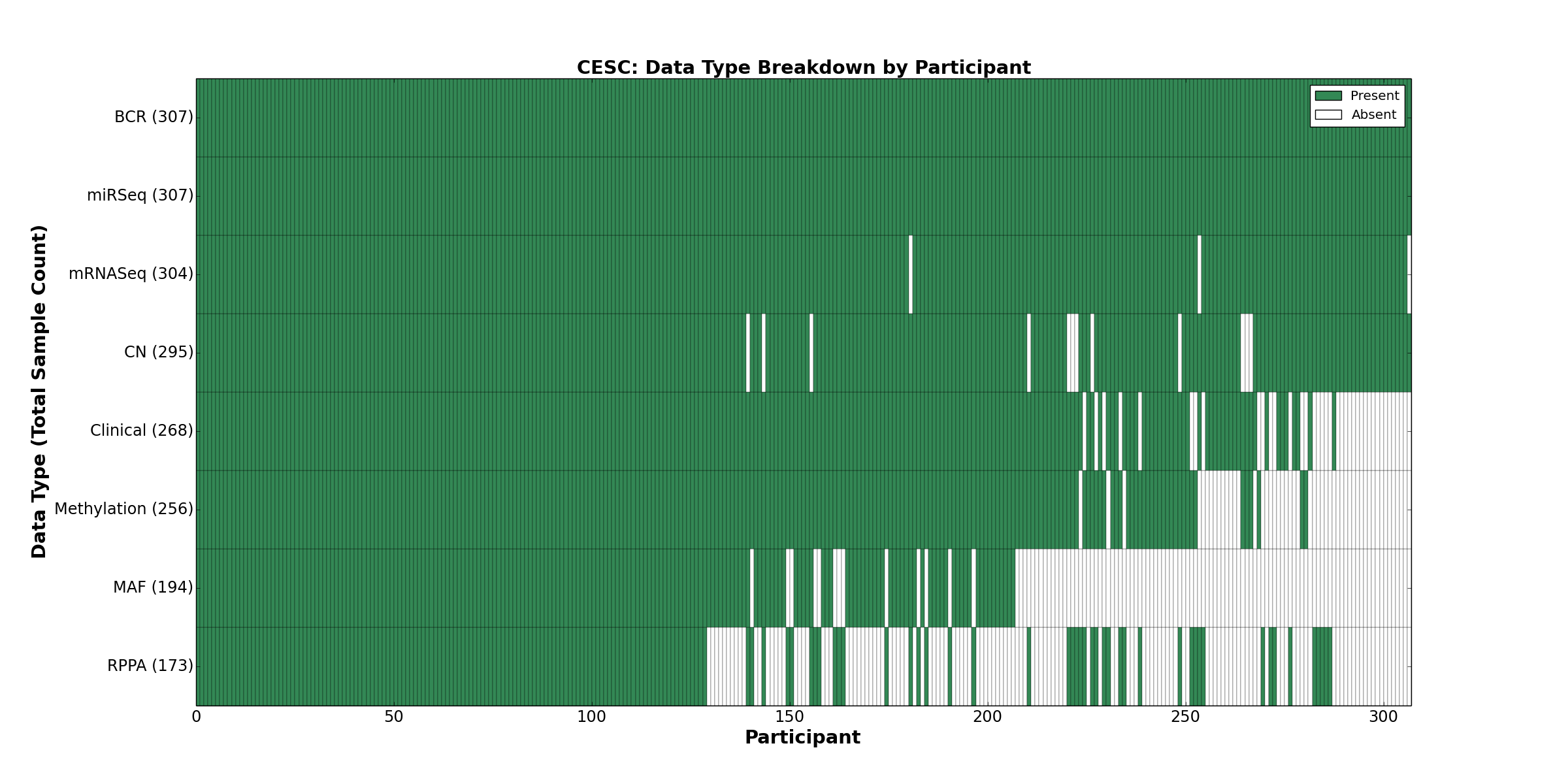
| CESC | 307 | 268 | 295 | 0 | 256 | 0 | 304 | 0 | 307 | 173 | 194 |
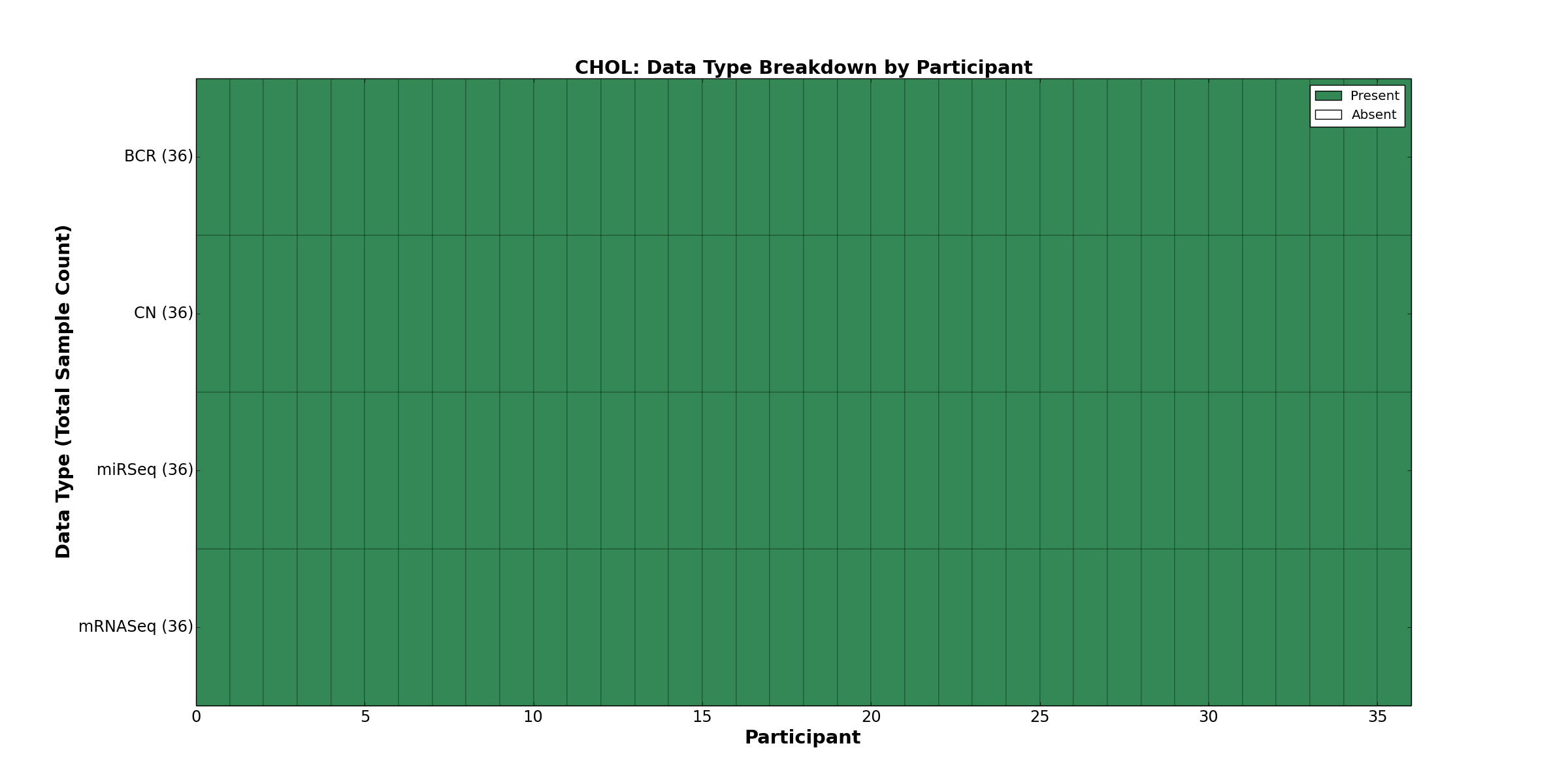
| CHOL | 36 | 0 | 36 | 0 | 0 | 0 | 36 | 0 | 36 | 0 | 0 |
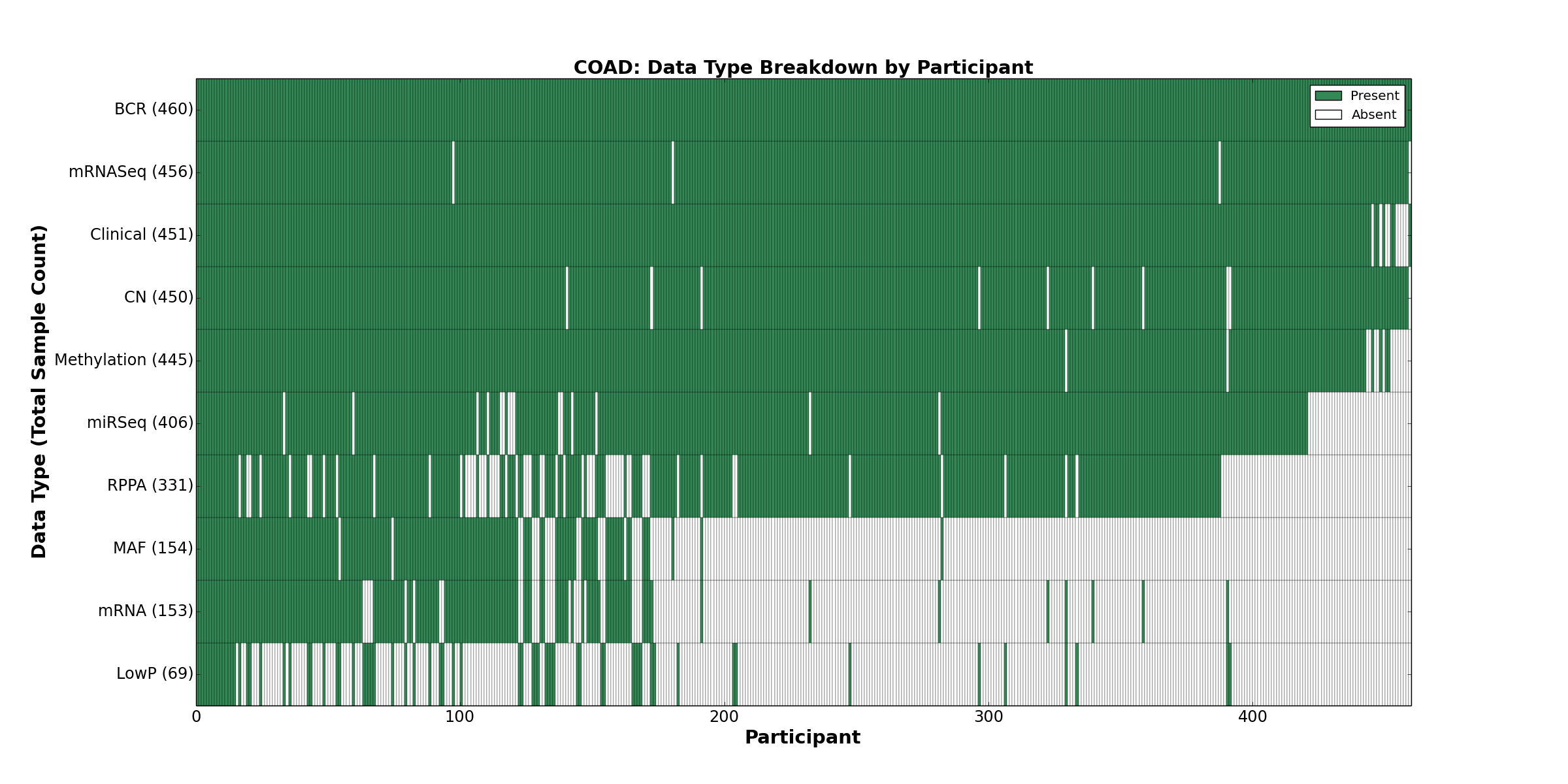
| COAD | 460 | 451 | 450 | 69 | 445 | 153 | 456 | 0 | 406 | 331 | 154 |
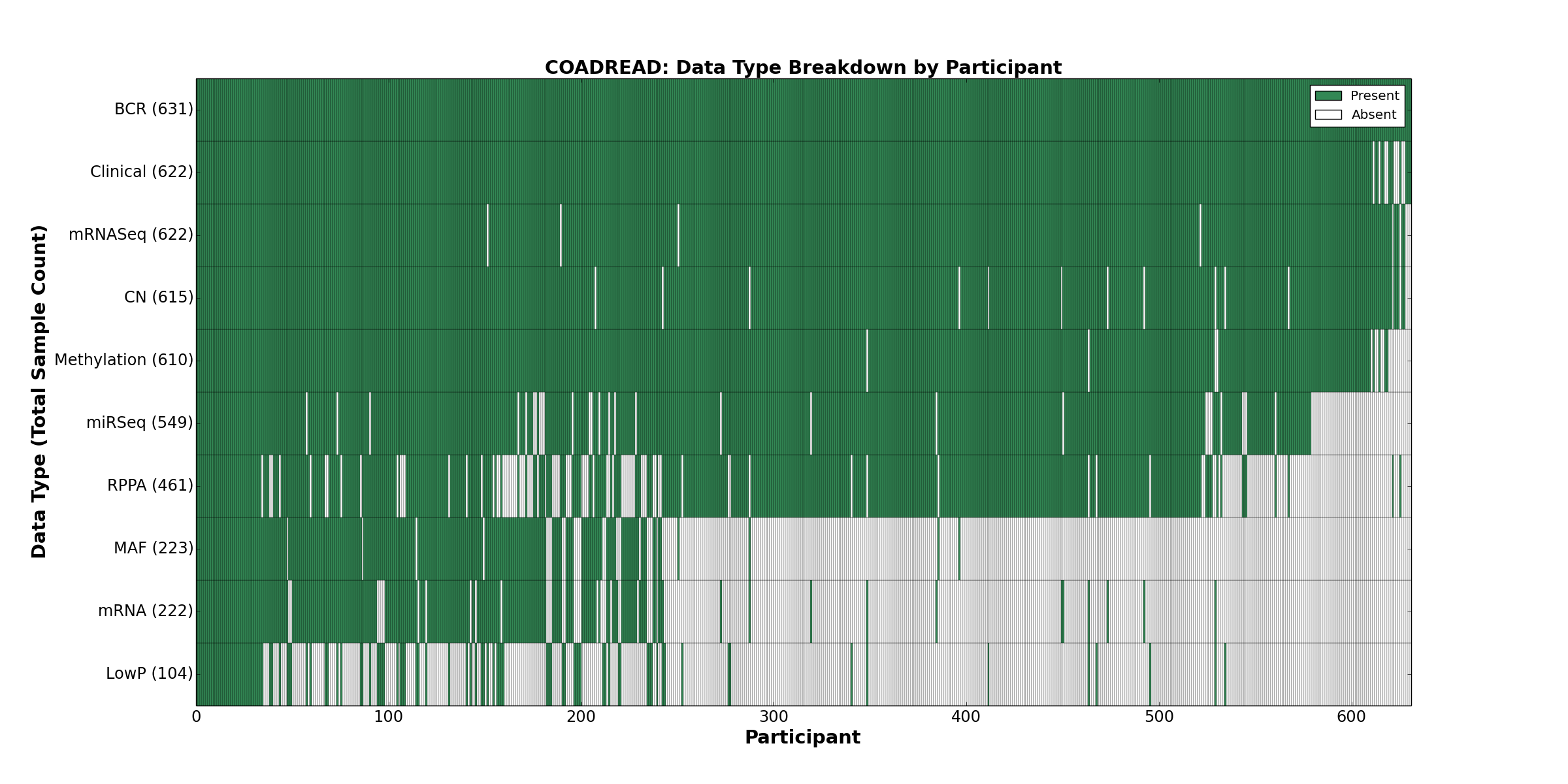
| COADREAD | 631 | 622 | 615 | 104 | 610 | 222 | 622 | 0 | 549 | 461 | 223 |
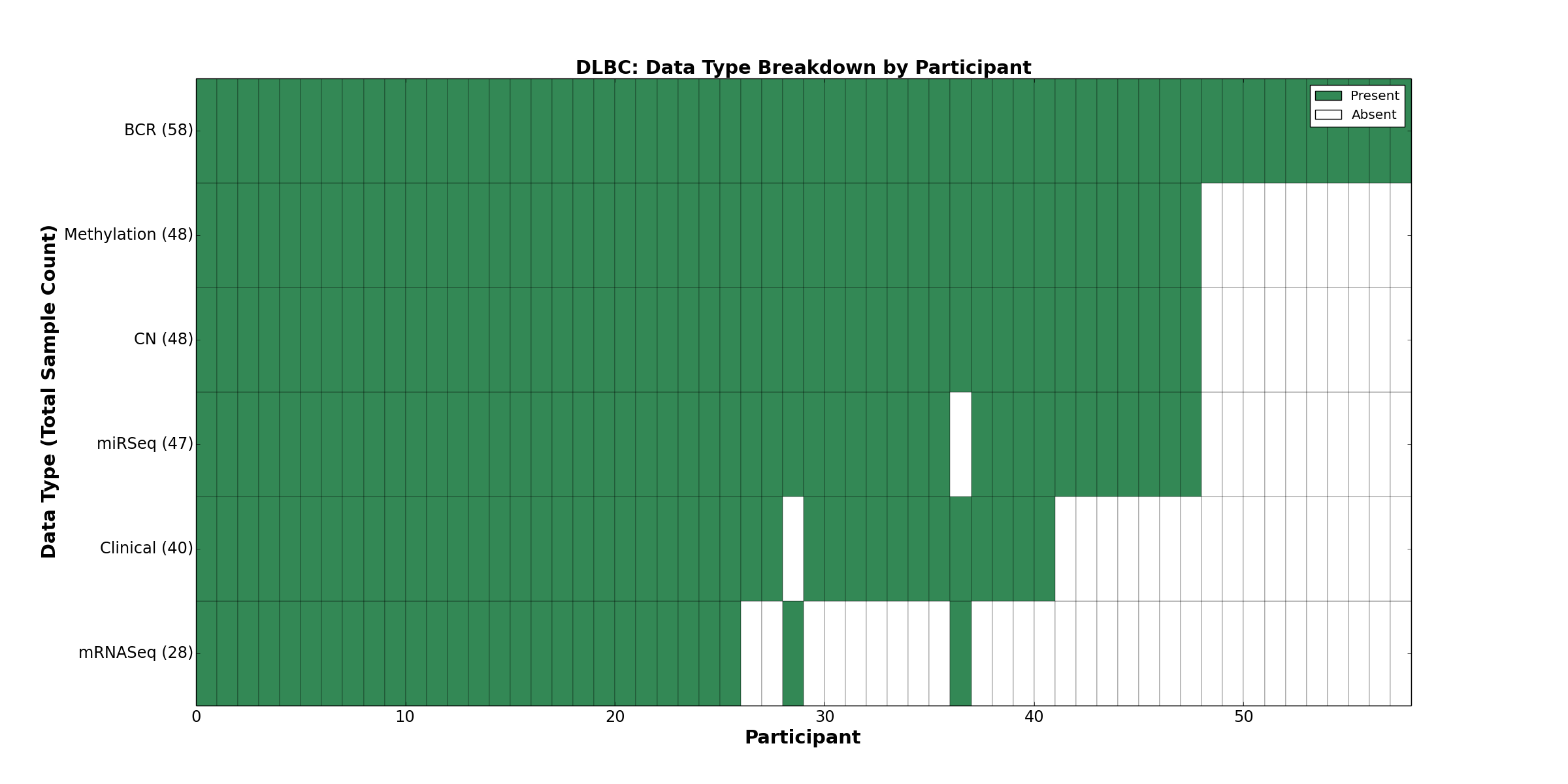
| DLBC | 58 | 40 | 48 | 0 | 48 | 0 | 28 | 0 | 47 | 0 | 0 |
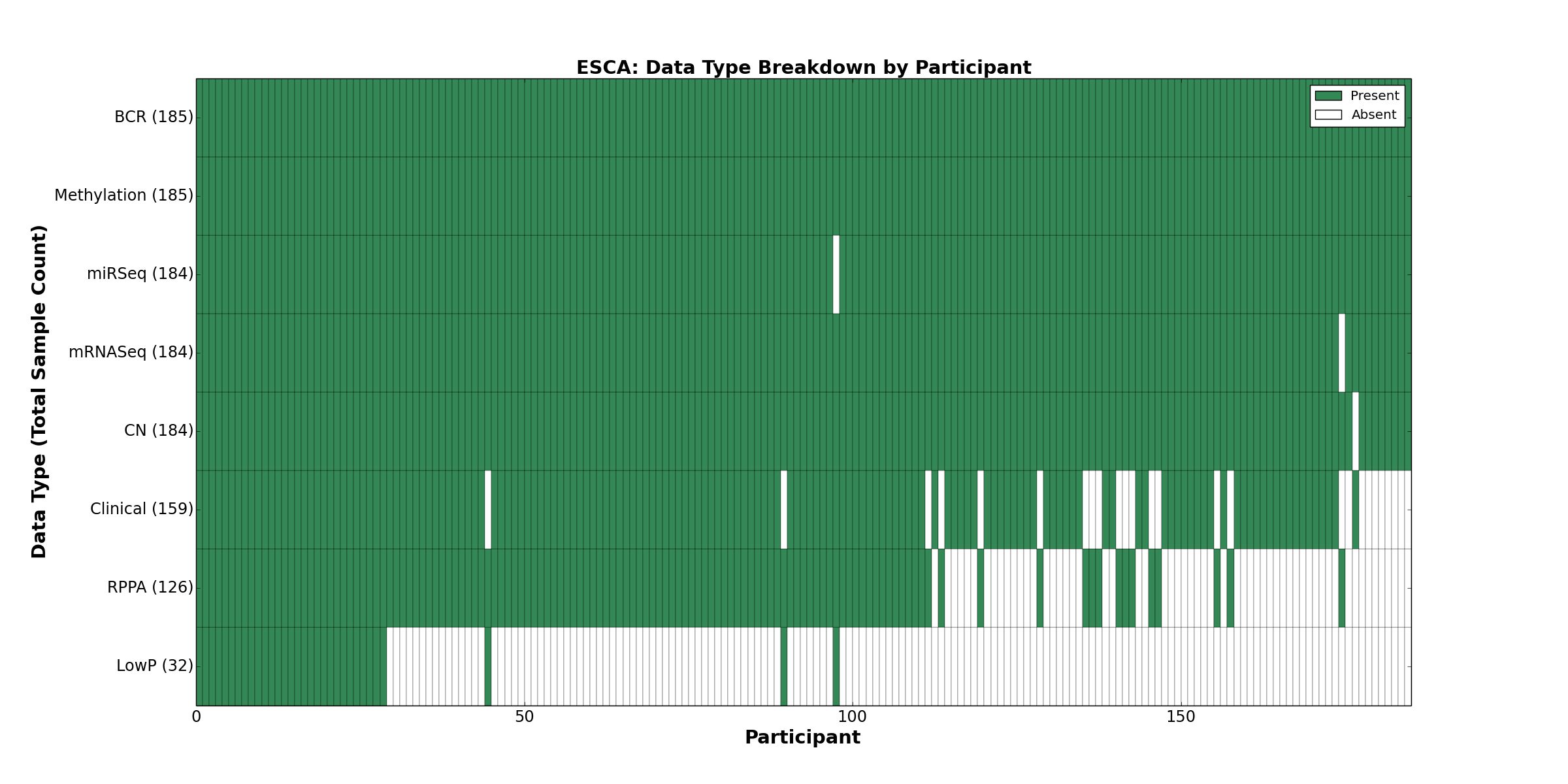
| ESCA | 185 | 159 | 184 | 32 | 185 | 0 | 184 | 0 | 184 | 126 | 0 |
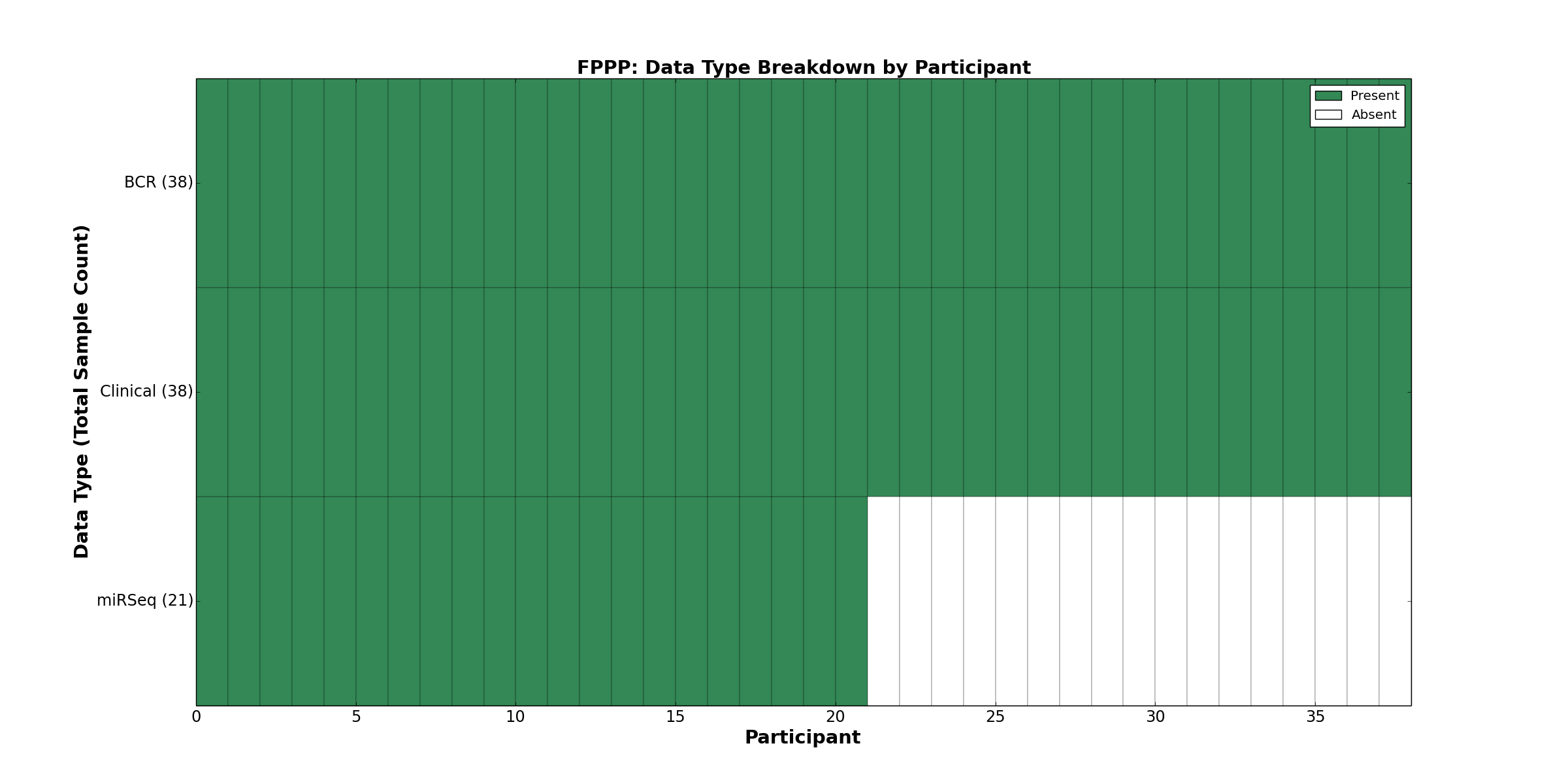
| FPPP | 38 | 38 | 0 | 0 | 0 | 0 | 0 | 0 | 21 | 0 | 0 |
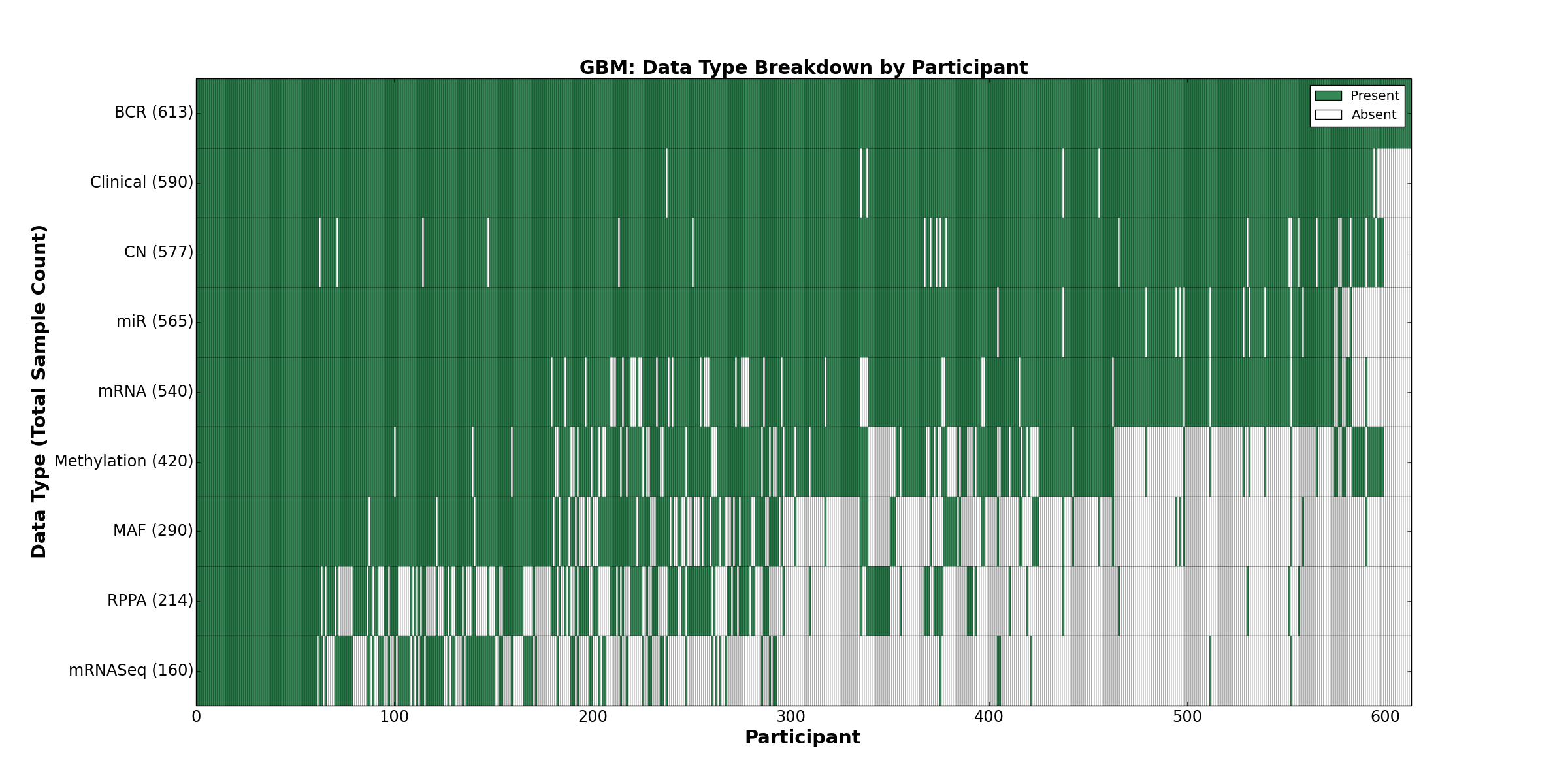
| GBM | 613 | 590 | 577 | 0 | 420 | 540 | 160 | 565 | 0 | 214 | 290 |
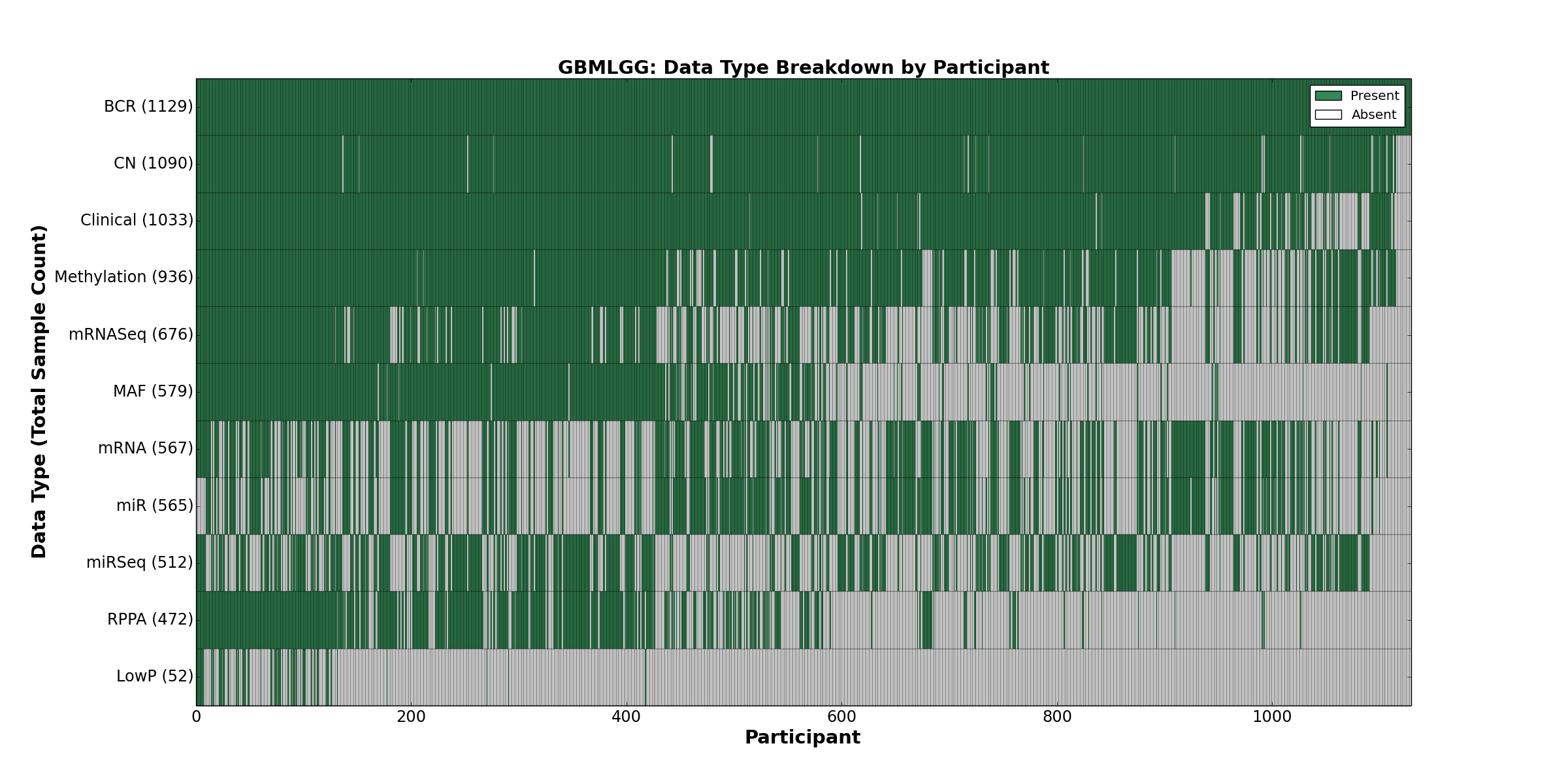
| GBMLGG | 1129 | 1033 | 1090 | 52 | 936 | 567 | 676 | 565 | 512 | 472 | 579 |
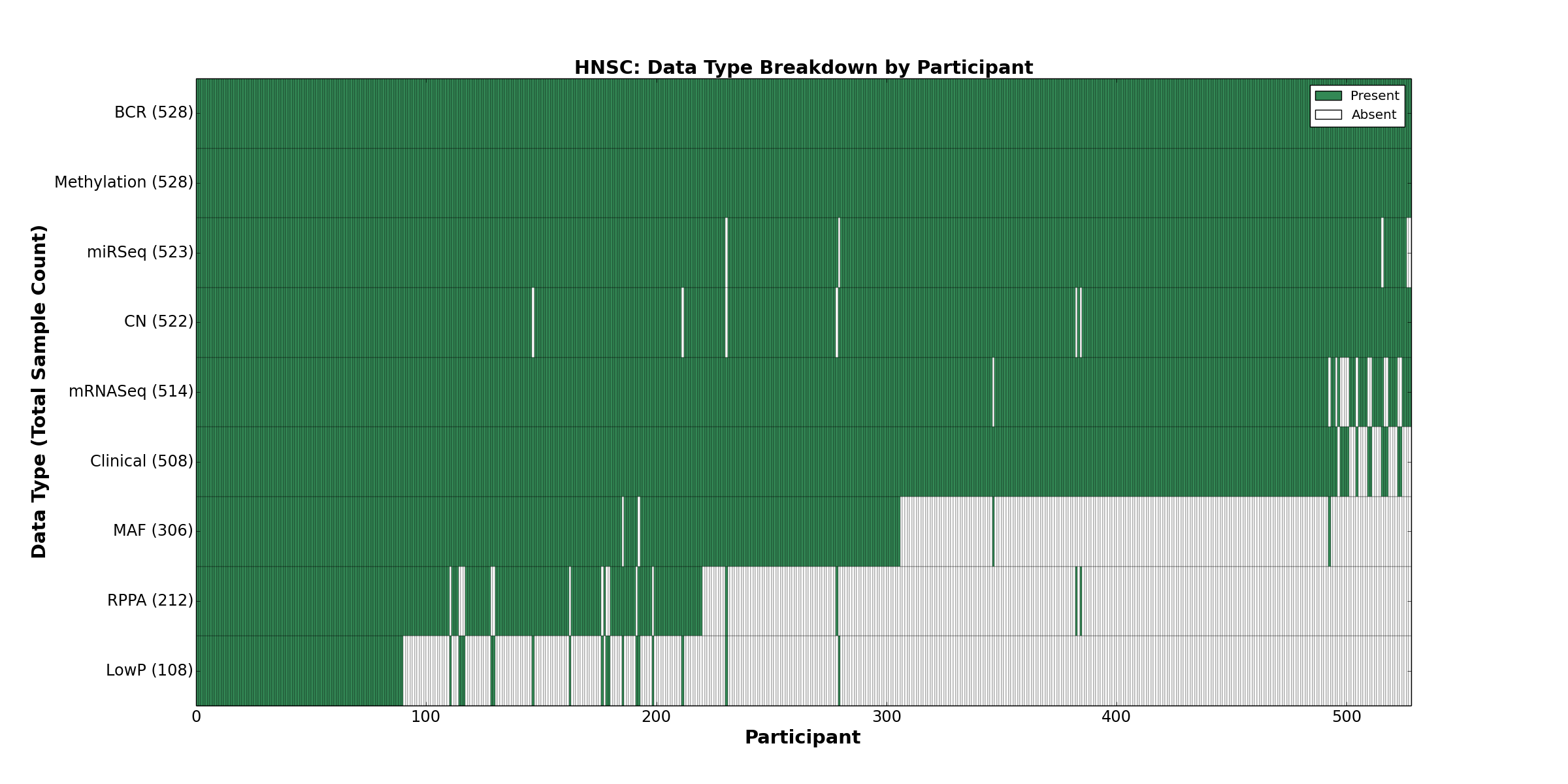
| HNSC | 528 | 508 | 522 | 108 | 528 | 0 | 514 | 0 | 523 | 212 | 306 |
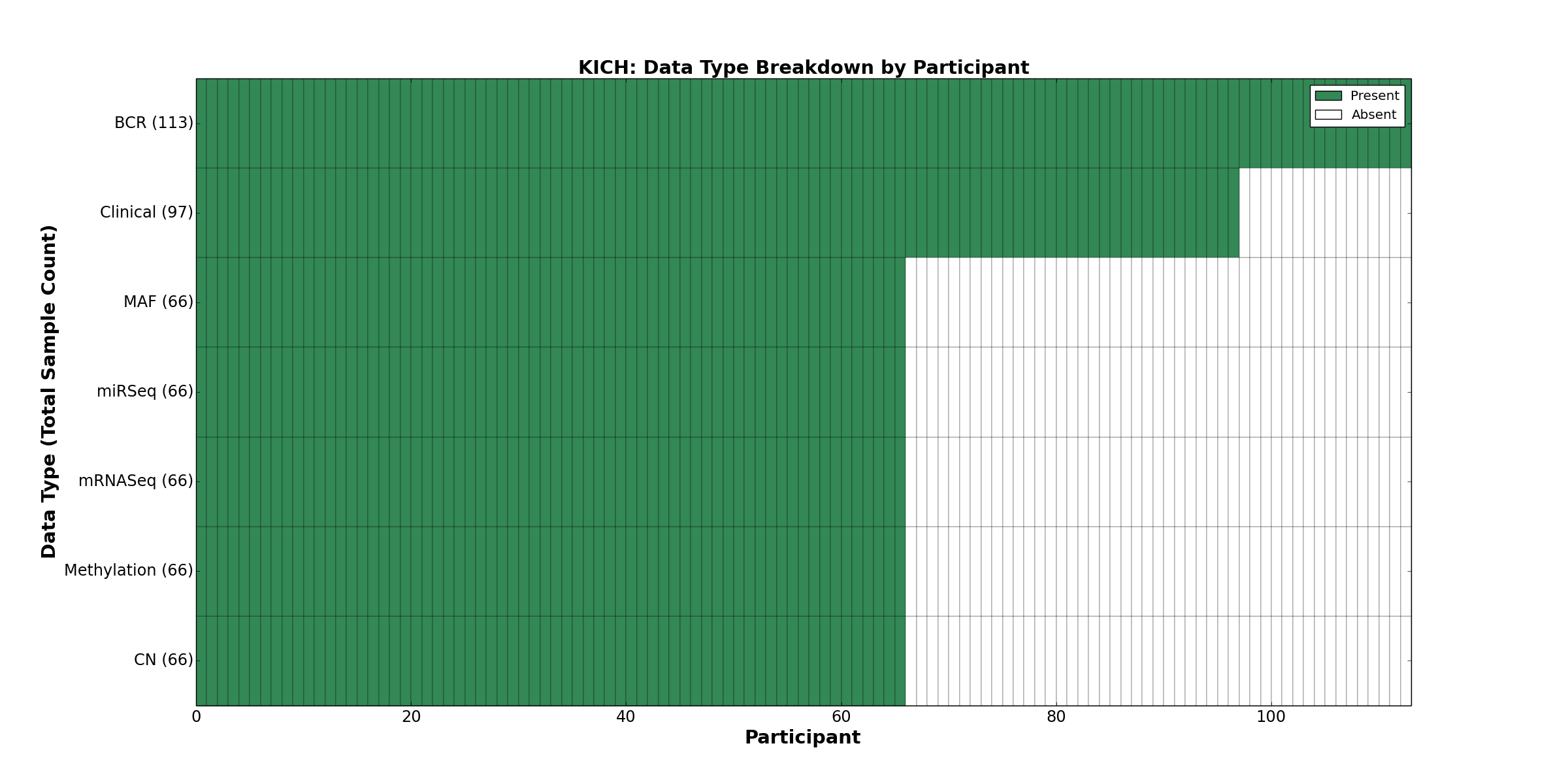
| KICH | 113 | 97 | 66 | 0 | 66 | 0 | 66 | 0 | 66 | 0 | 66 |
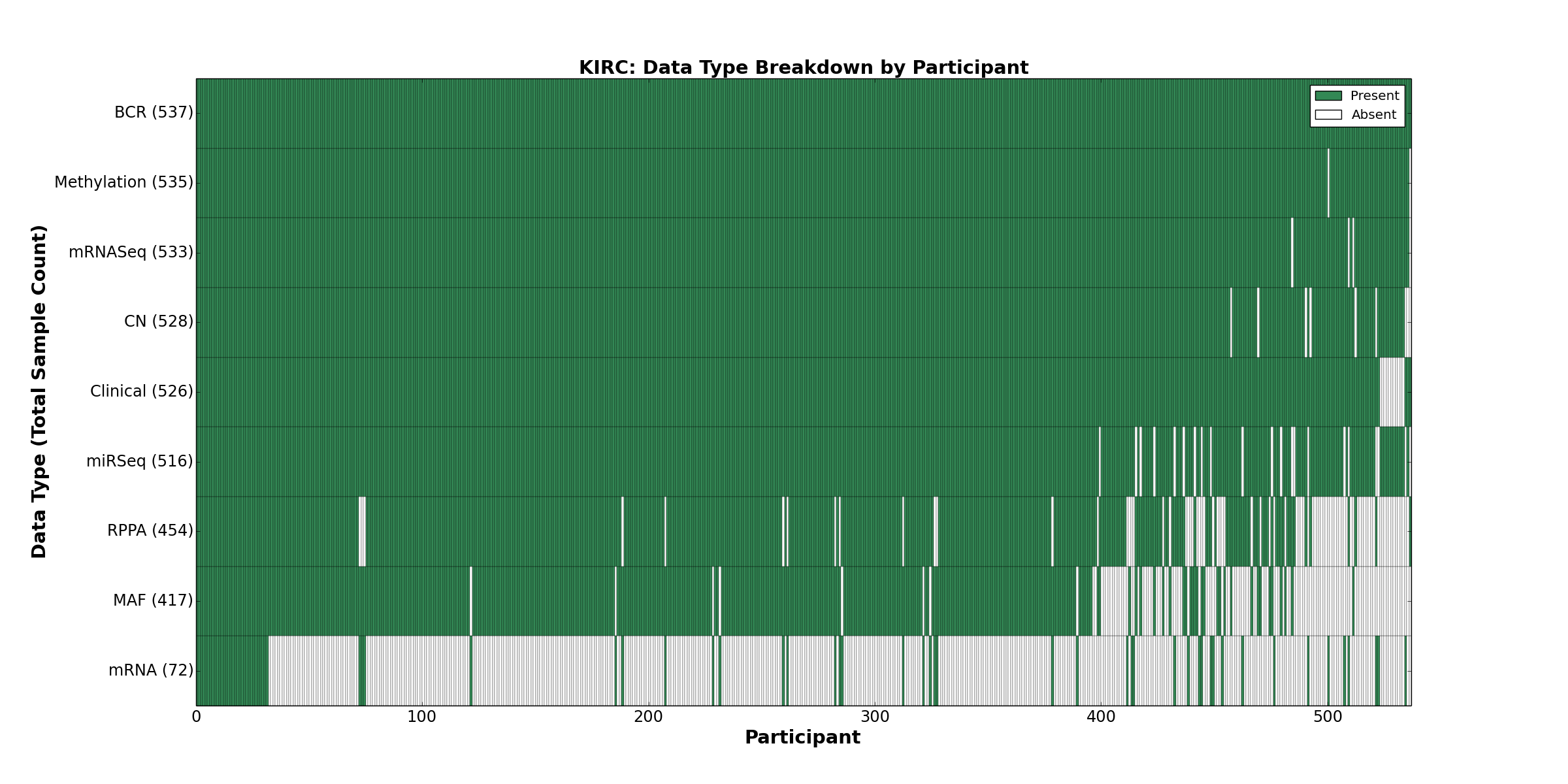
| KIRC | 537 | 526 | 528 | 0 | 535 | 72 | 533 | 0 | 516 | 454 | 417 |
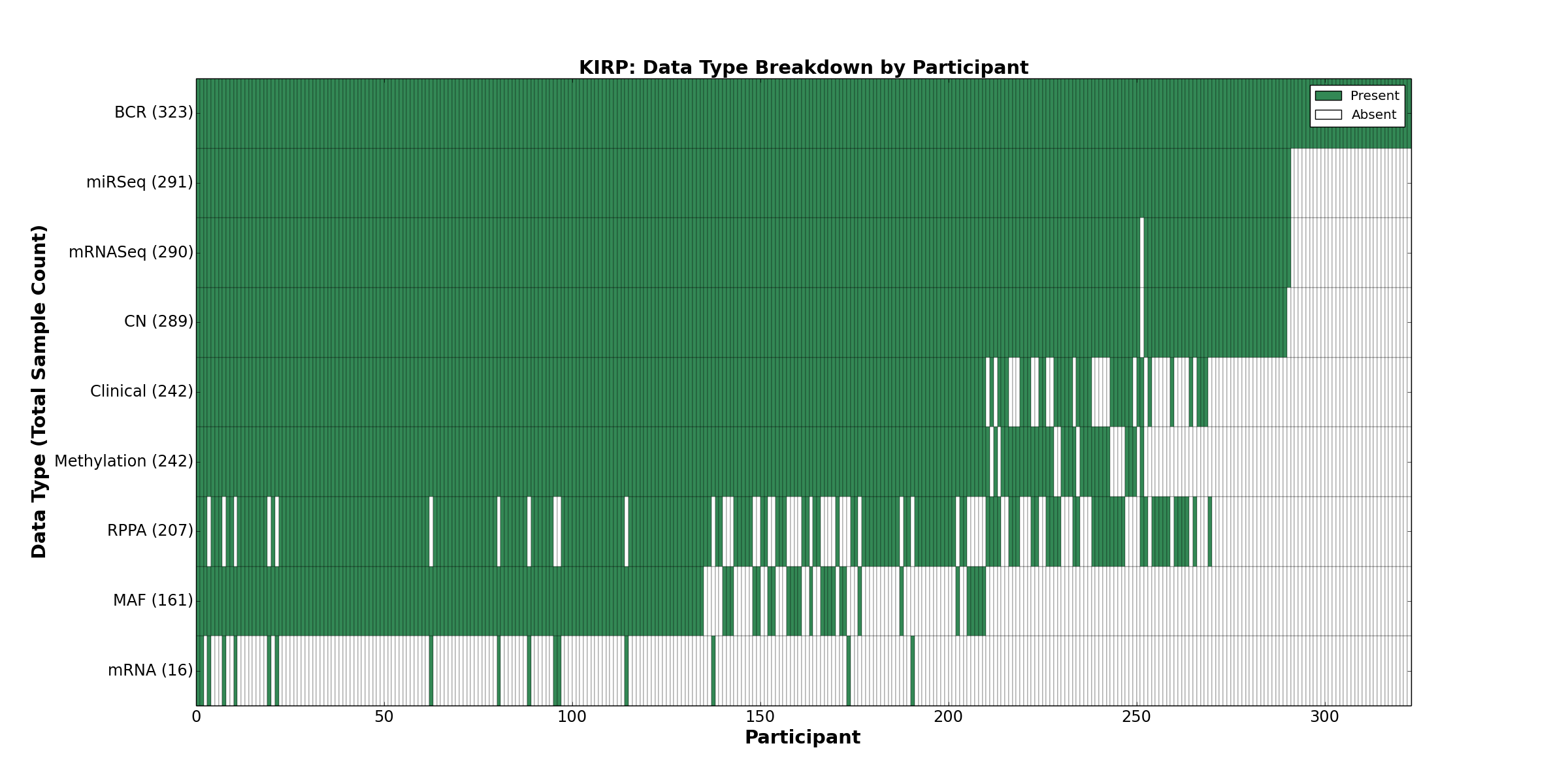
| KIRP | 323 | 242 | 289 | 0 | 242 | 16 | 290 | 0 | 291 | 207 | 161 |
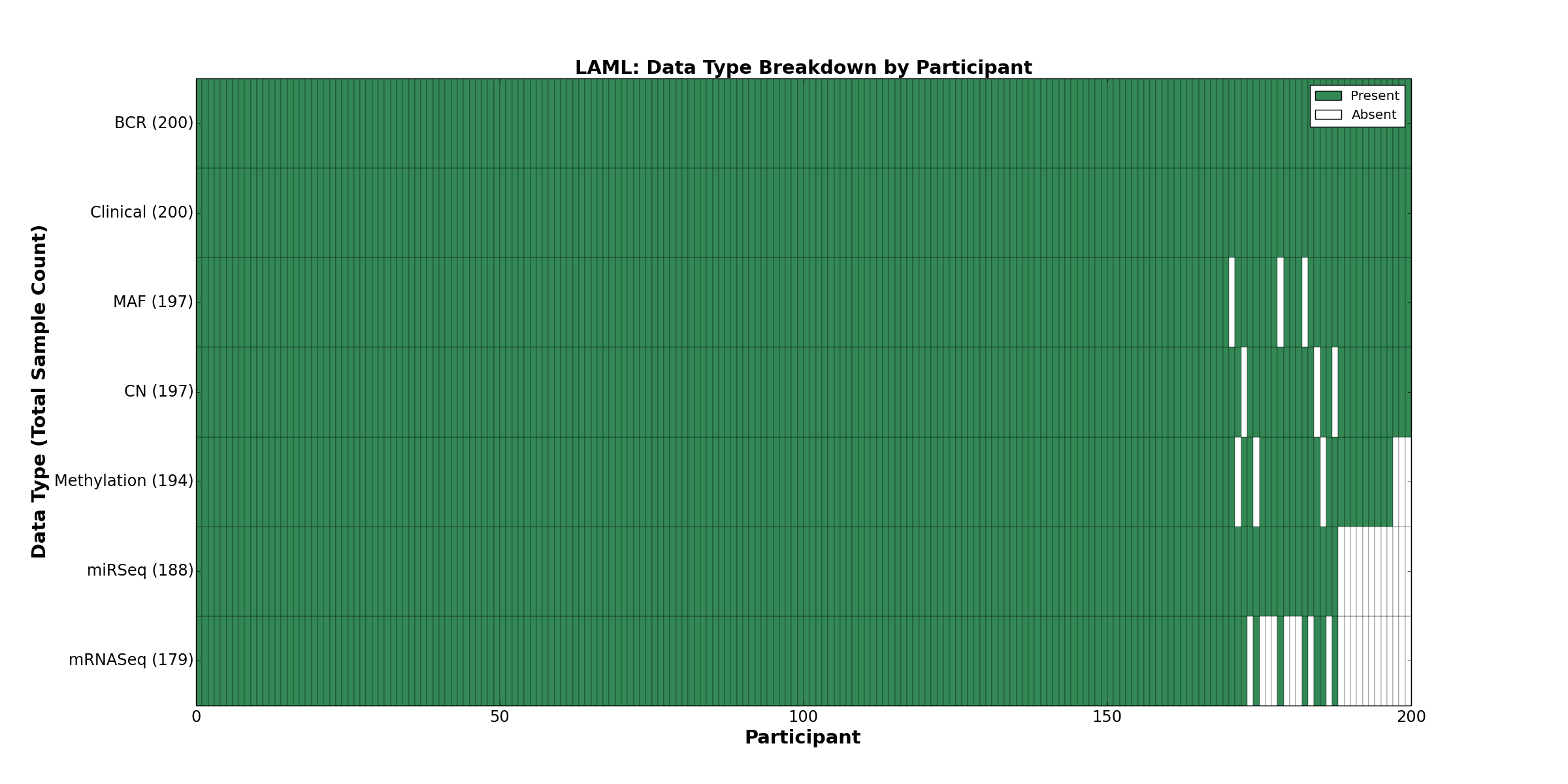
| LAML | 200 | 200 | 197 | 0 | 194 | 0 | 179 | 0 | 188 | 0 | 197 |
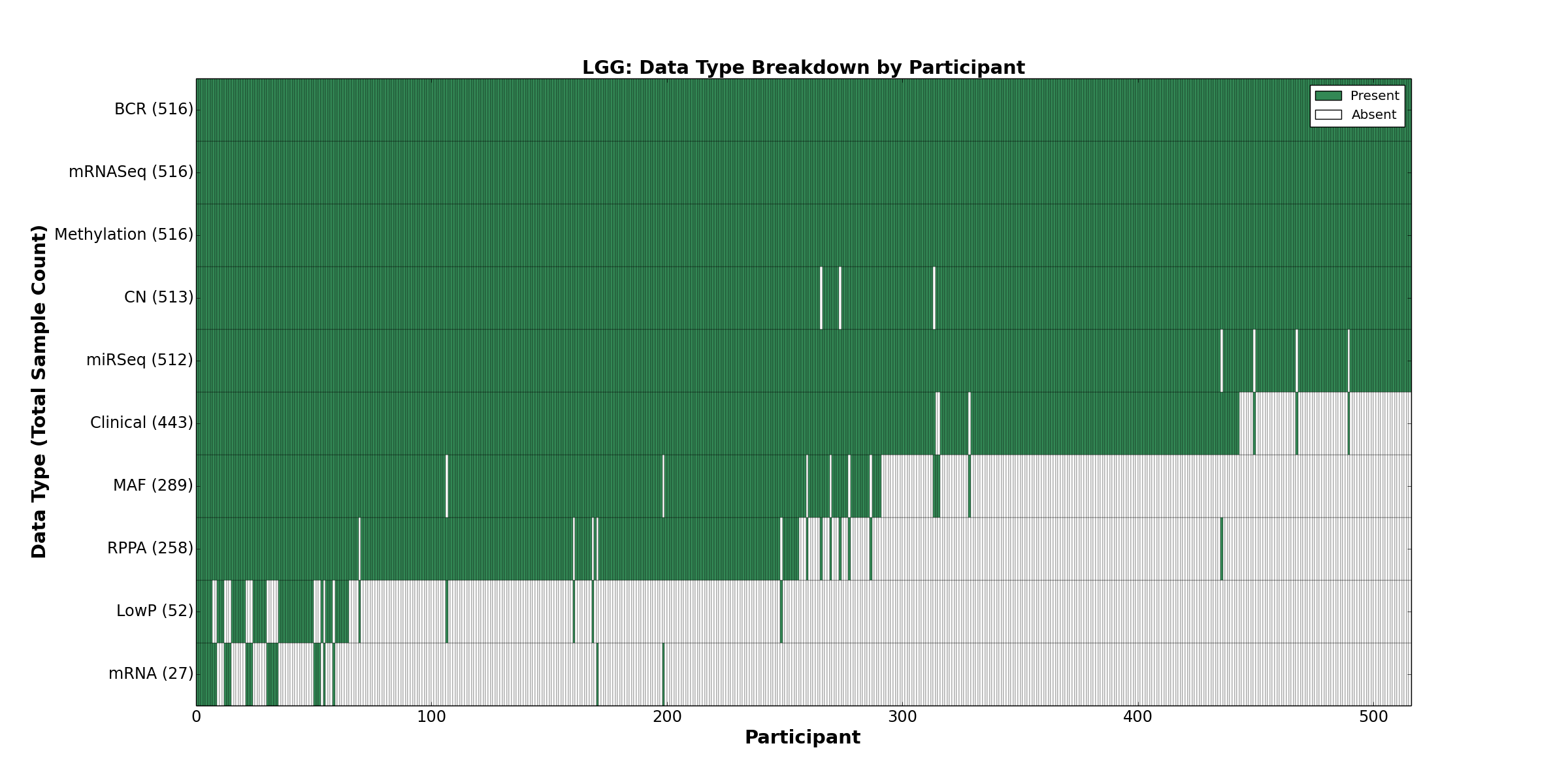
| LGG | 516 | 443 | 513 | 52 | 516 | 27 | 516 | 0 | 512 | 258 | 289 |
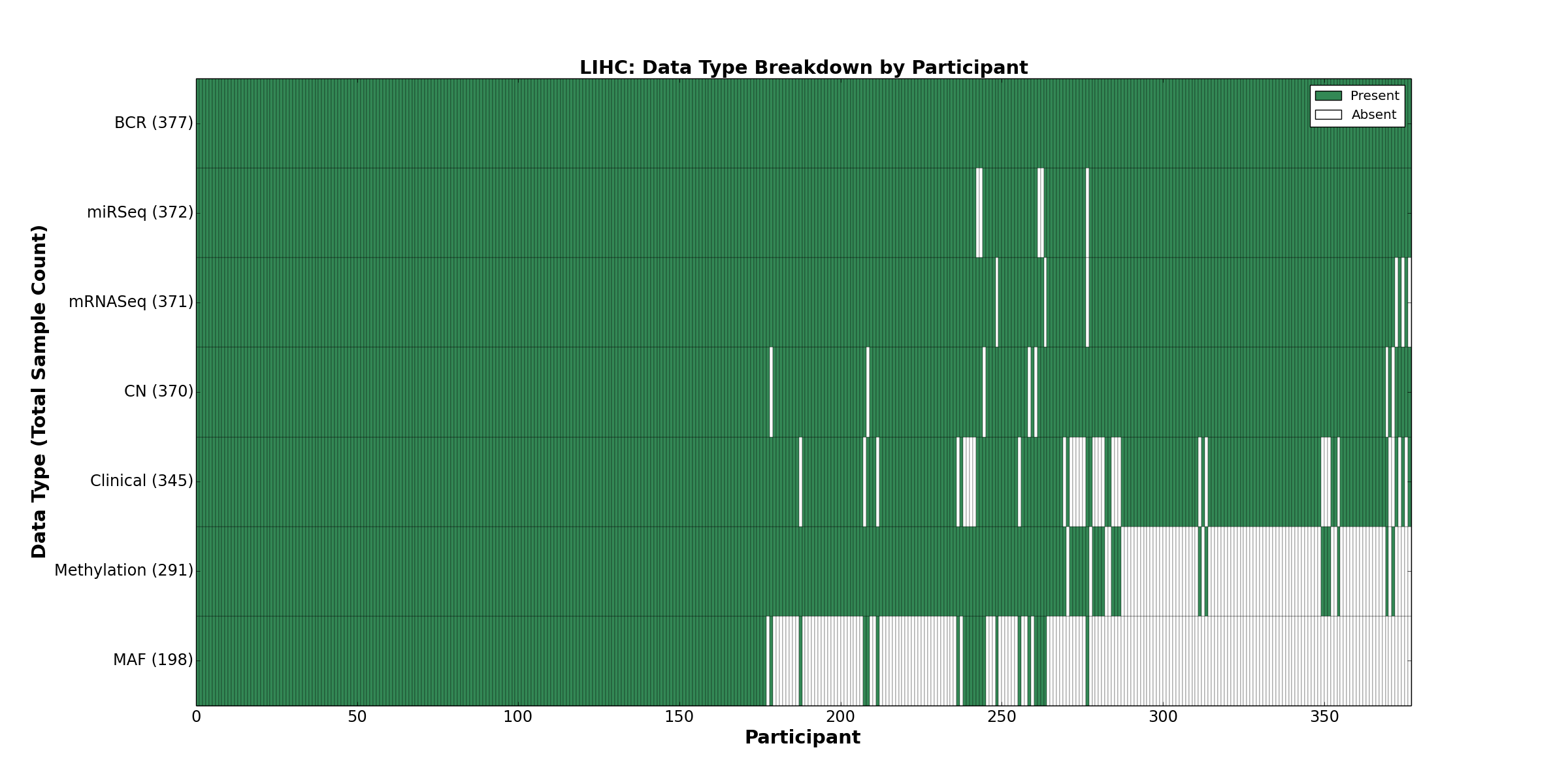
| LIHC | 377 | 345 | 370 | 0 | 291 | 0 | 371 | 0 | 372 | 0 | 198 |
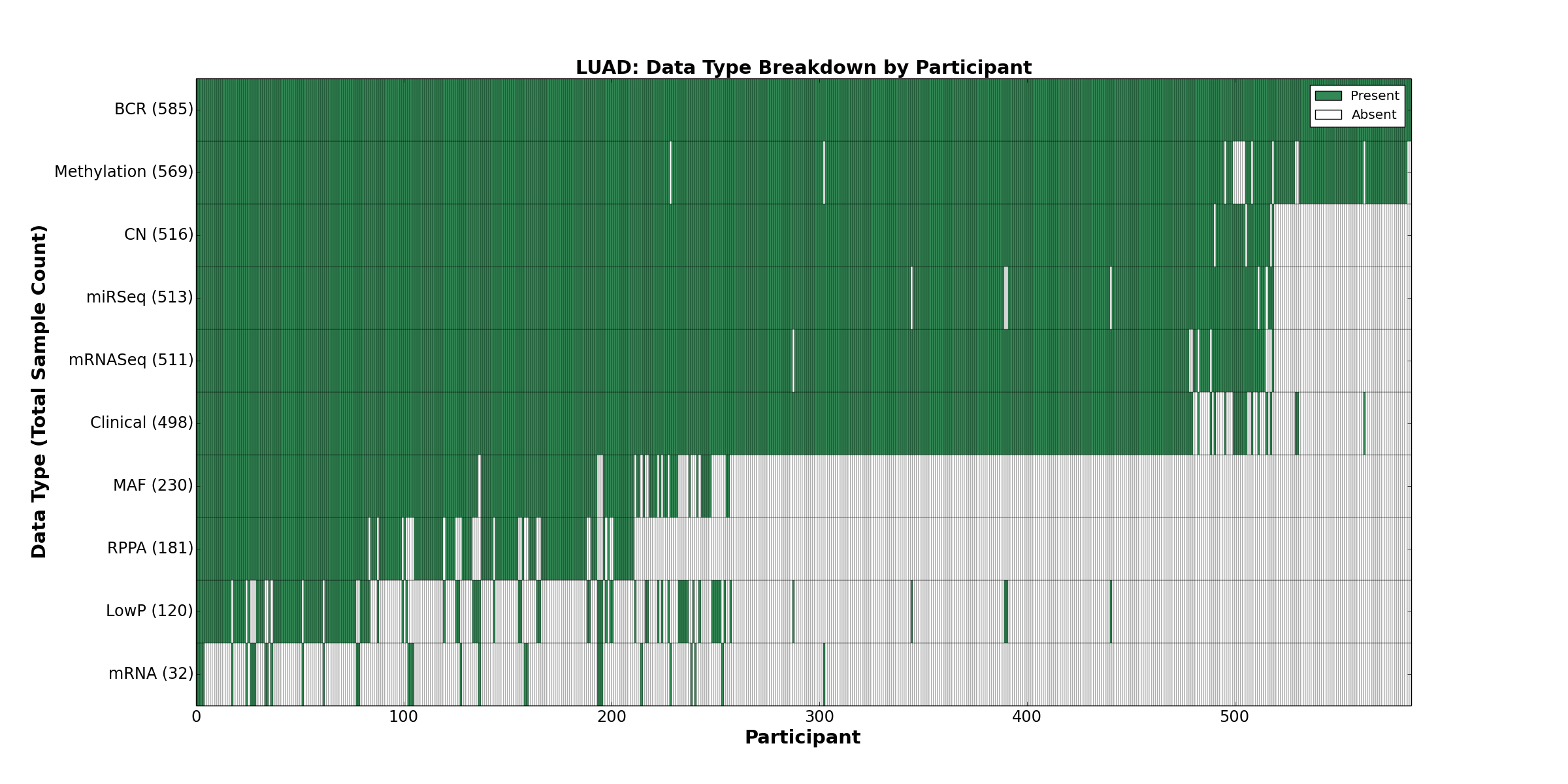
| LUAD | 585 | 498 | 516 | 120 | 569 | 32 | 511 | 0 | 513 | 181 | 230 |
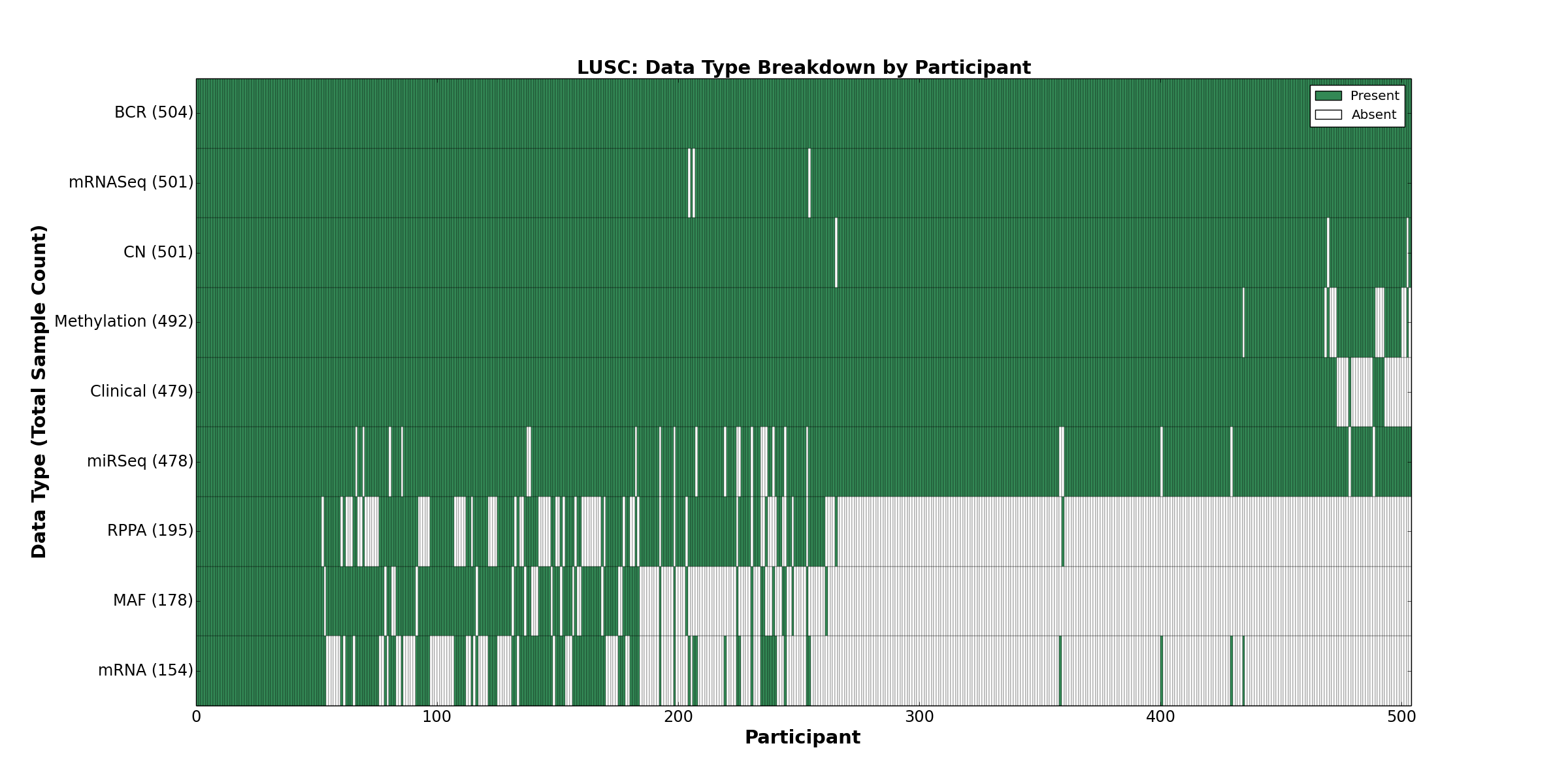
| LUSC | 504 | 479 | 501 | 0 | 492 | 154 | 501 | 0 | 478 | 195 | 178 |
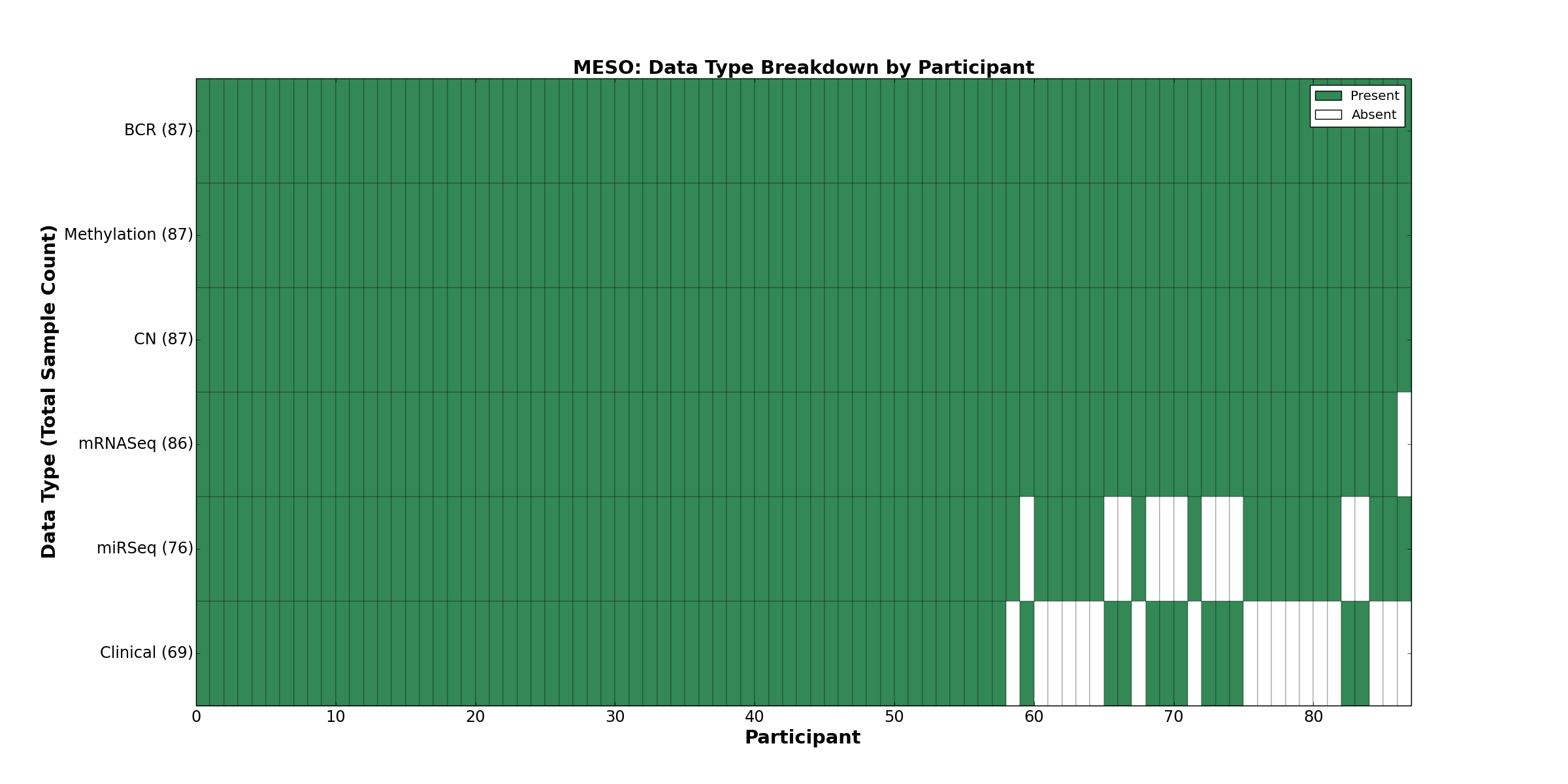
| MESO | 87 | 69 | 87 | 0 | 87 | 0 | 86 | 0 | 76 | 0 | 0 |
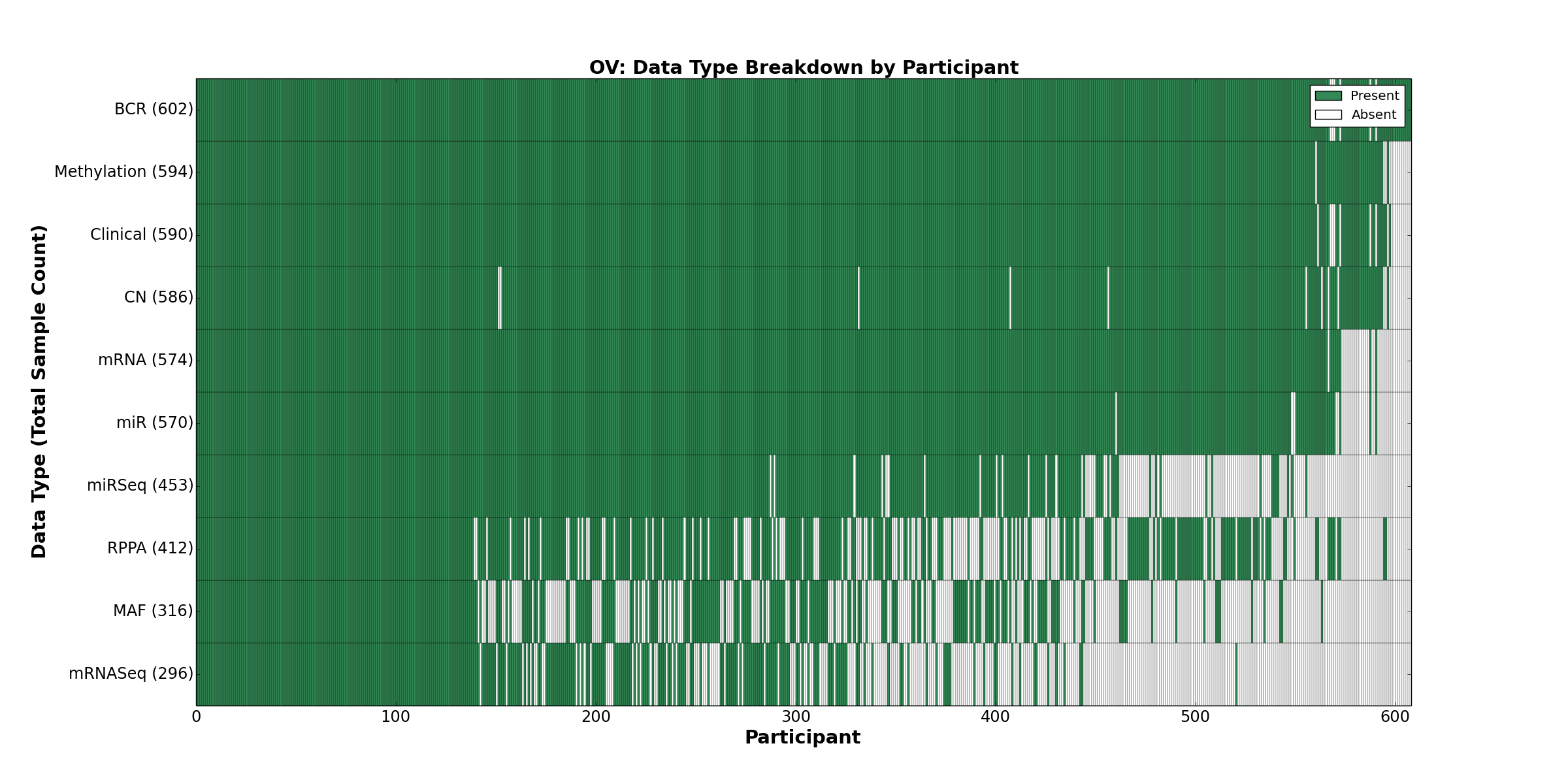
| OV | 602 | 590 | 586 | 0 | 594 | 574 | 296 | 570 | 453 | 412 | 316 |
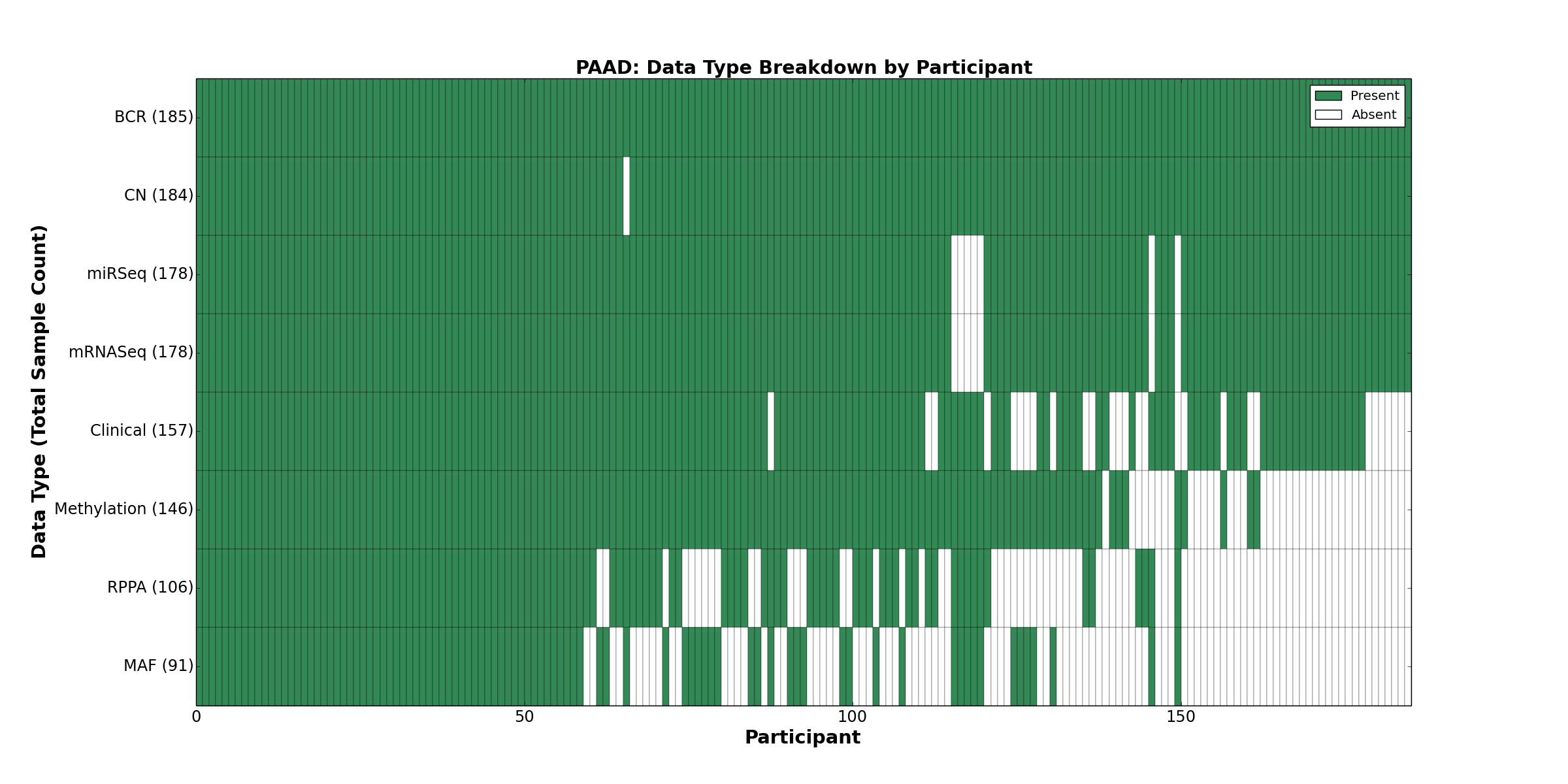
| PAAD | 185 | 157 | 184 | 0 | 146 | 0 | 178 | 0 | 178 | 106 | 91 |
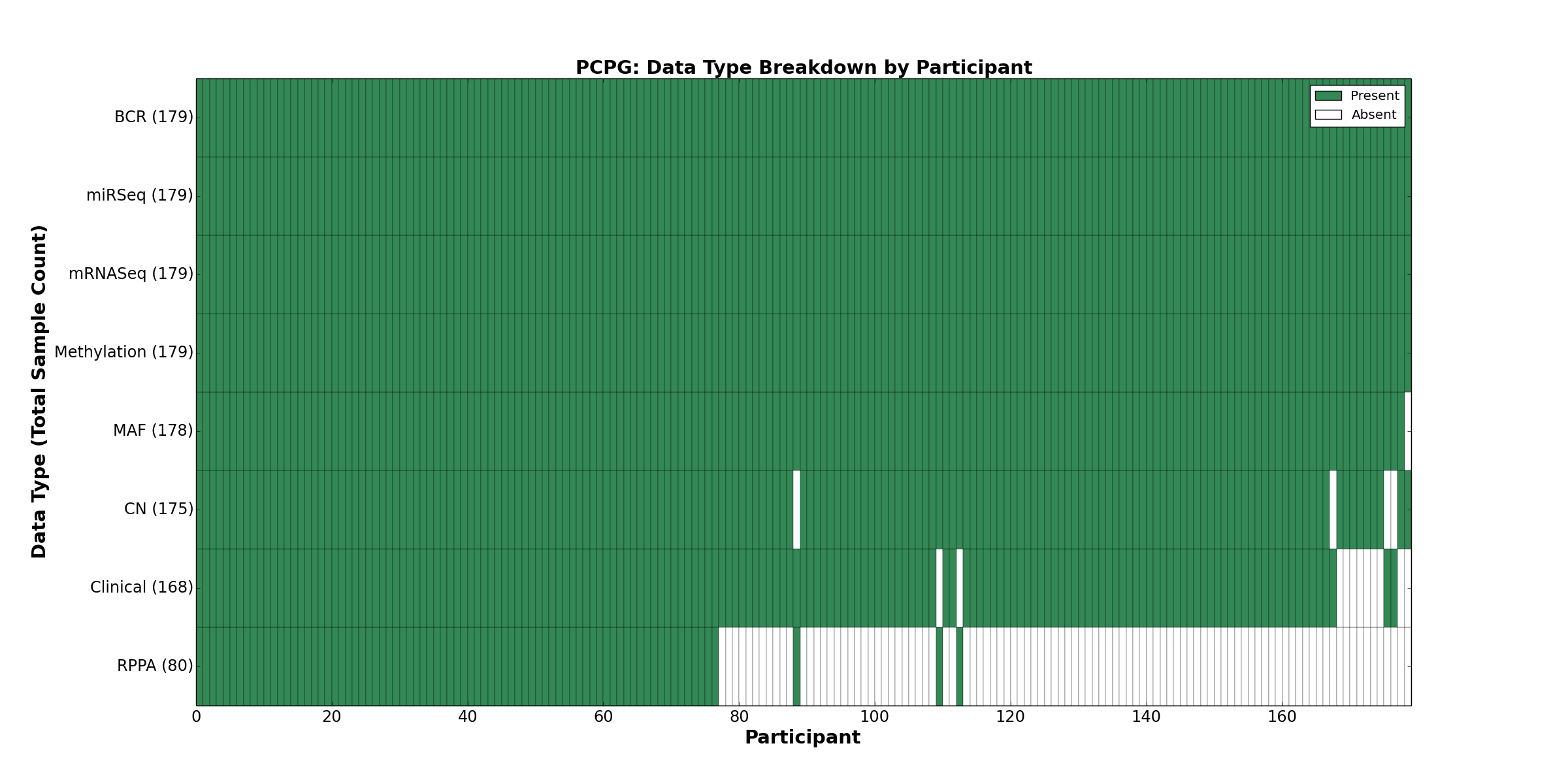
| PCPG | 179 | 168 | 175 | 0 | 179 | 0 | 179 | 0 | 179 | 80 | 178 |
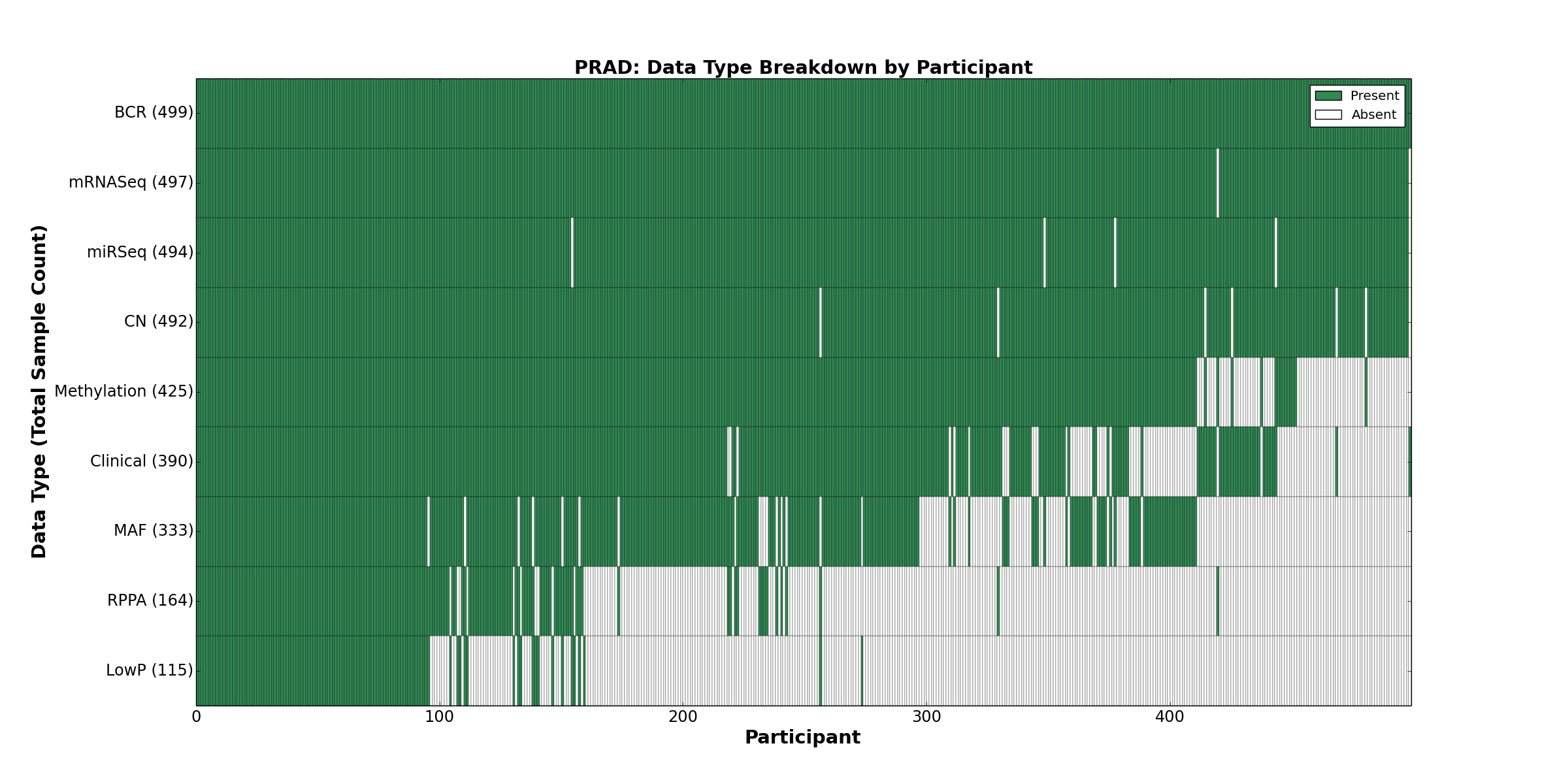
| PRAD | 499 | 390 | 492 | 115 | 425 | 0 | 497 | 0 | 494 | 164 | 333 |
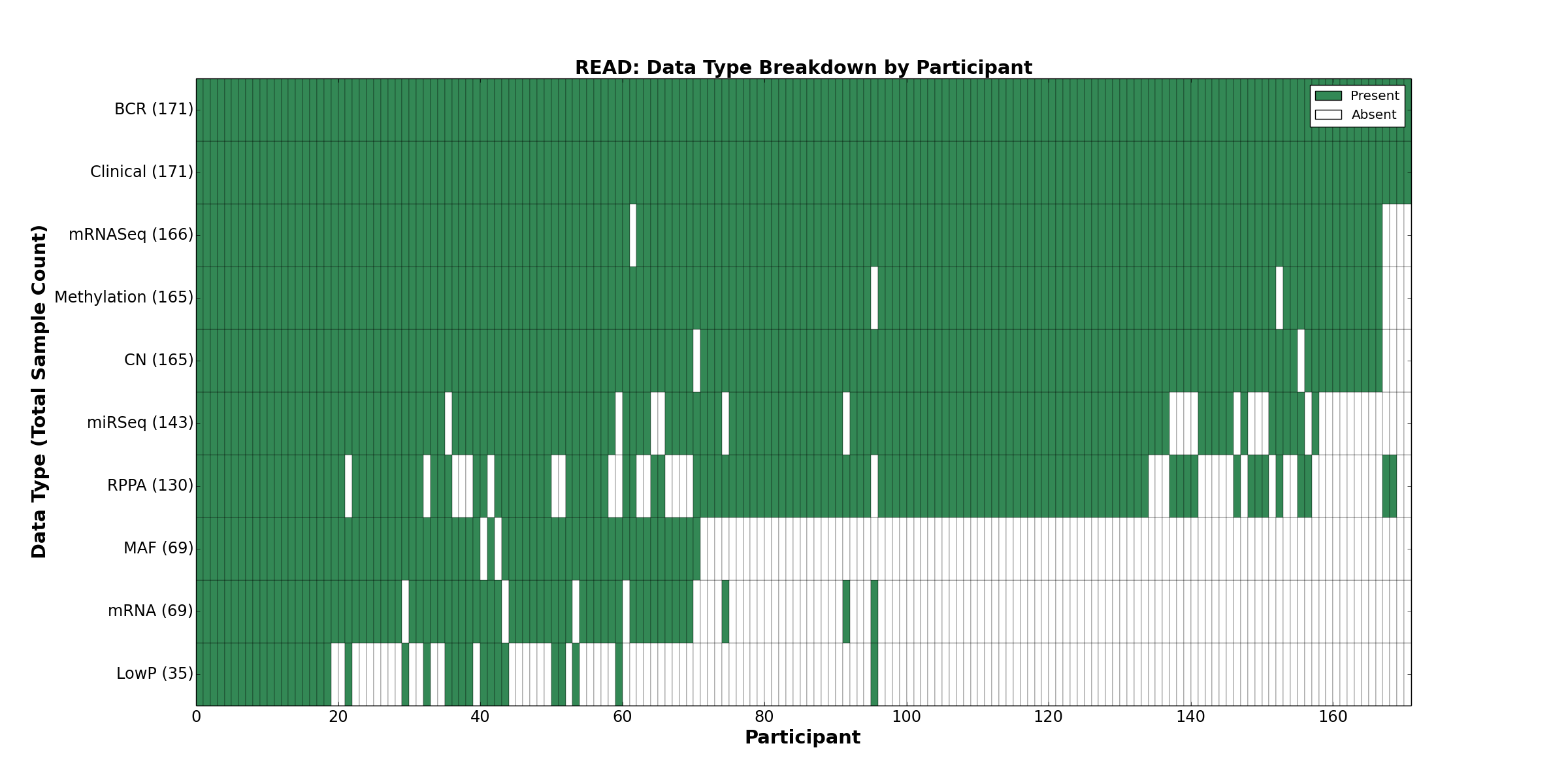
| READ | 171 | 171 | 165 | 35 | 165 | 69 | 166 | 0 | 143 | 130 | 69 |
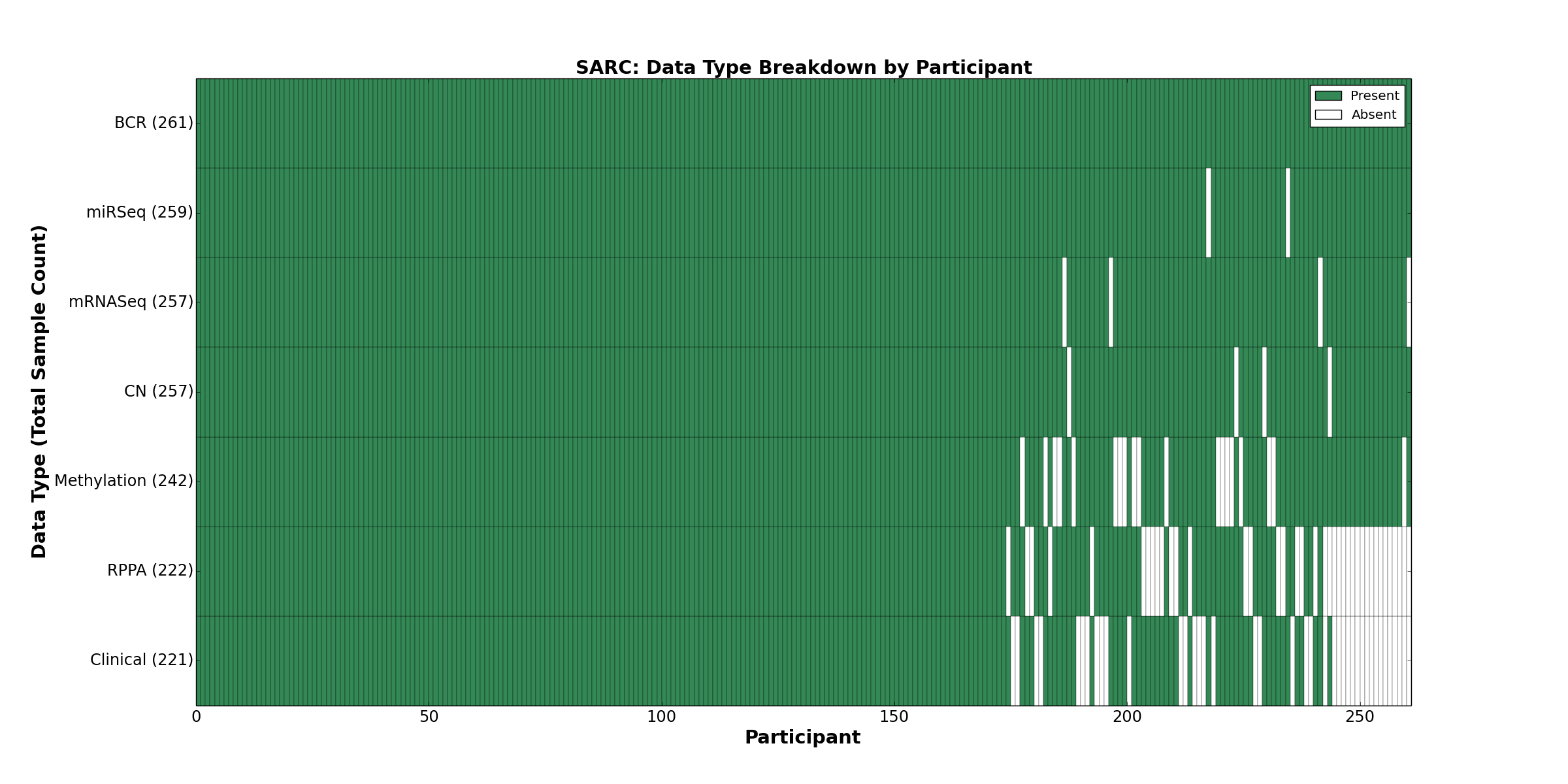
| SARC | 261 | 221 | 257 | 0 | 242 | 0 | 257 | 0 | 259 | 222 | 0 |
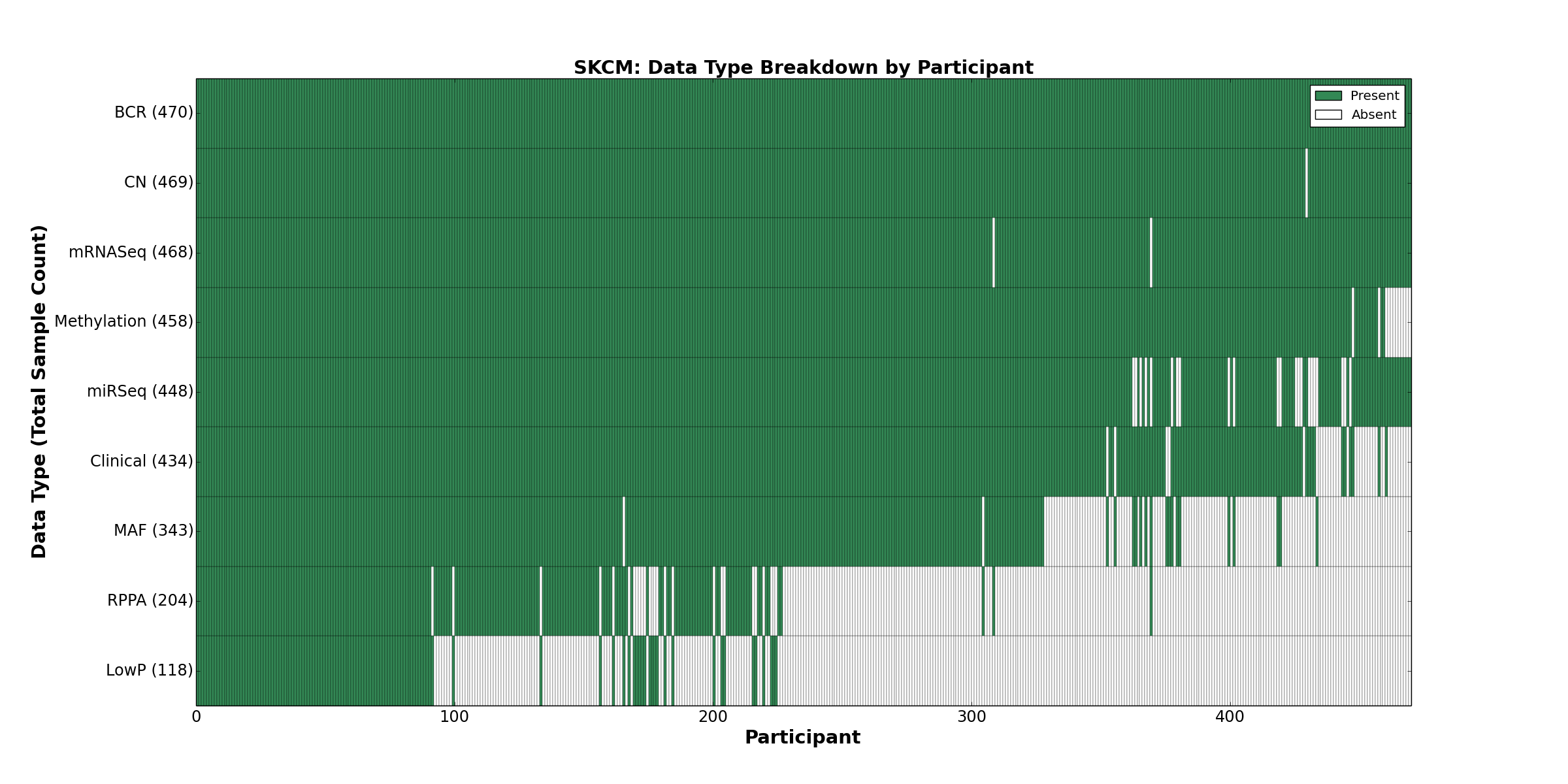
| SKCM | 470 | 434 | 469 | 118 | 458 | 0 | 468 | 0 | 448 | 204 | 343 |
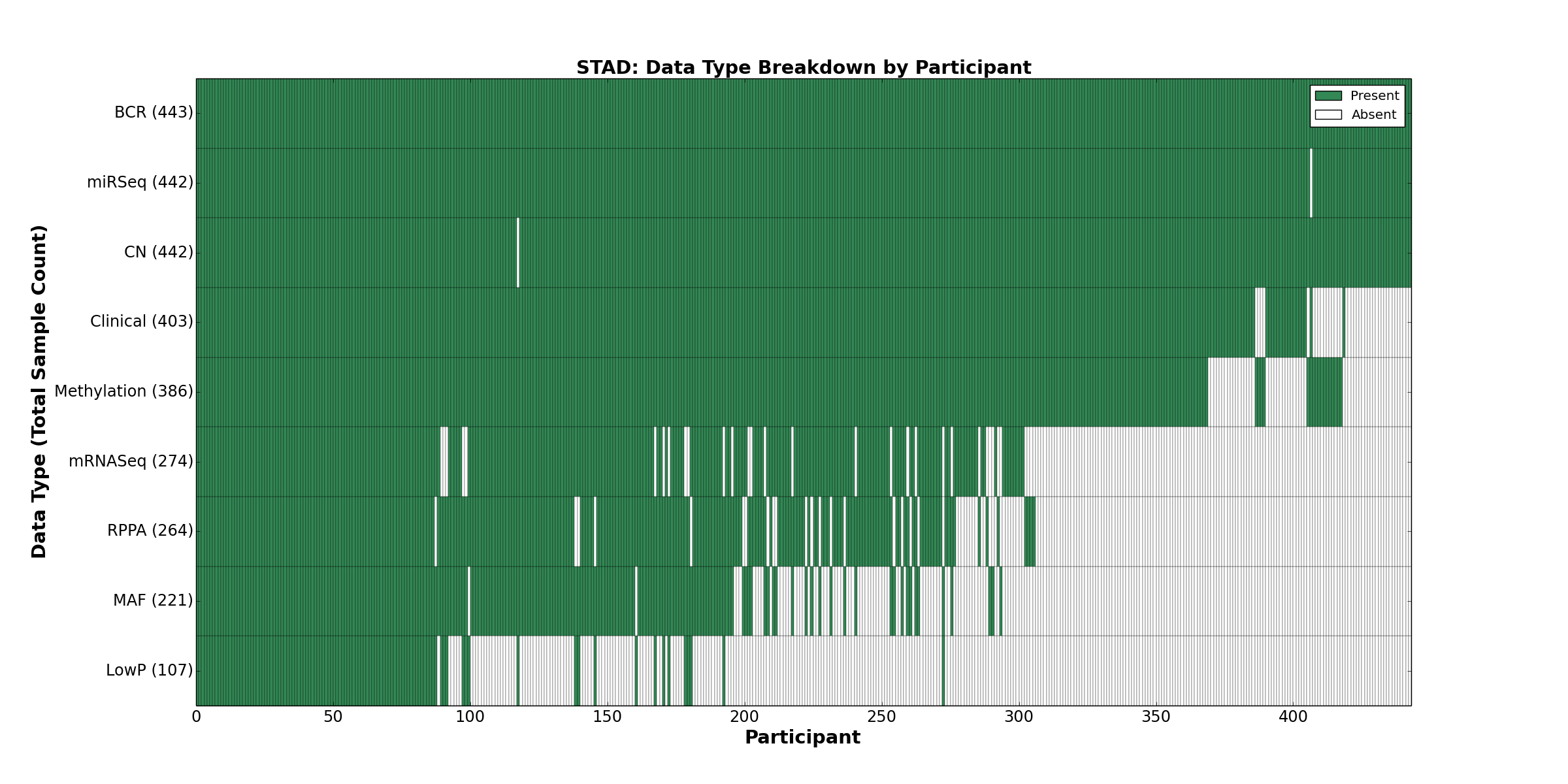
| STAD | 443 | 403 | 442 | 107 | 386 | 0 | 274 | 0 | 442 | 264 | 221 |
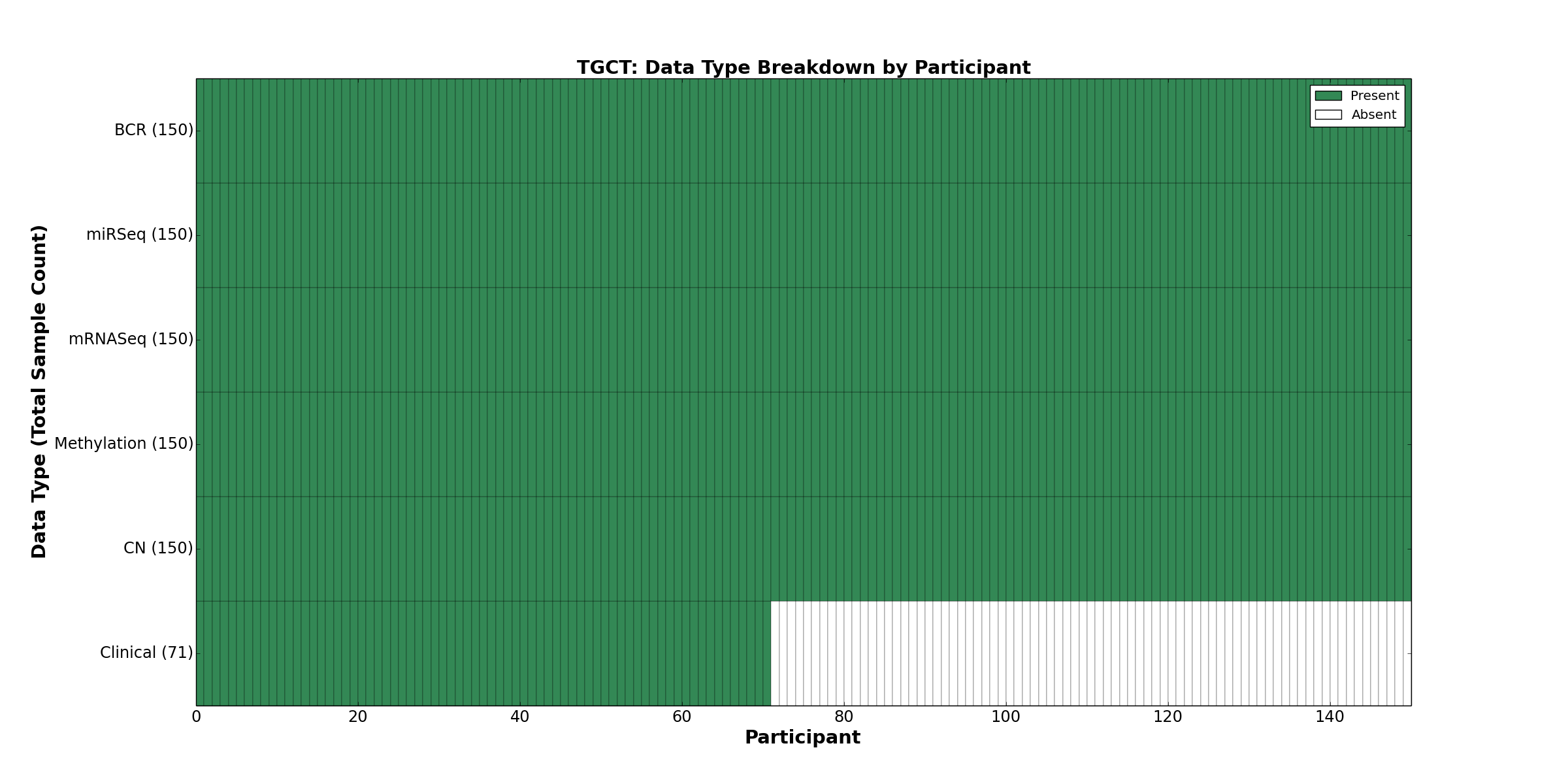
| TGCT | 150 | 71 | 150 | 0 | 150 | 0 | 150 | 0 | 150 | 0 | 0 |
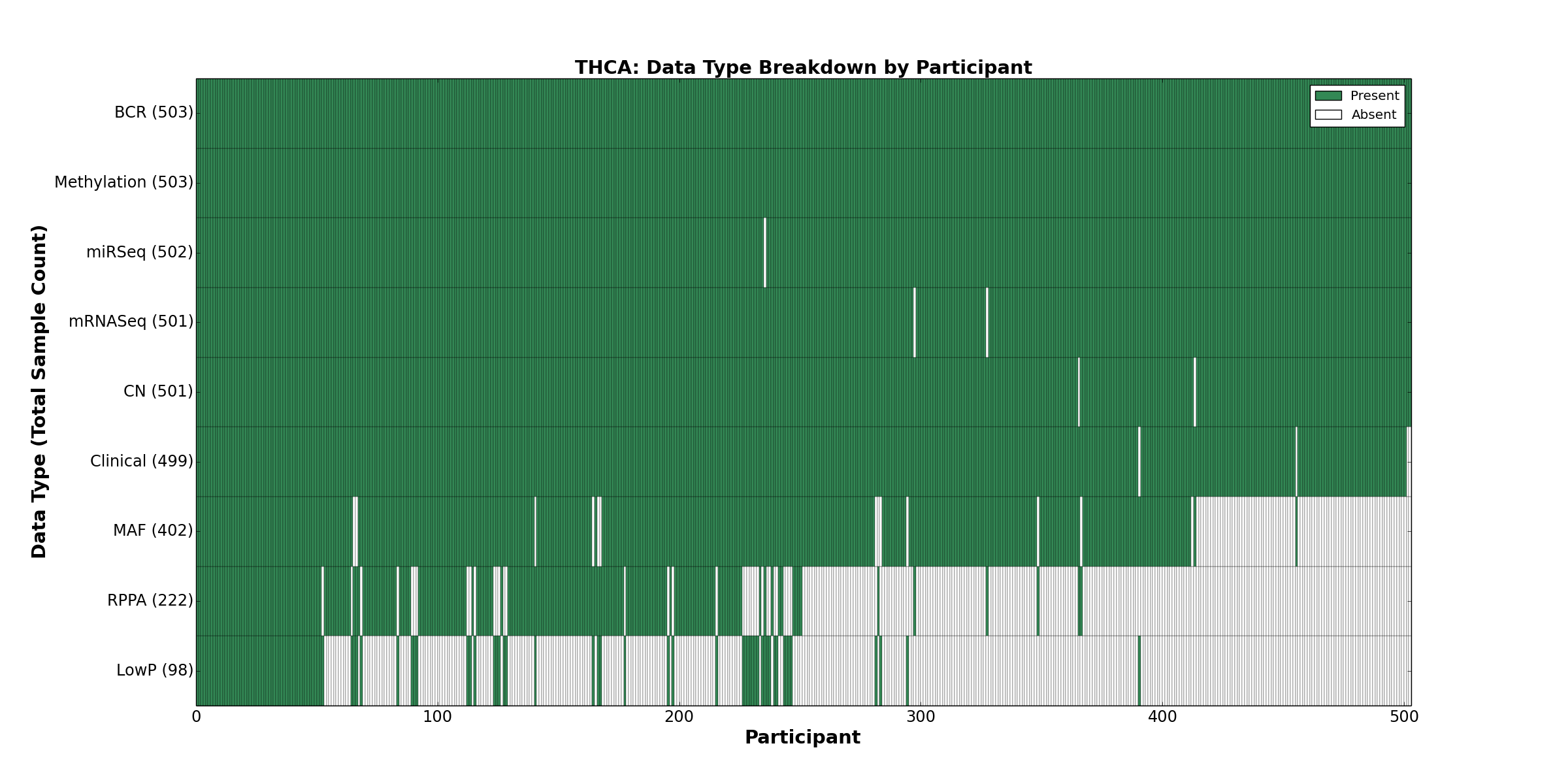
| THCA | 503 | 499 | 501 | 98 | 503 | 0 | 501 | 0 | 502 | 222 | 402 |
| THYM | 124 | 0 | 123 | 0 | 124 | 0 | 119 | 0 | 124 | 0 | 0 |
| UCEC | 560 | 522 | 540 | 106 | 547 | 54 | 543 | 0 | 538 | 200 | 248 |
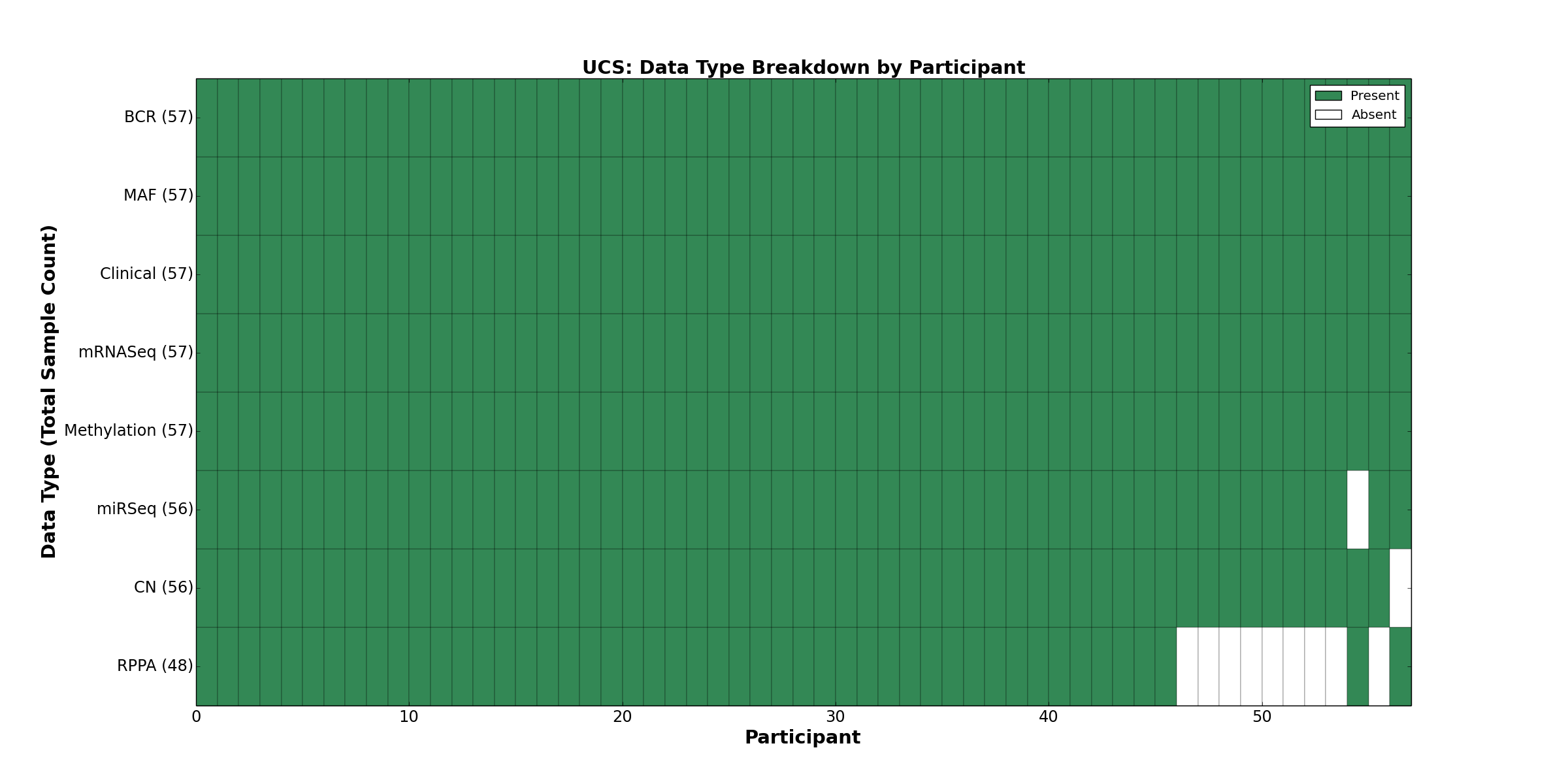
| UCS | 57 | 57 | 56 | 0 | 57 | 0 | 57 | 0 | 56 | 48 | 57 |
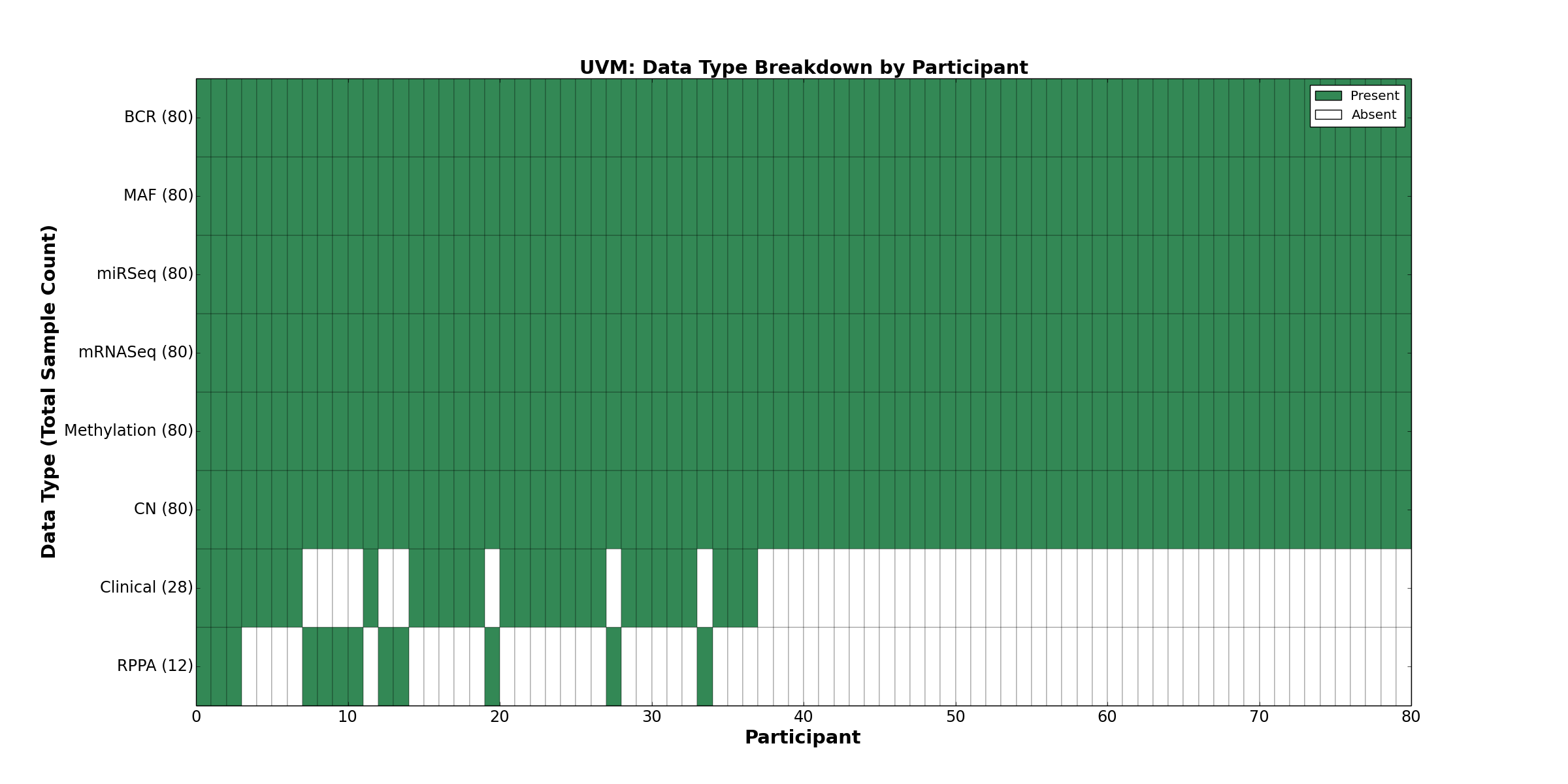
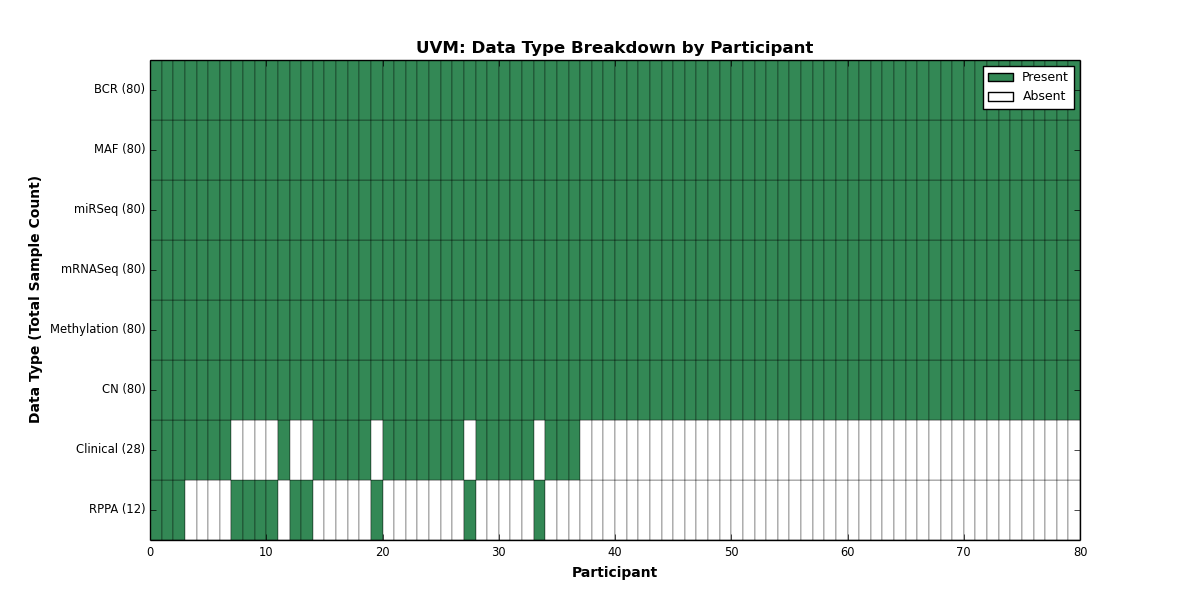
| UVM | 80 | 28 | 80 | 0 | 80 | 0 | 80 | 0 | 80 | 12 | 80 |
| Totals | 11353 | 10142 | 10988 | 1091 | 10423 | 2217 | 10077 | 1135 | 10149 | 4998 | 6215 |
Figure 1. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
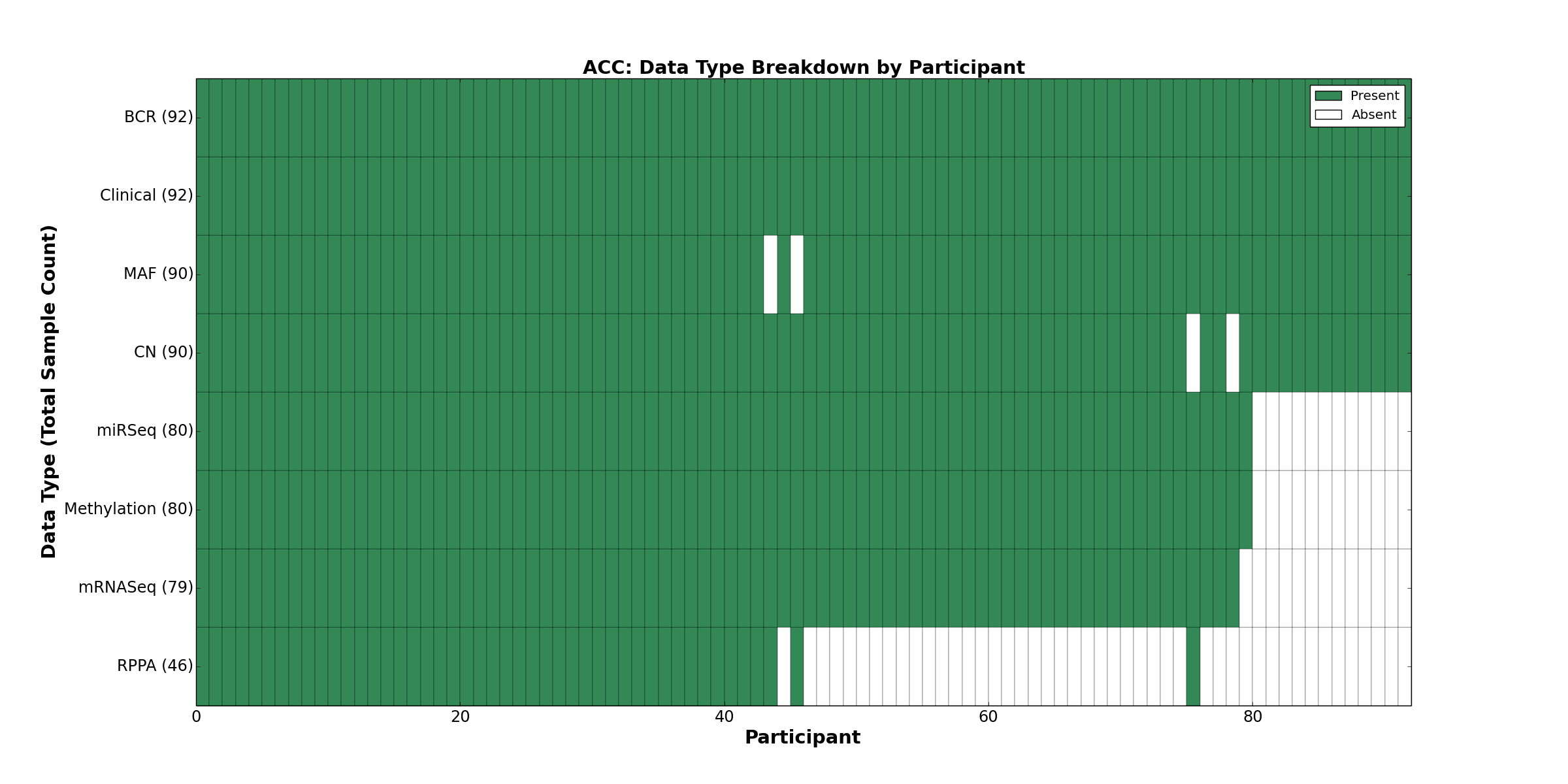{kind=link}
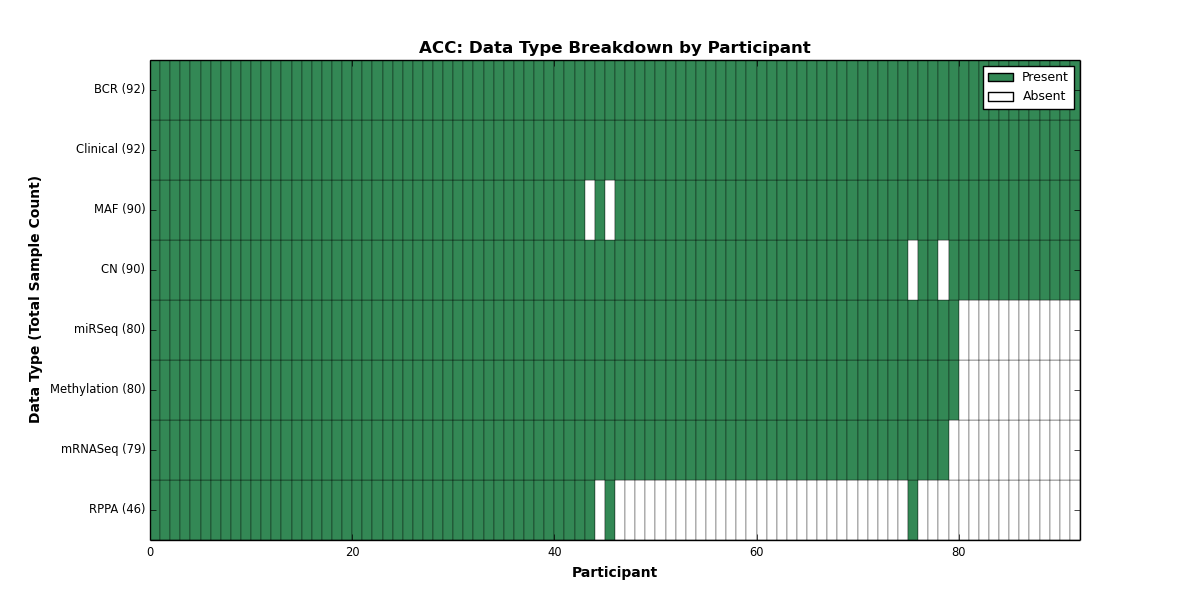
Figure 2. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
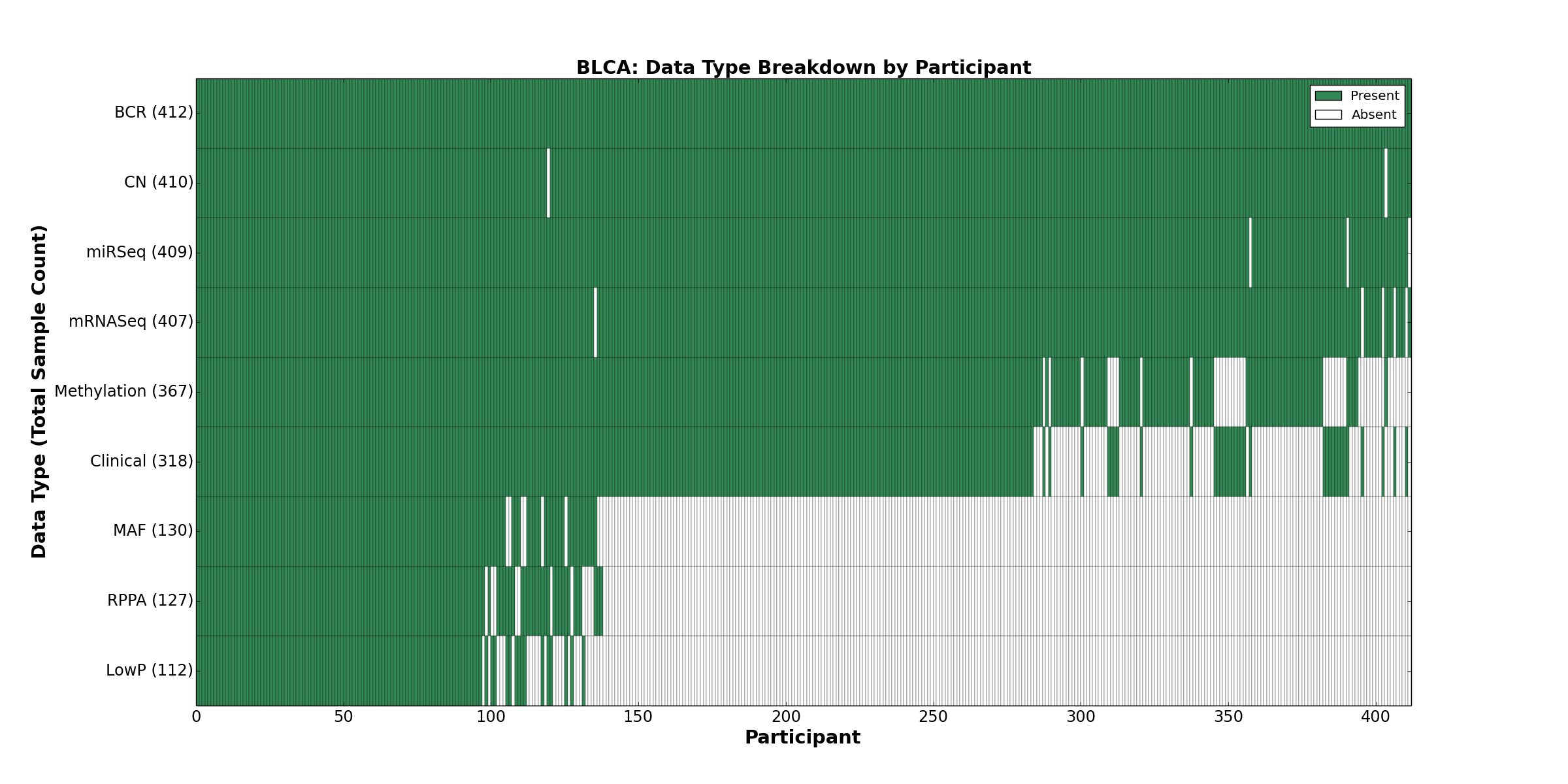{kind=link}
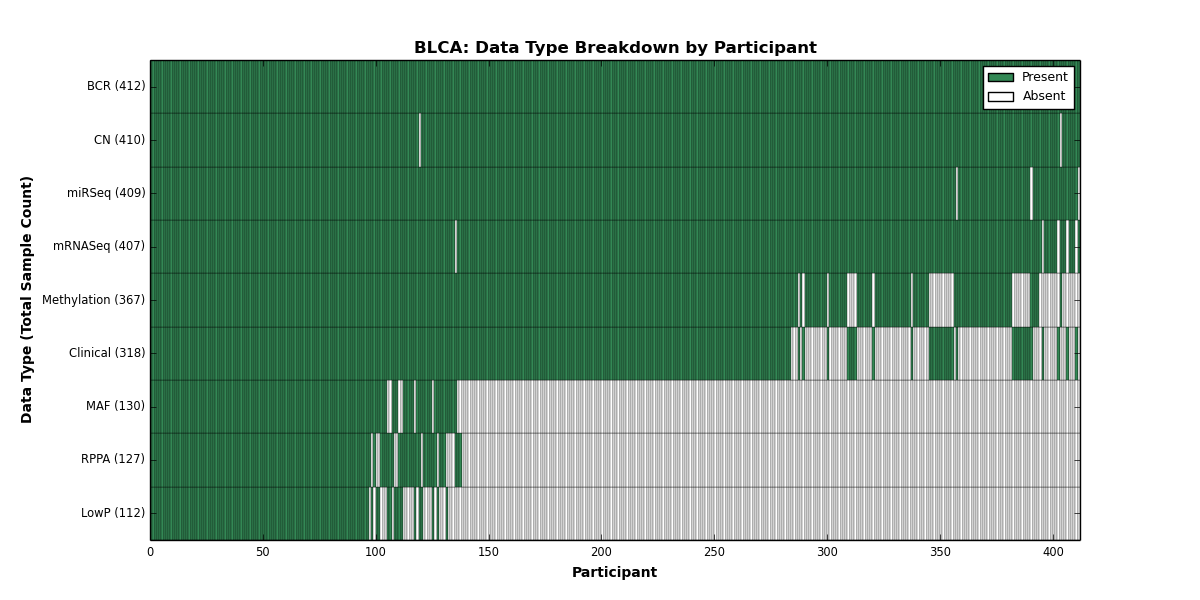
Figure 3. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
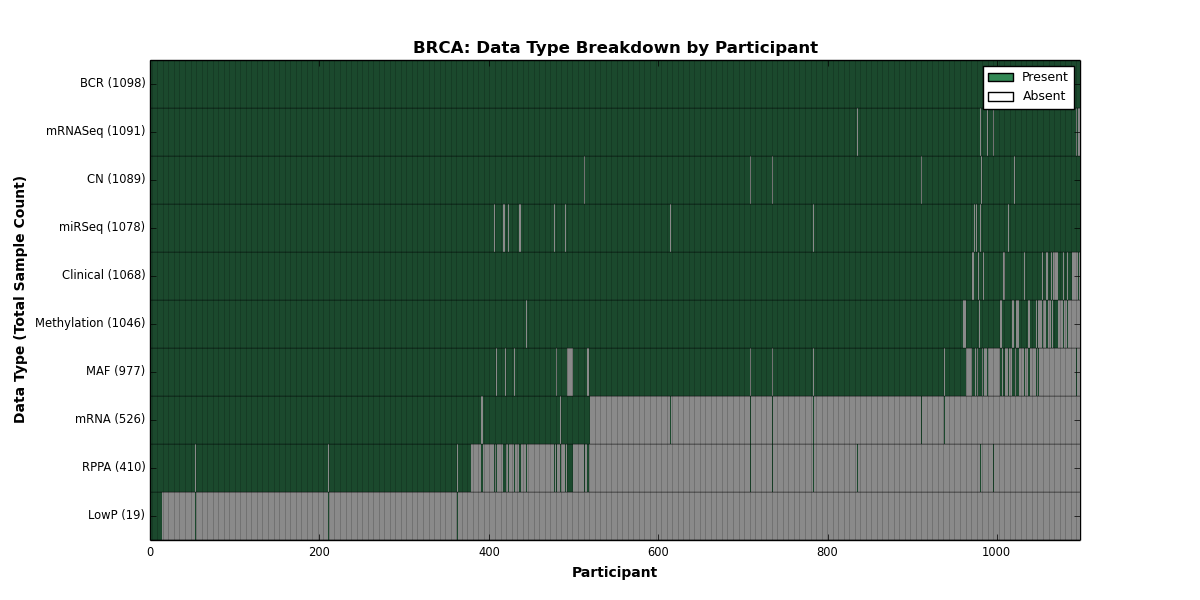
Figure 4. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
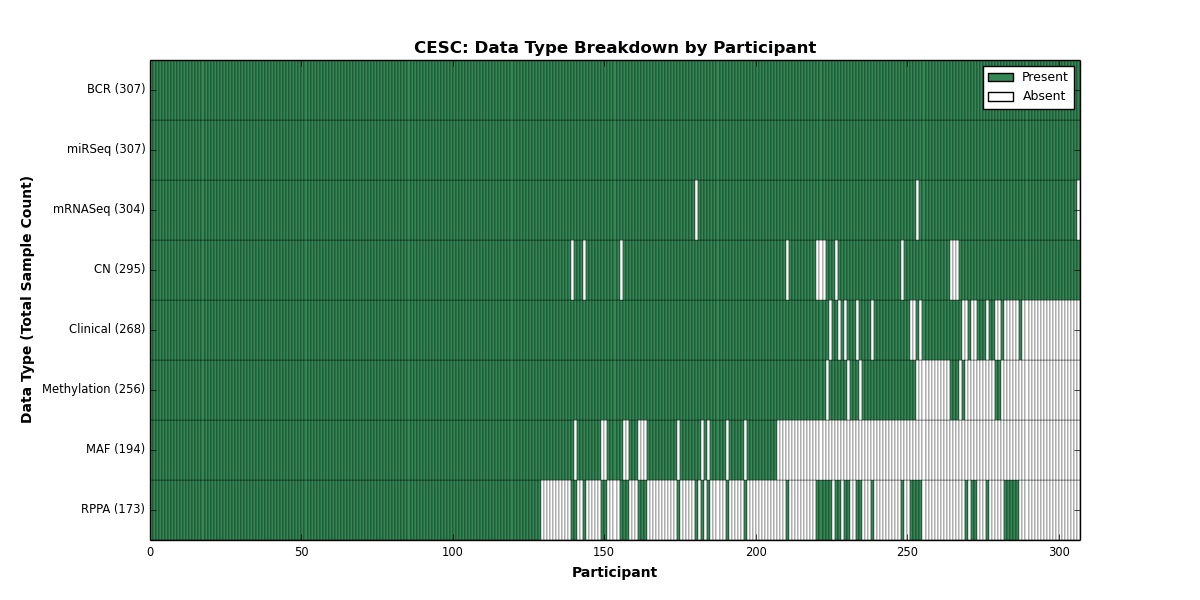
Figure 5. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
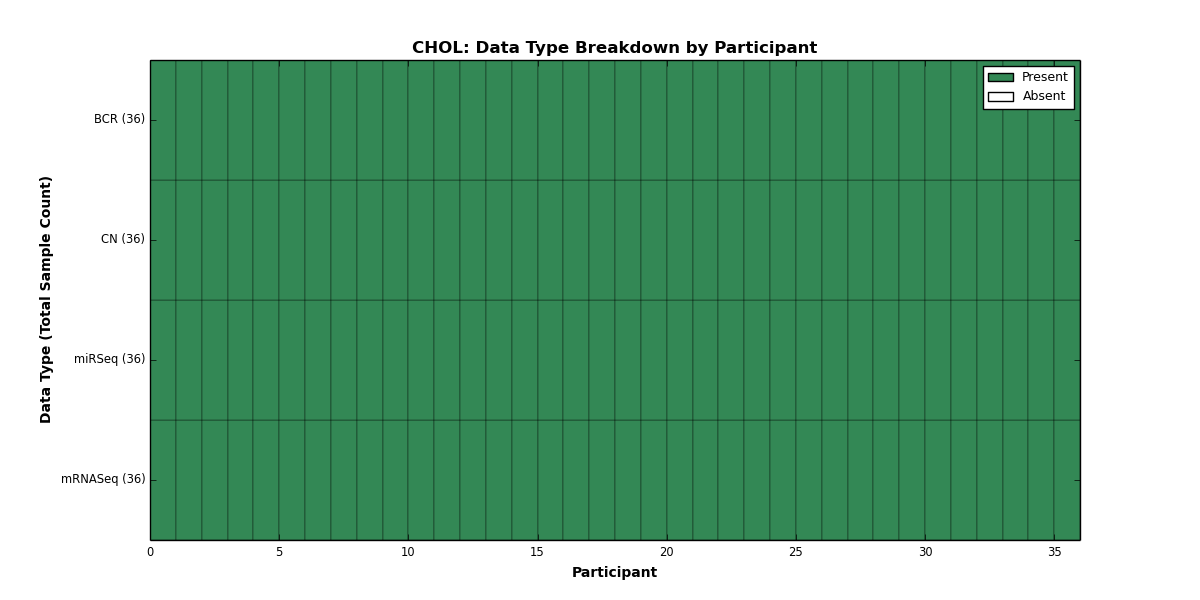
Figure 6. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
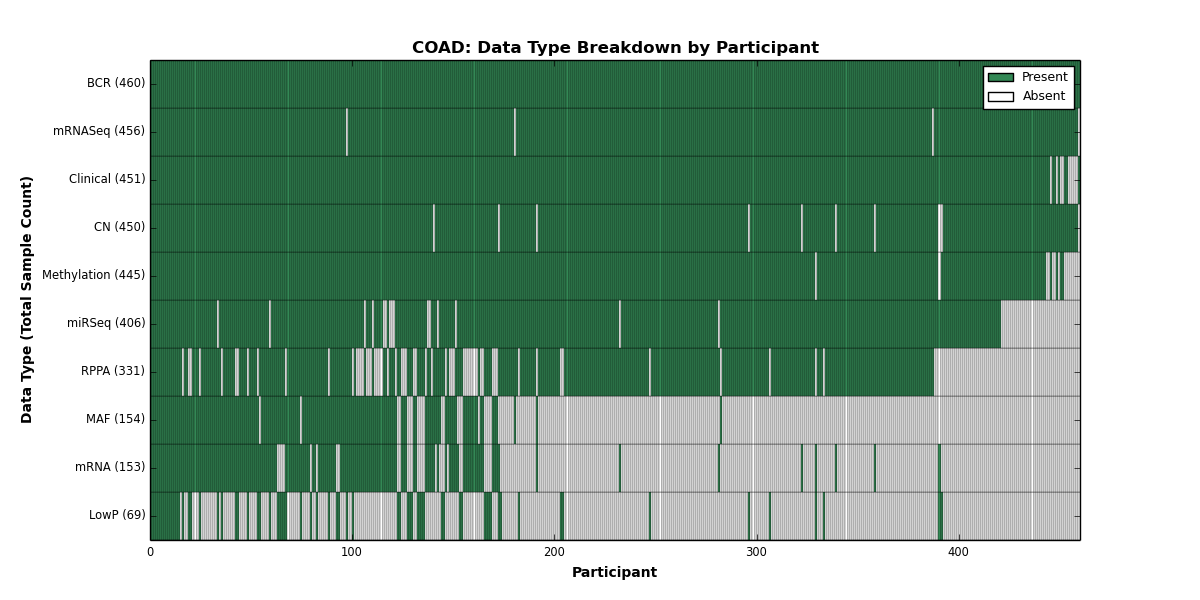
Figure 7. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
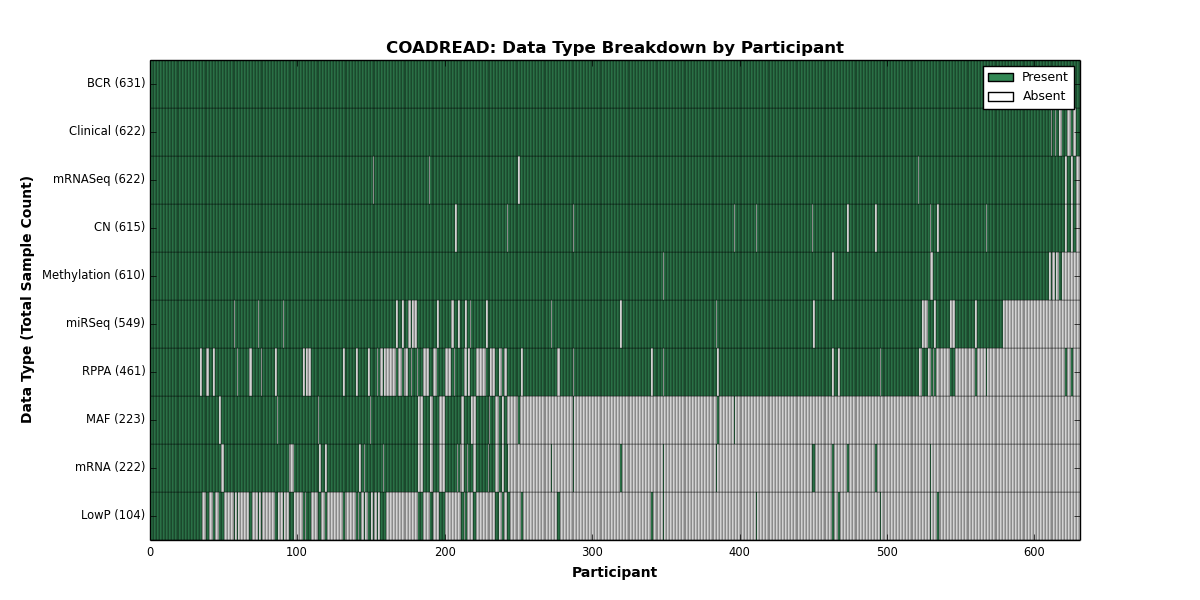
Figure 8. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
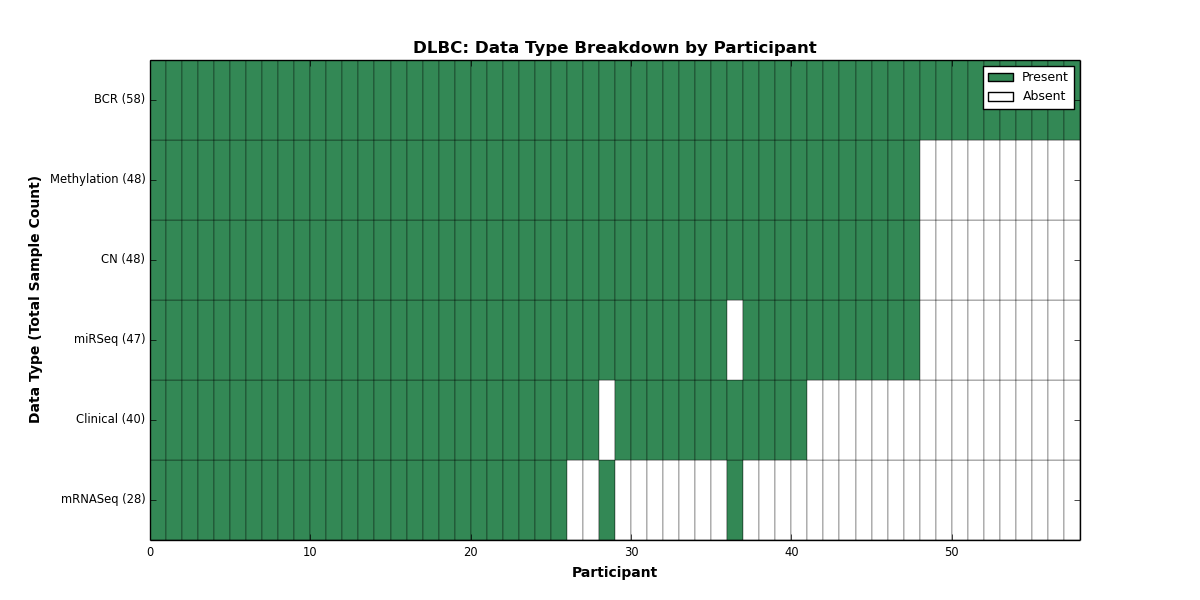
Figure 9. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
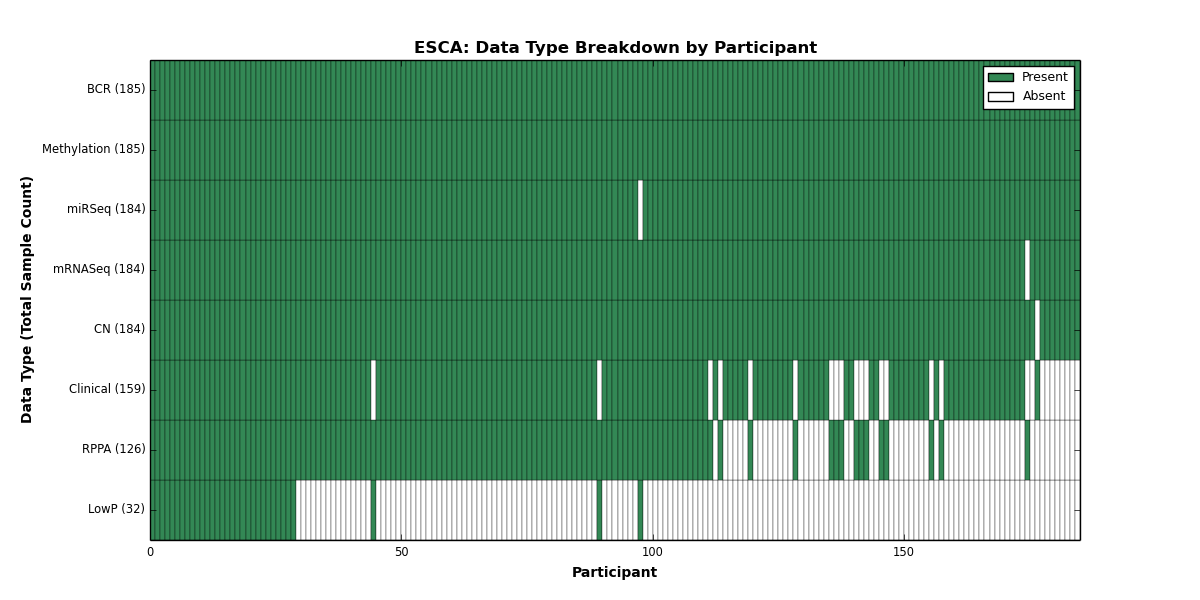
Figure 10. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
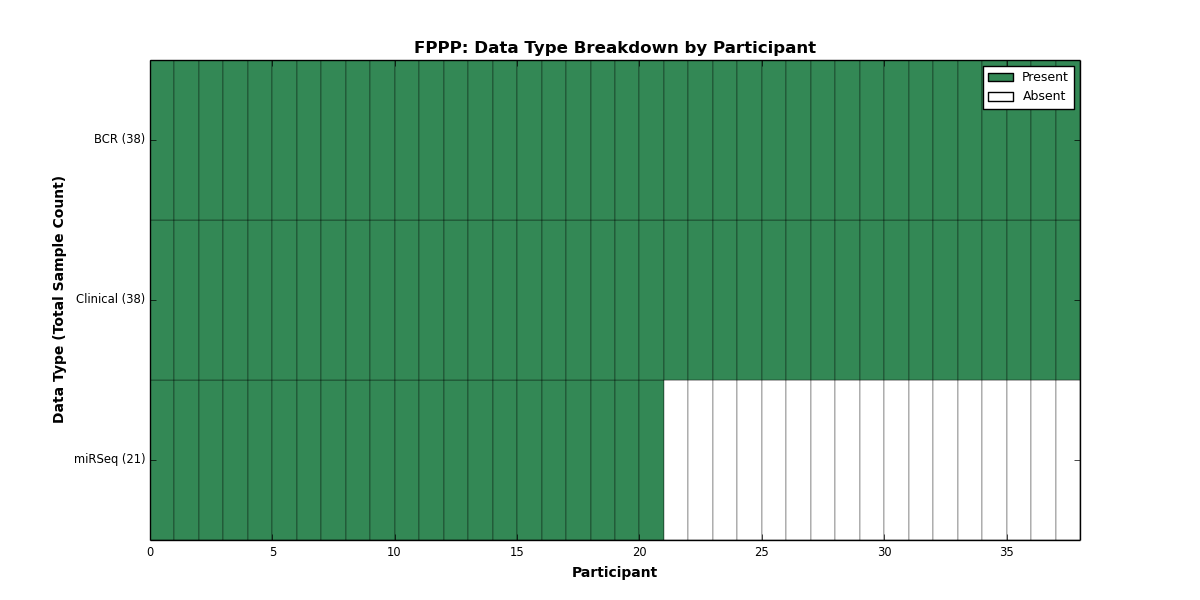
Figure 11. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
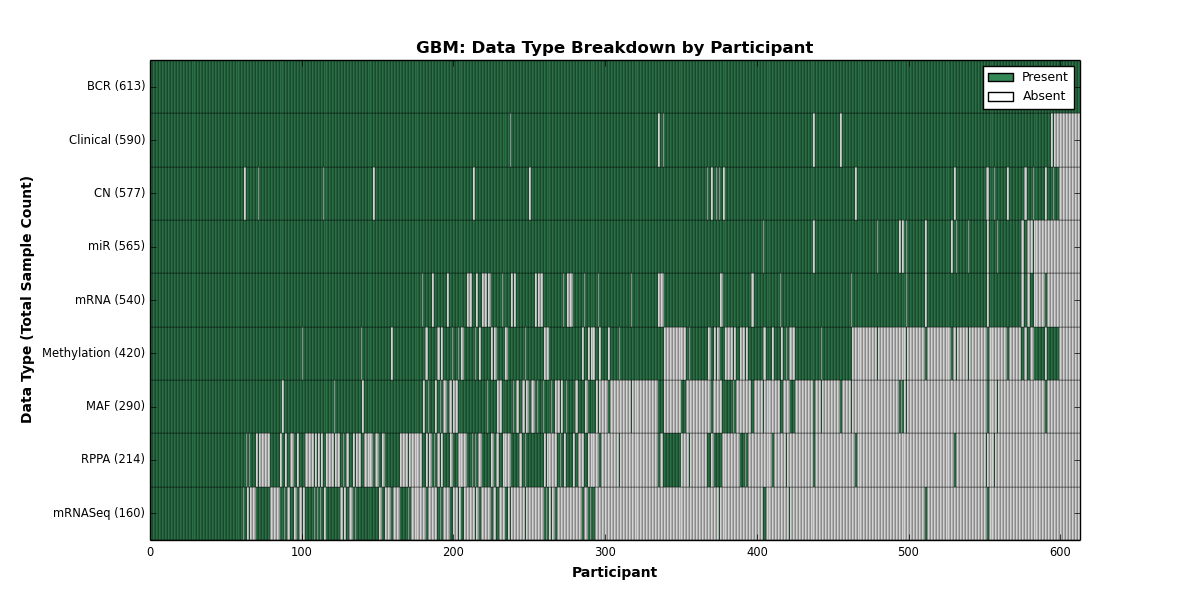
Figure 12. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
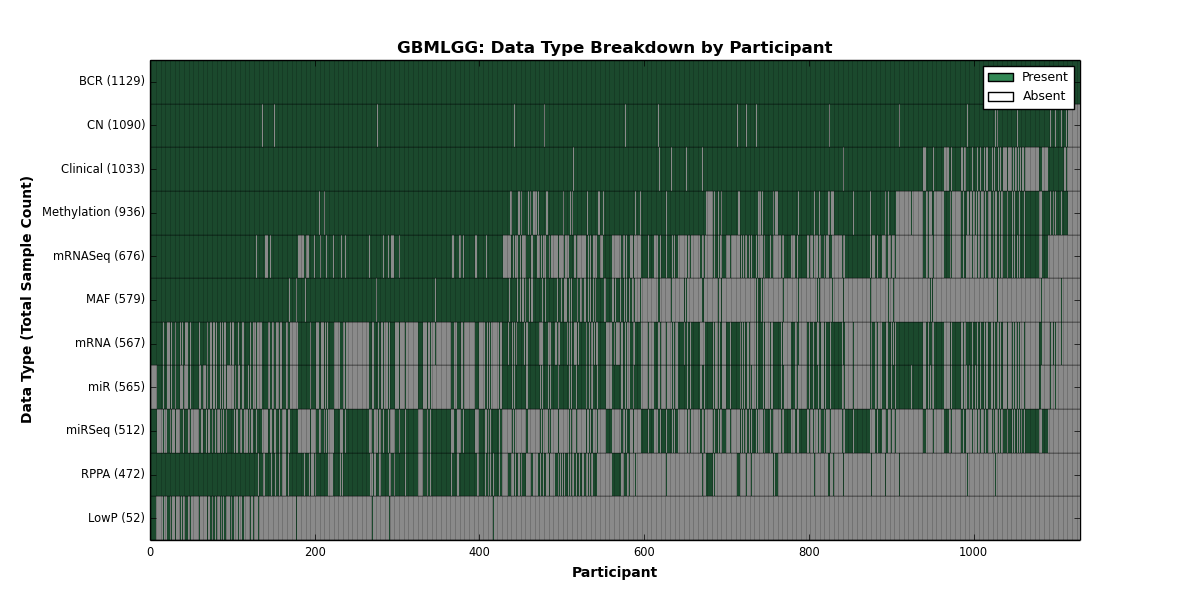
Figure 13. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
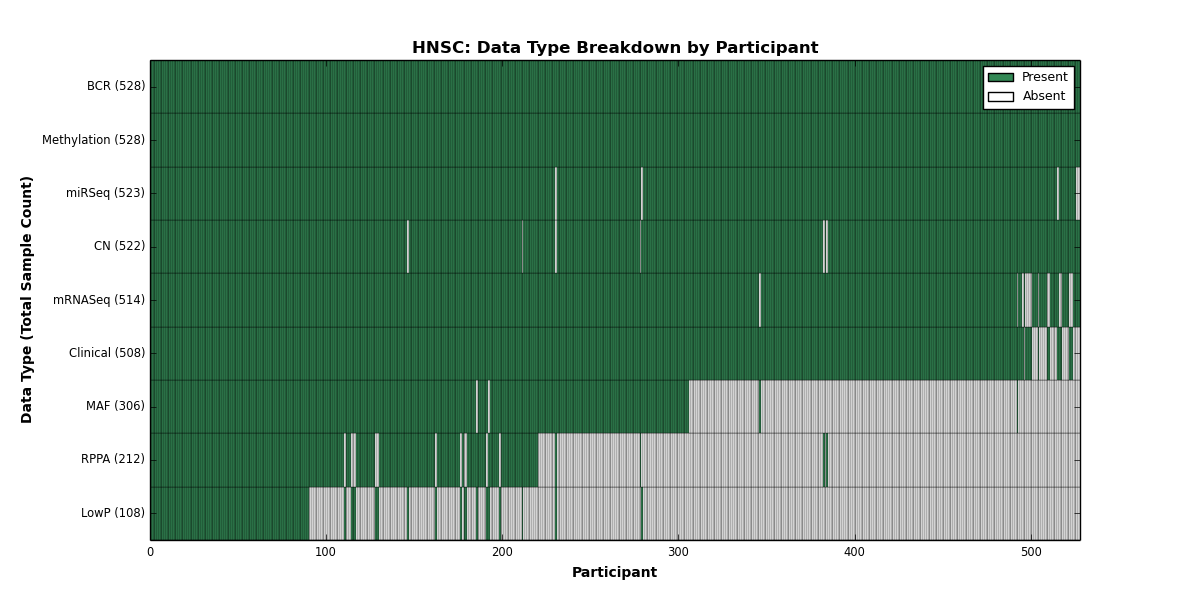
Figure 14. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
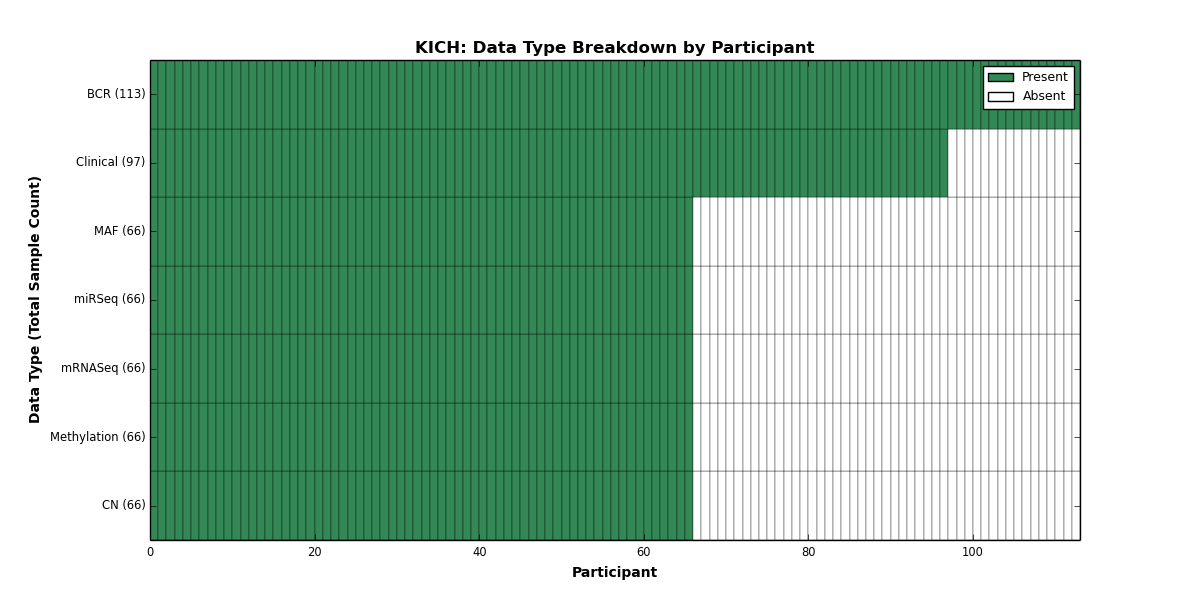
Figure 15. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
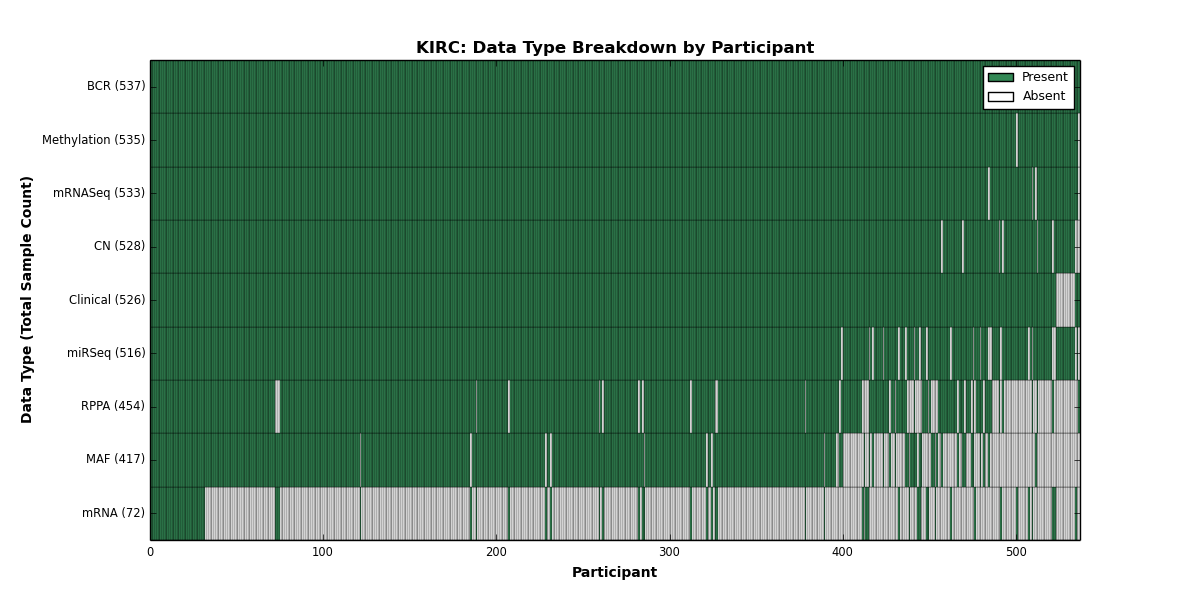
Figure 16. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
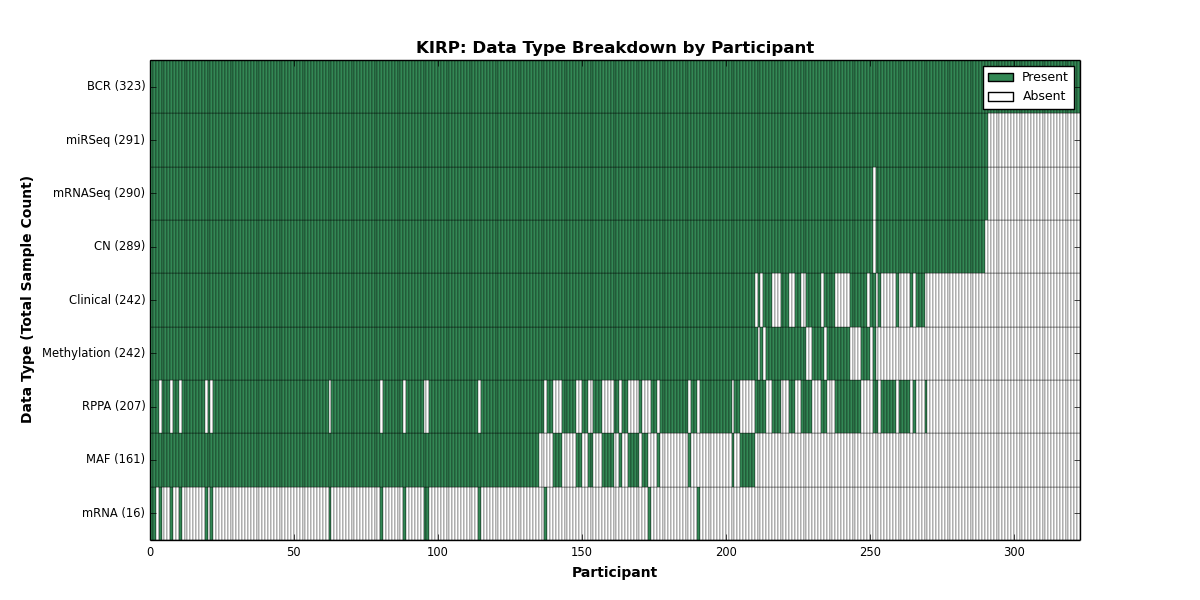
Figure 17. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
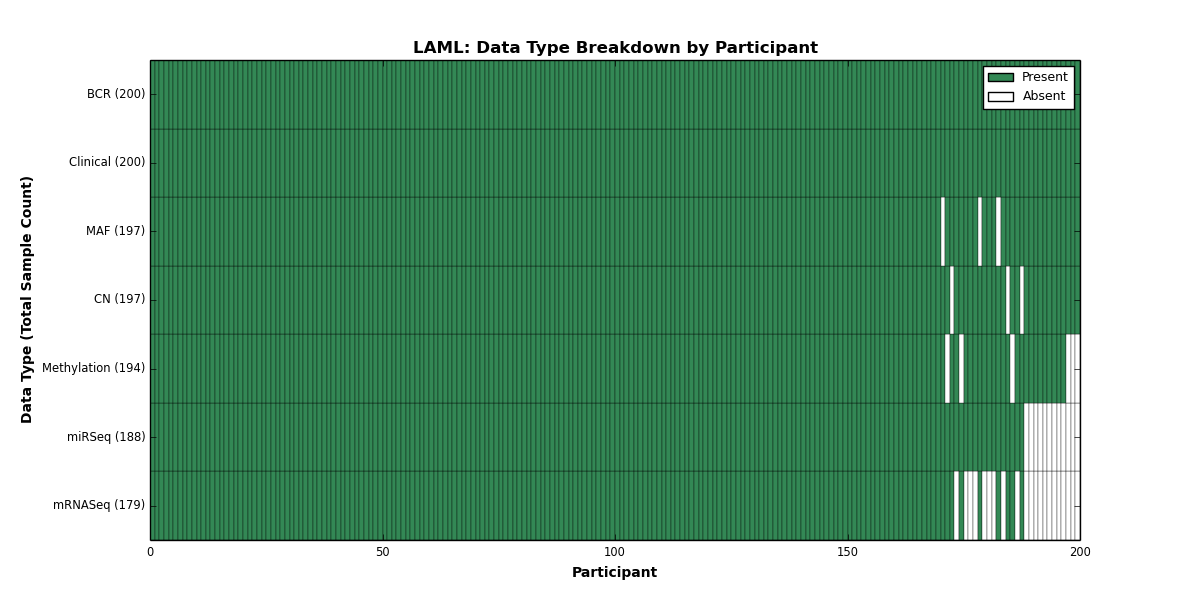
Figure 18. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
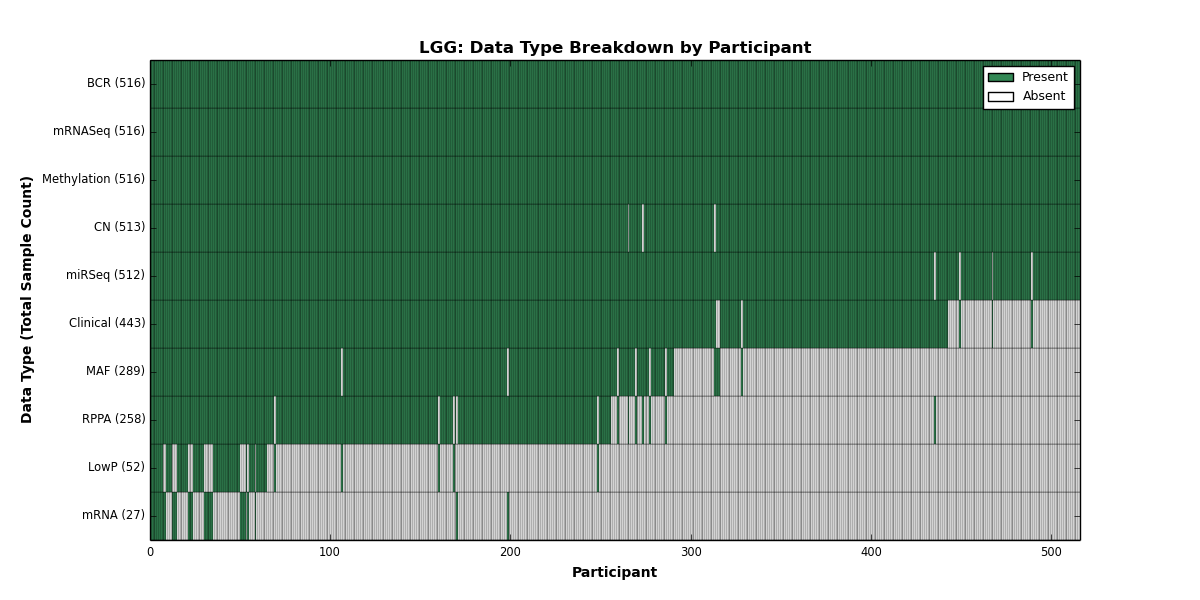
Figure 19. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
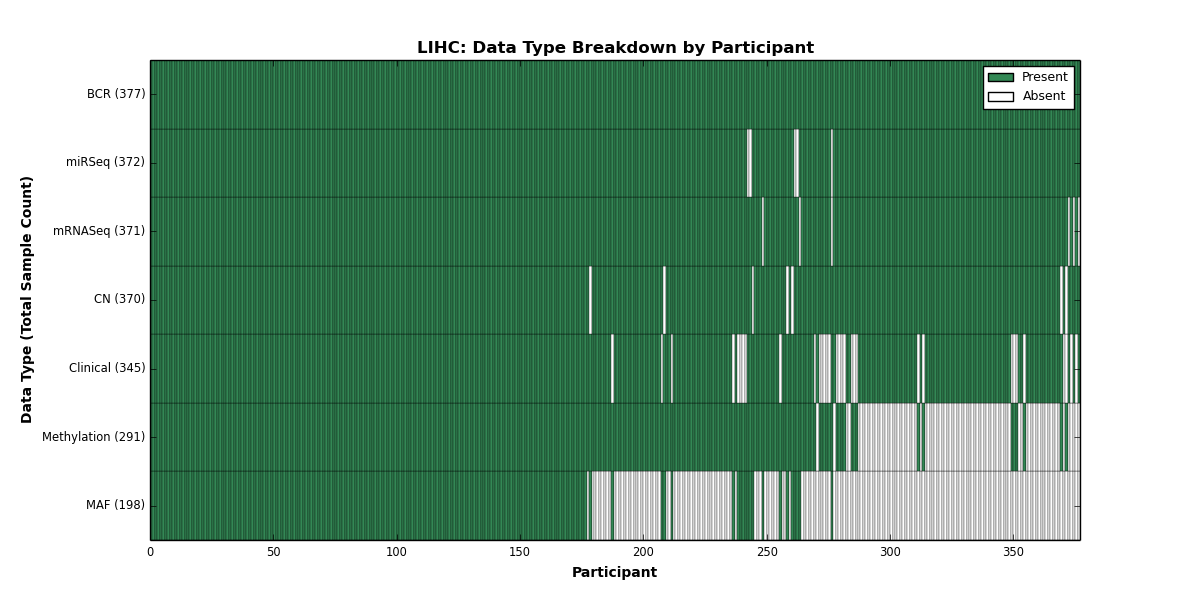
Figure 20. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
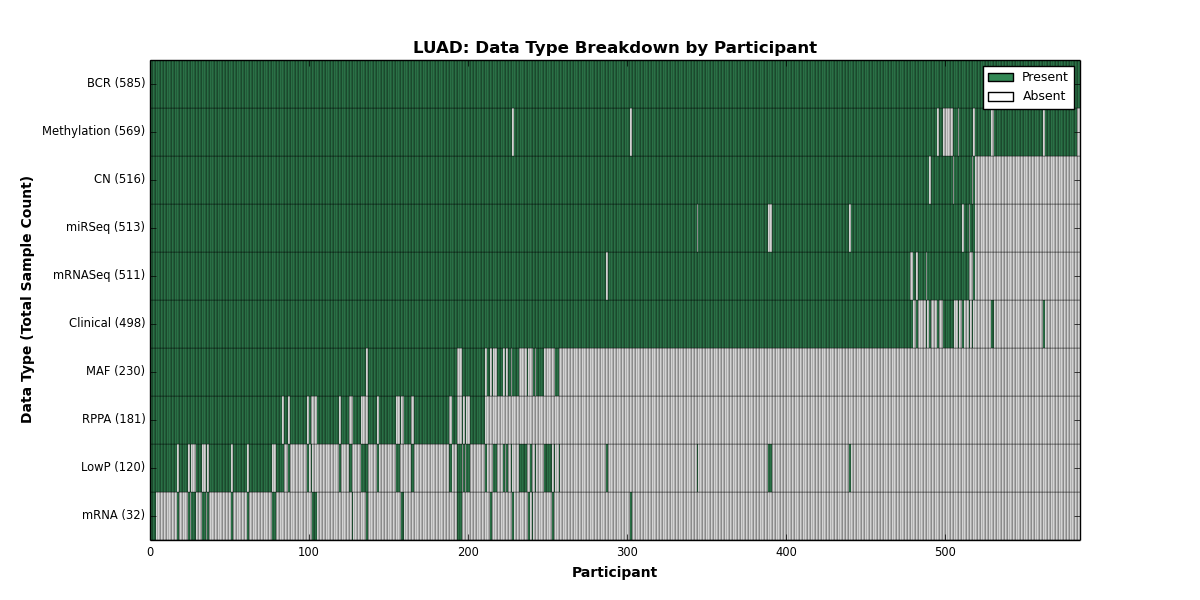
Figure 21. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
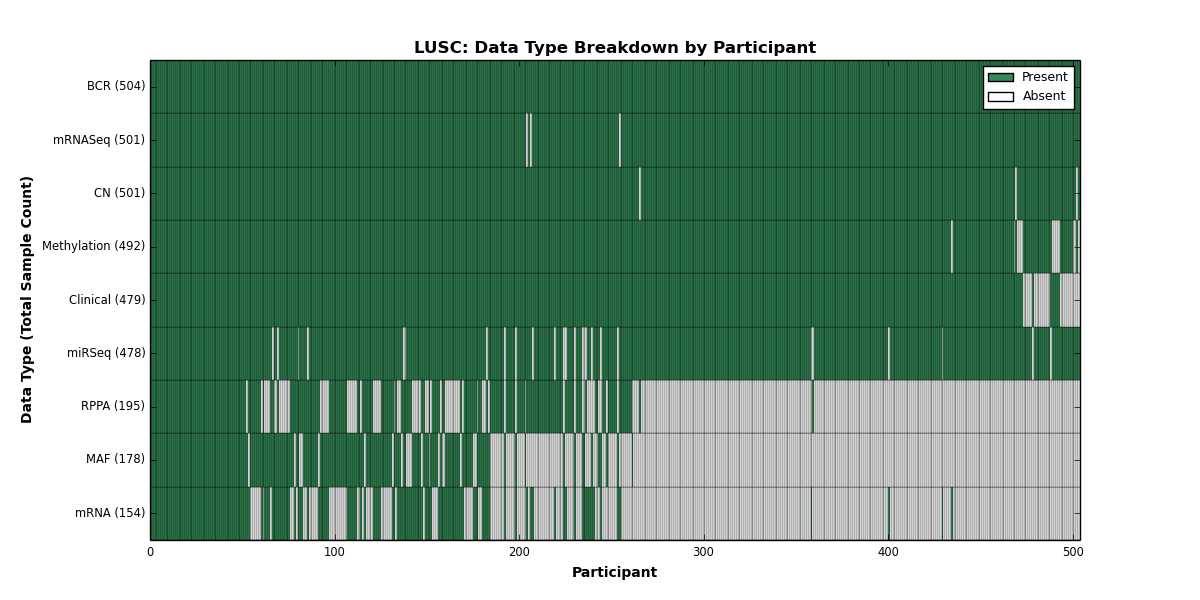
Figure 22. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
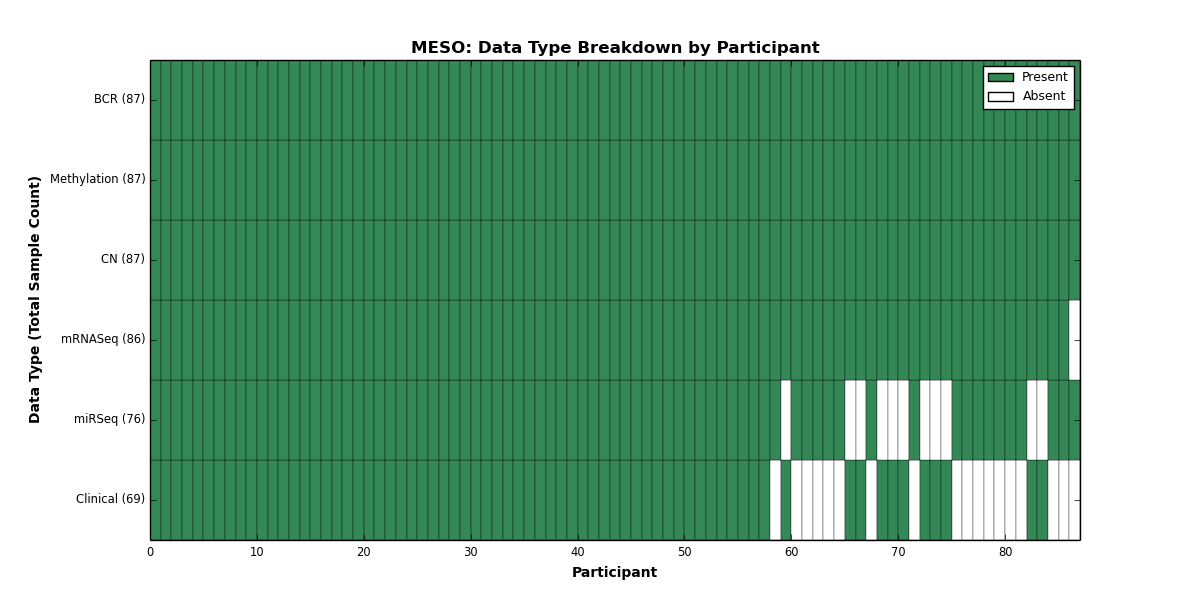
Figure 23. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
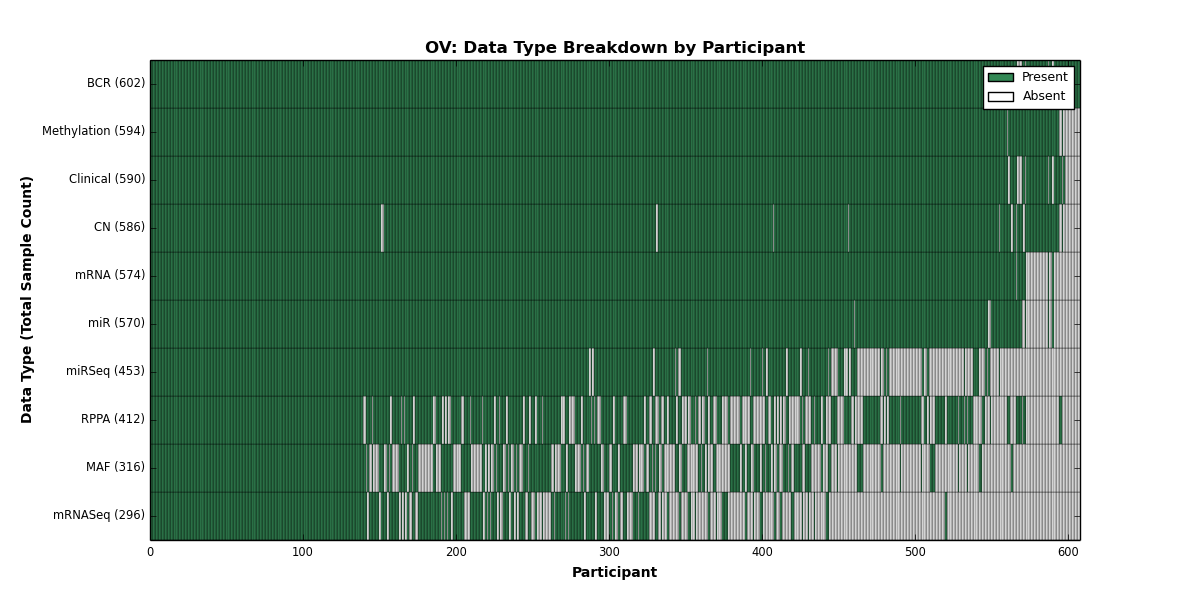
Figure 24. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
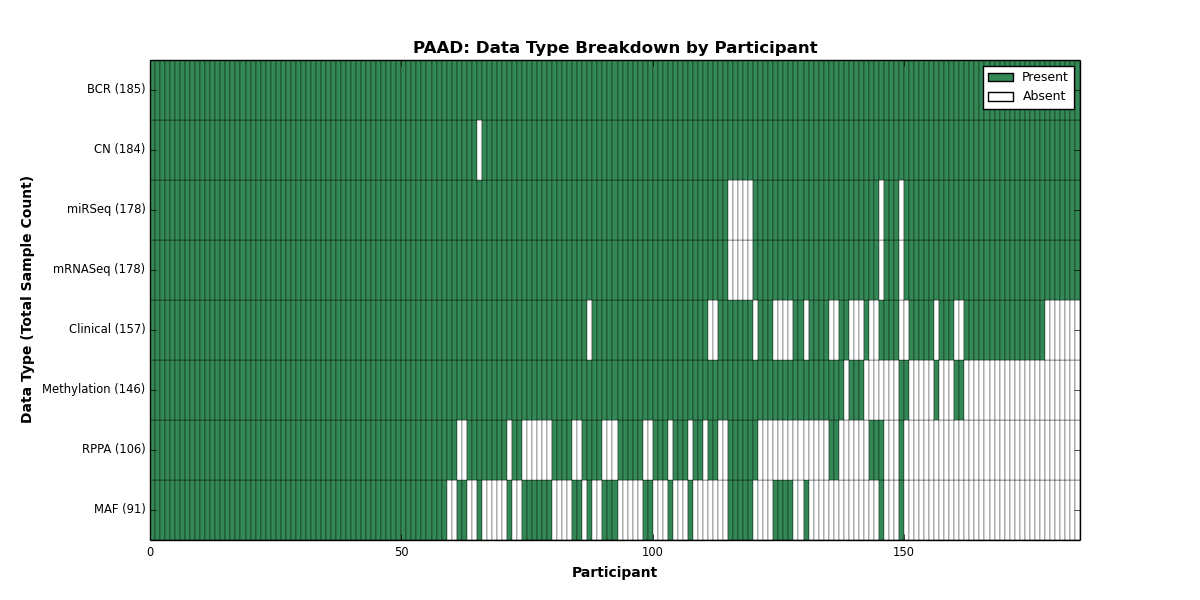
Figure 25. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
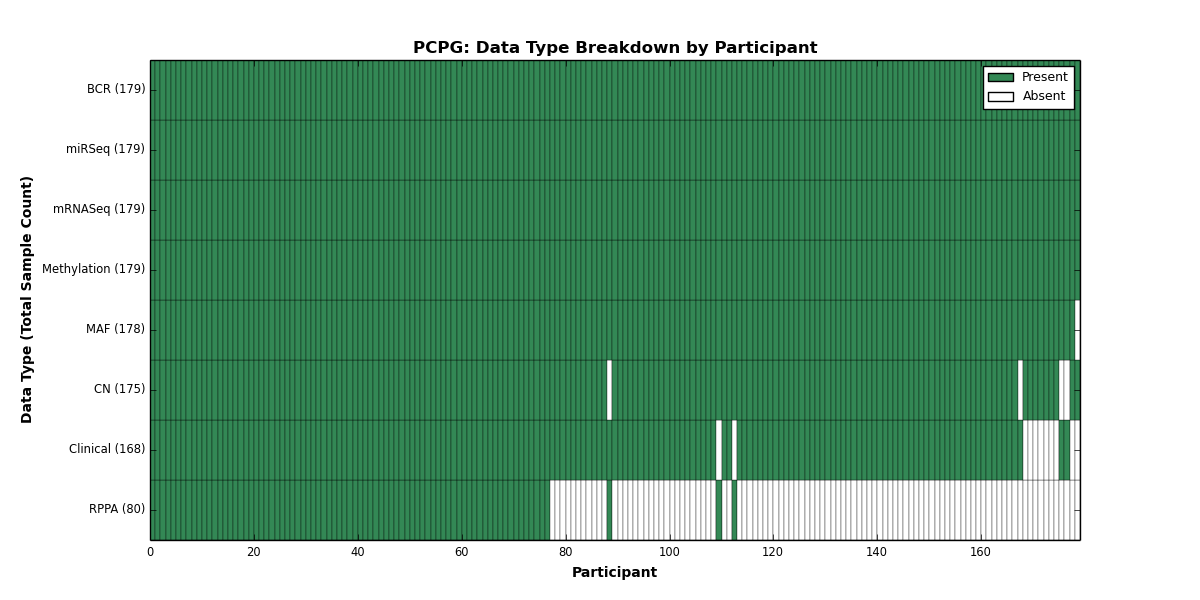
Figure 26. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
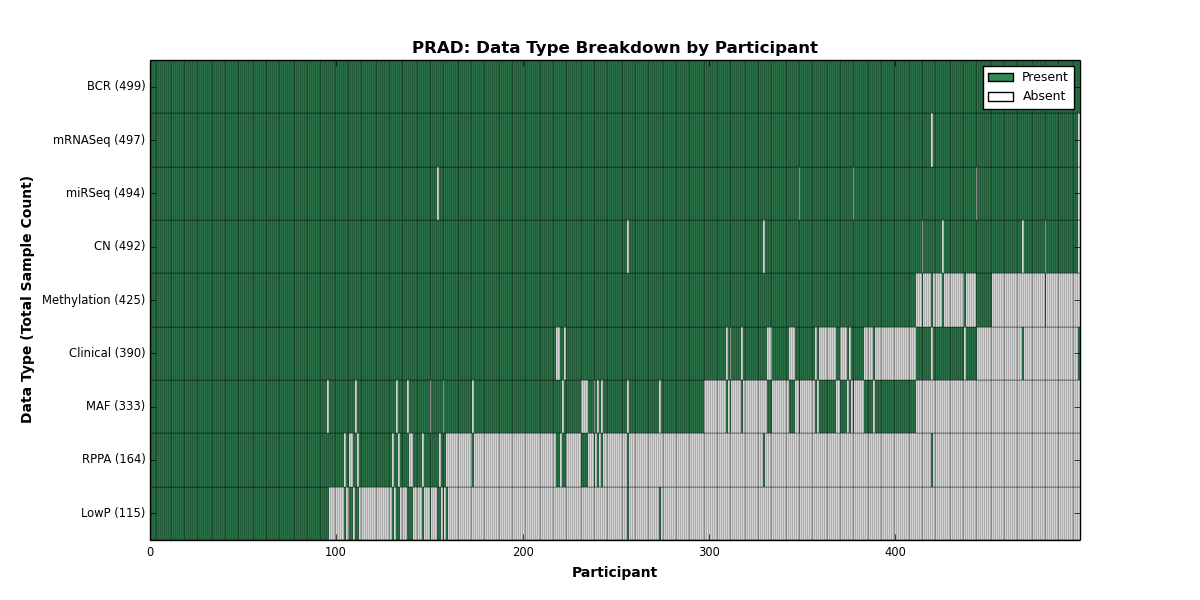
Figure 27. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
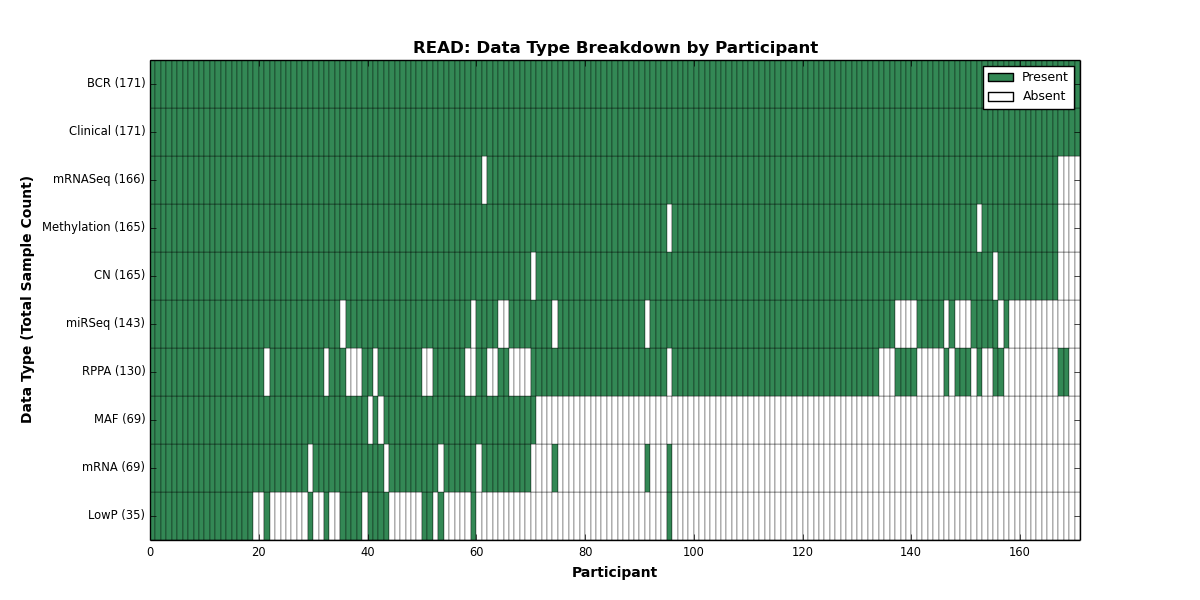
Figure 28. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
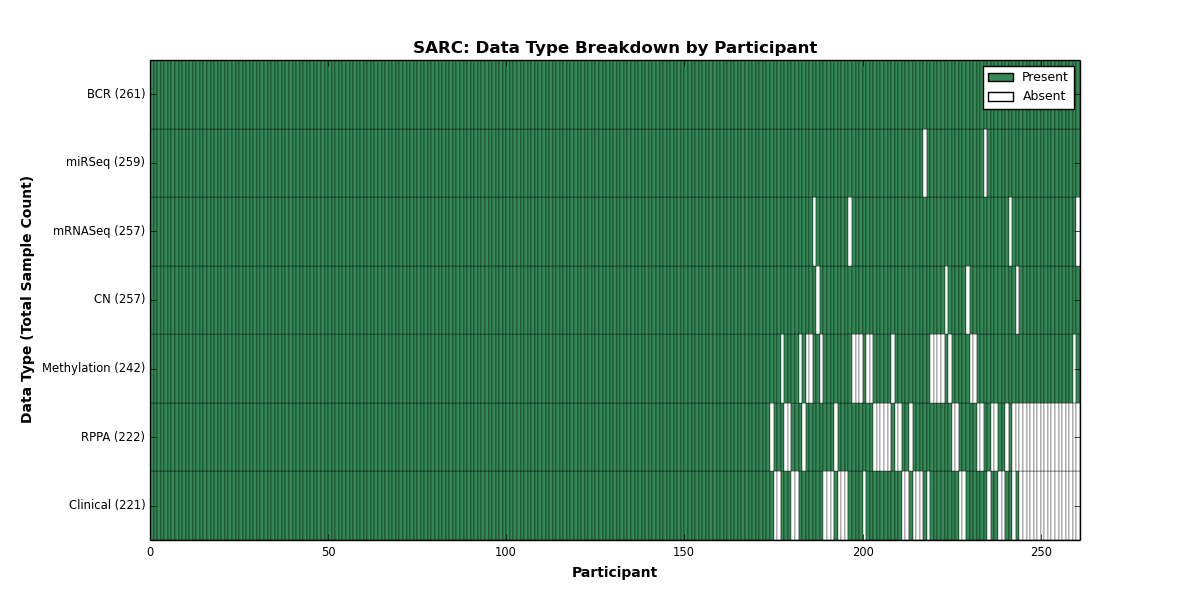
Figure 29. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
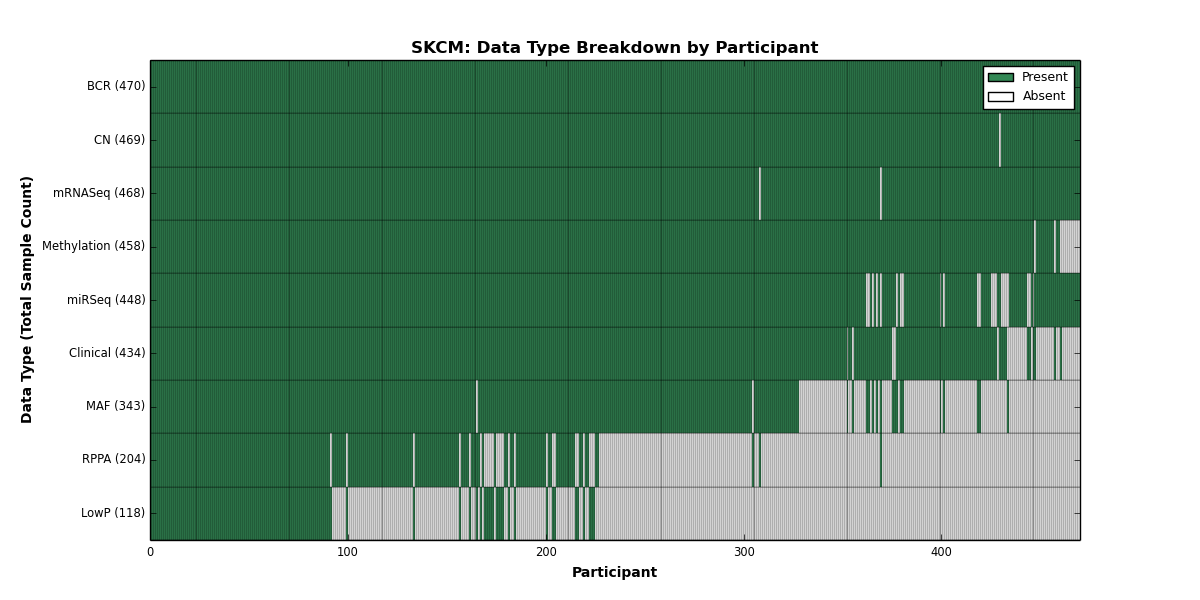
Figure 30. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
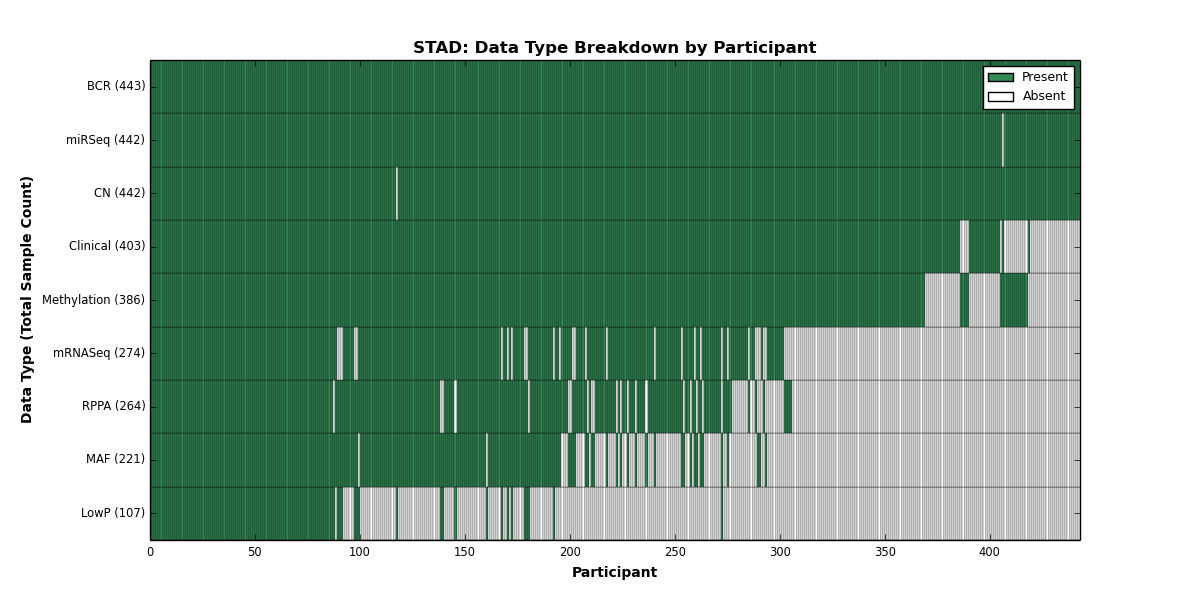
Figure 31. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
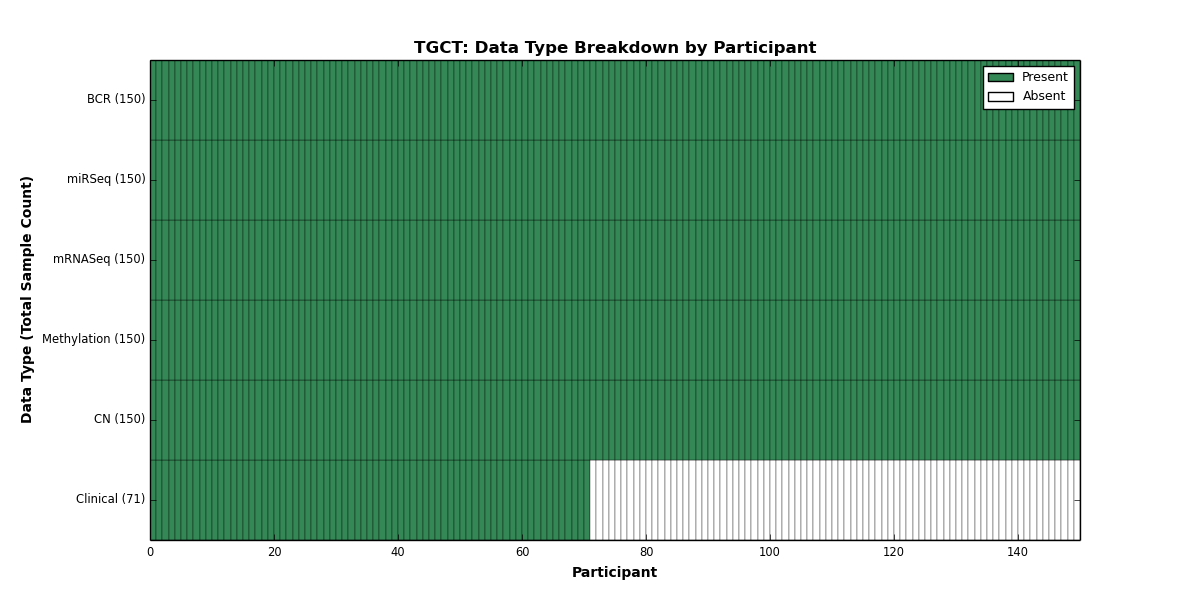
Figure 32. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
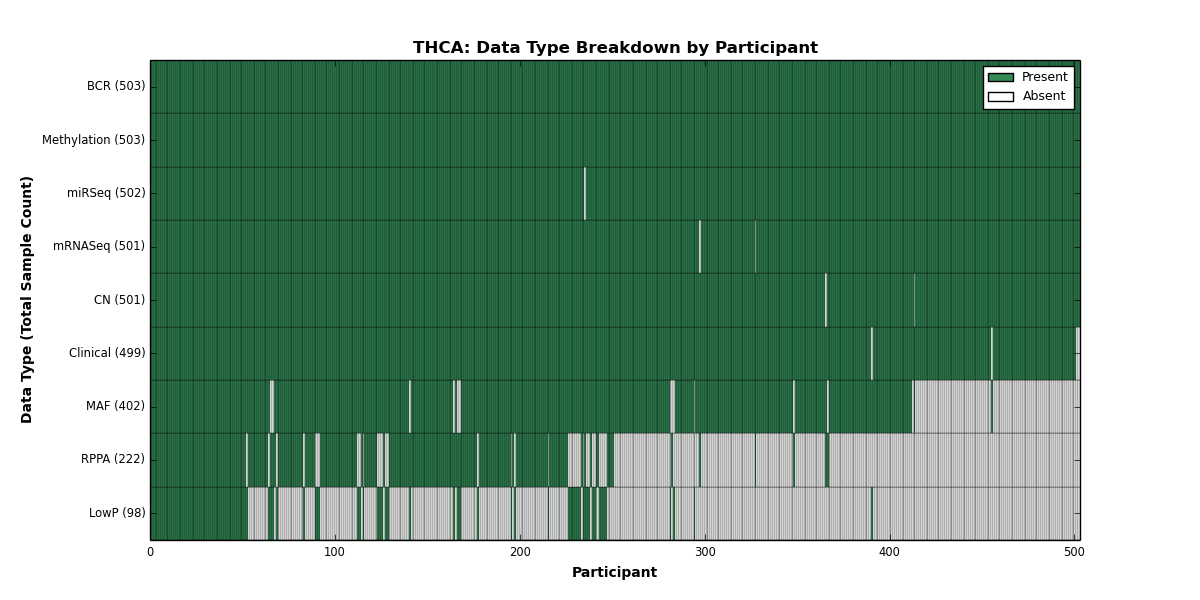
Figure 33. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
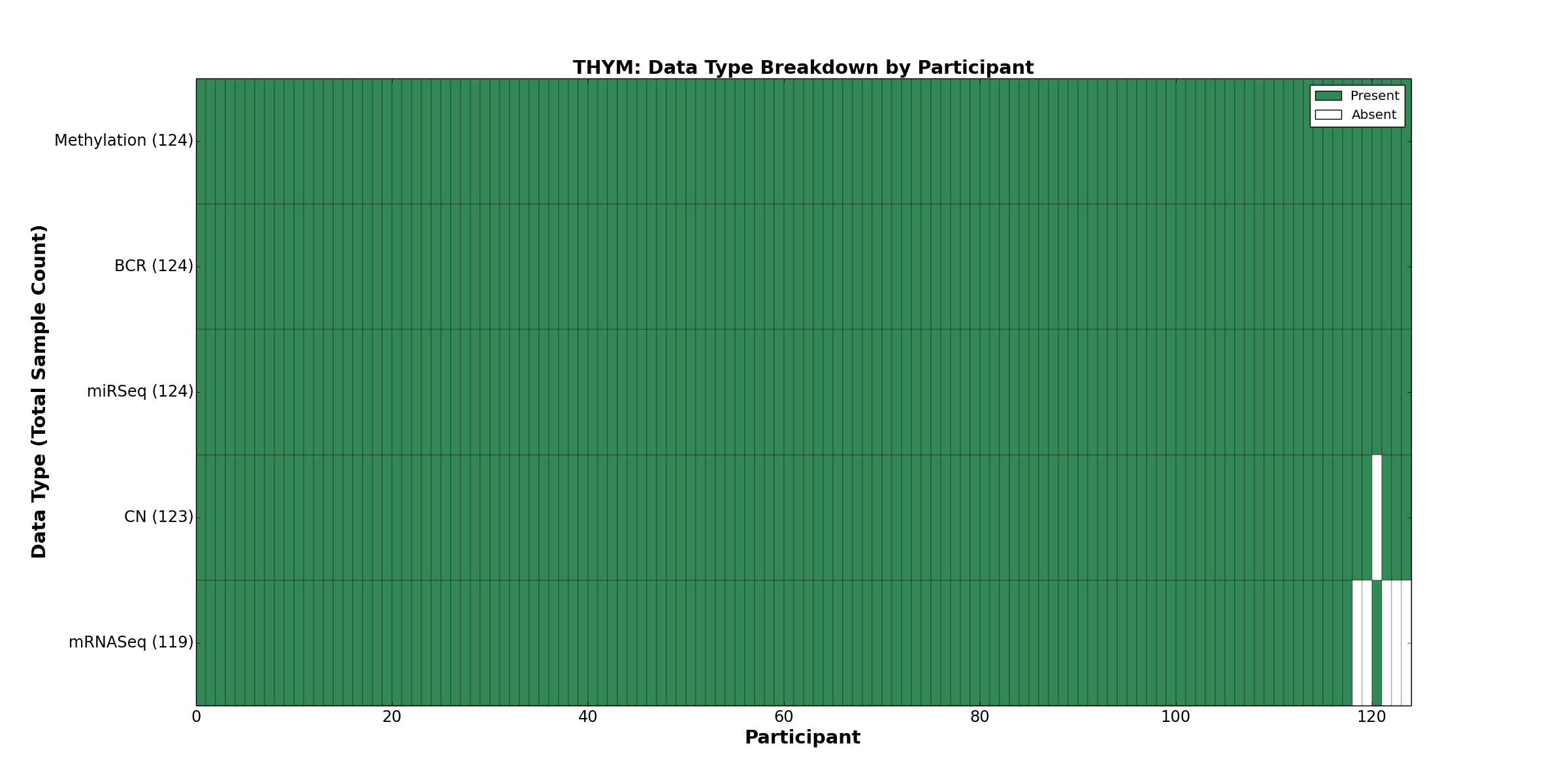{kind=link}
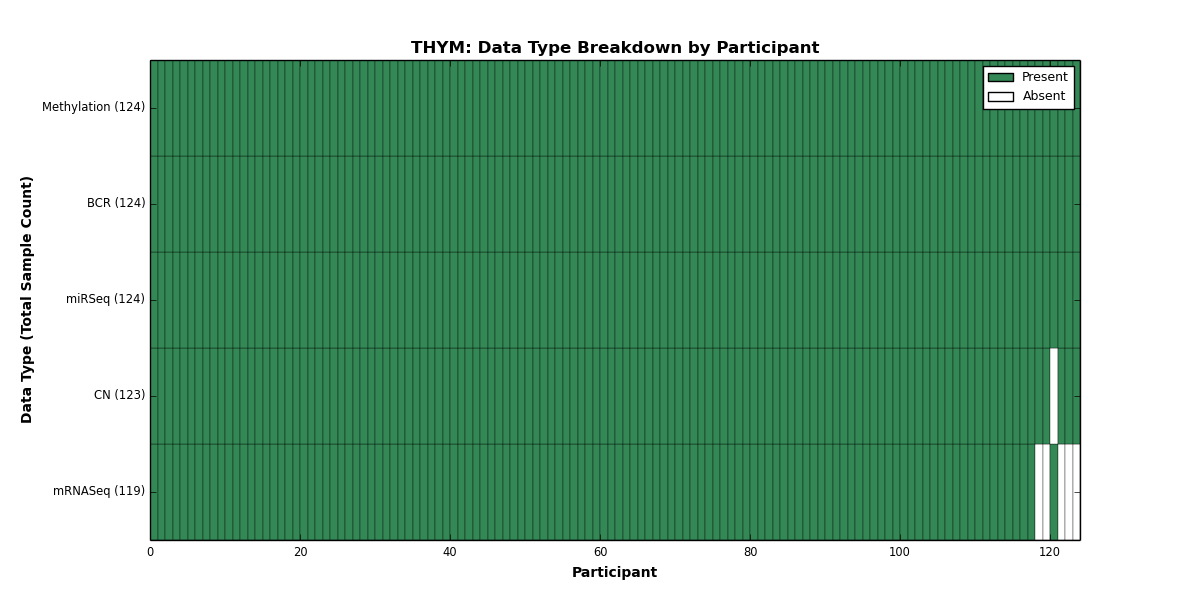
Figure 34. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
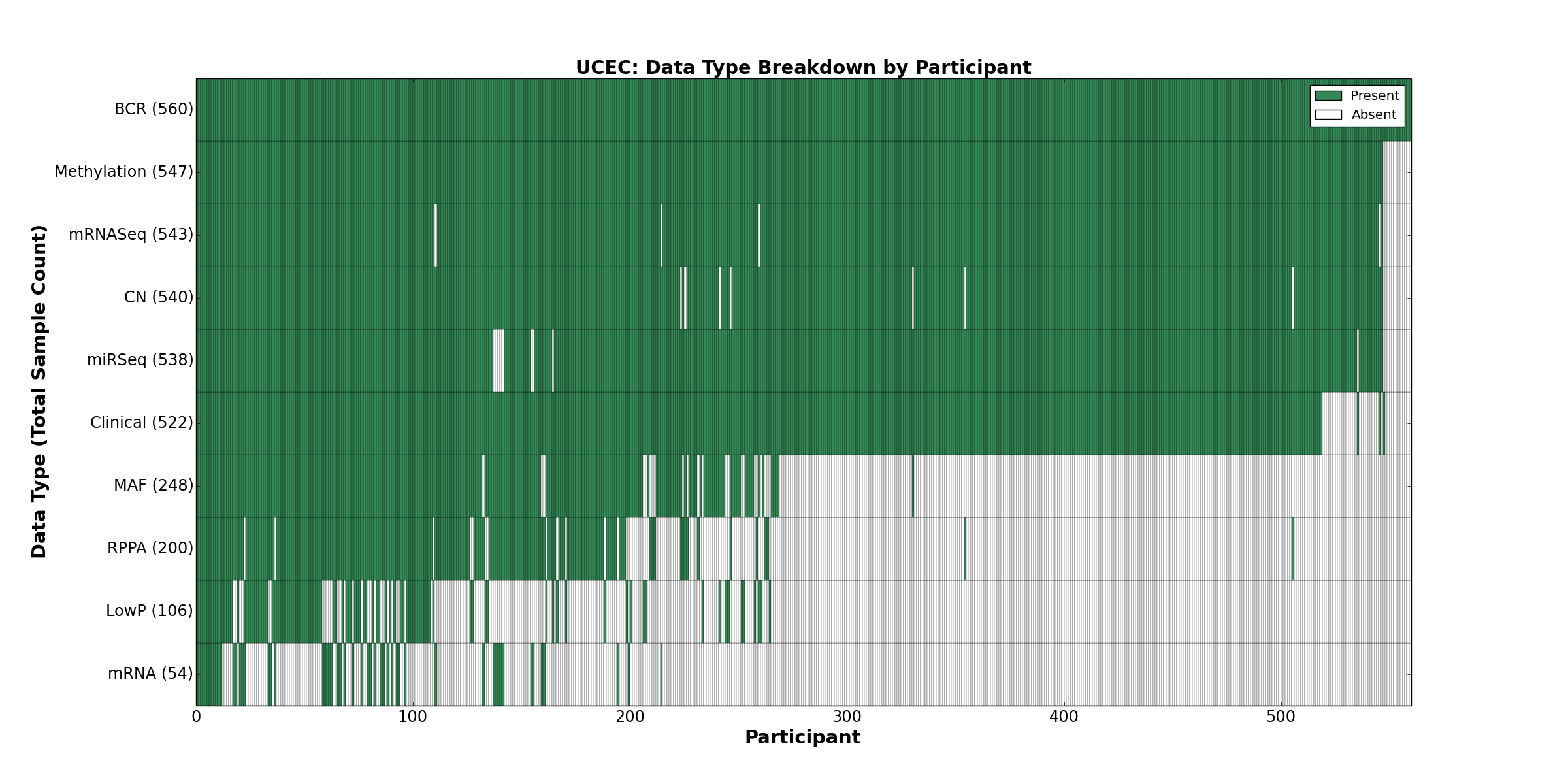{kind=link}
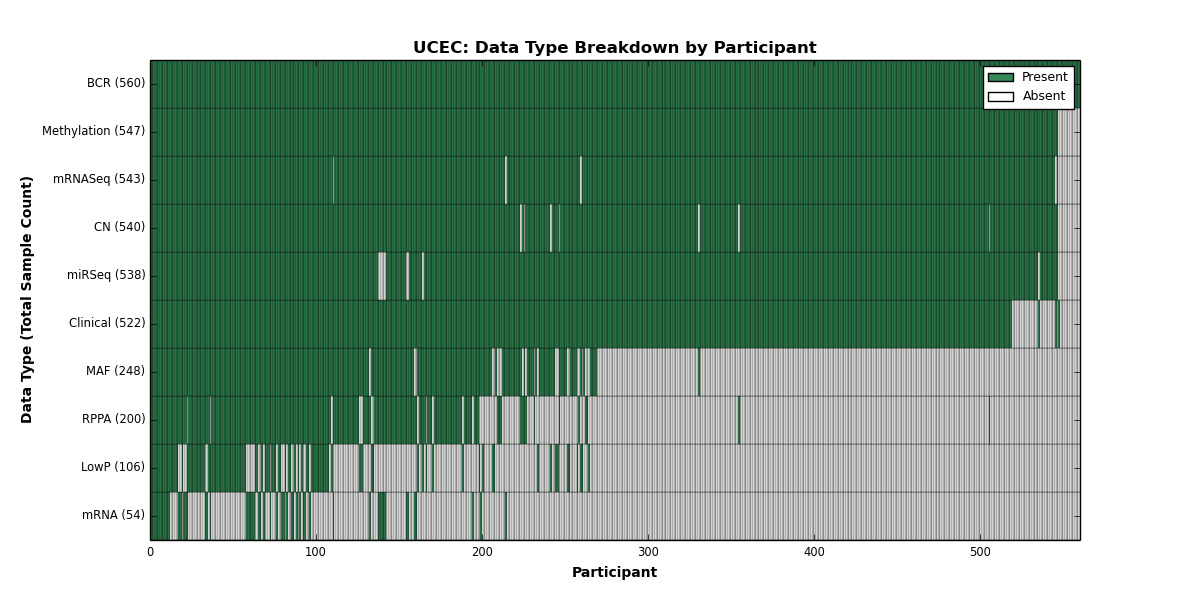
Figure 35. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
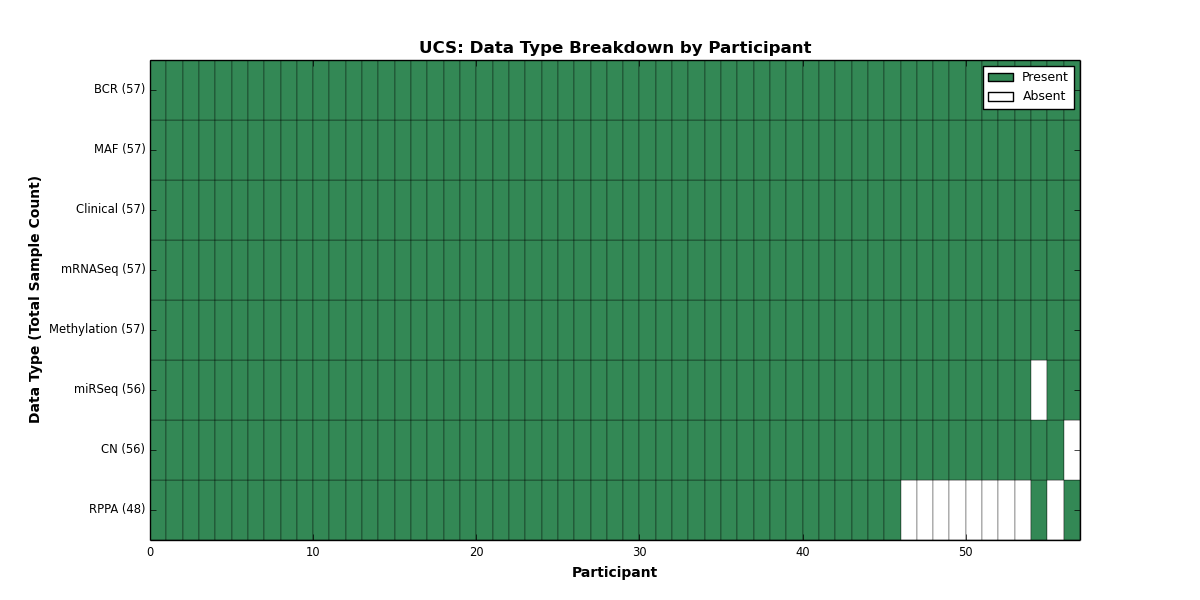
Figure 36. Get High-res Image This figure depicts the distribution of available data on a per participant basis.
{kind=link}
Annotation data was taken from theTCGA Data Portalusing the query string:
https://tcga-data.nci.nih.gov/annotations/resources/searchannotations/json?item=TCGA
Redaction information was generated by filtering for the annotationClassificationName "Redaction"
FFPE information was generated by filtering for "FFPE" in annotation note text
Additional FFPEs were garnered from clinical data
Remaining annotations were sorted into sections by annotationClassificationName
The mRNA preprocess median module chooses the matrix for the platform(Affymetrix HG U133, Affymetrix Exon Array and Agilent Gene Expression) with the largest number of samples.
The mRNAseq preprocessor picks the "scaled_estimate" (RSEM) value from Illumina HiSeq/GA2 mRNAseq level_3 (v2) data set and makes the mRNAseq matrix with log2 transformed for the downstream analysis. If there are overlap samples between two different platforms, samples from illumina hiseq will be selected. The pipeline also creates the matrix with RPKM and log2 transform from HiSeq/GA2 mRNAseq level 3 (v1) data set.
The miRseq preprocessor picks the "RPM" (reads per million miRNA precursor reads) from the Illumina HiSeq/GA miRseq Level_3 data set and makes the matrix with log2 transformed values.
The methylation preprocessor filters methylation data for use in downstream pipelines. To learn more about this preprocessor, please visit the documentation.