This report serves to describe the mutational landscape and properties of a given individual set, as well as rank genes and genesets according to mutational significance. MutSig v2.0 was used to generate the results found in this report.
-
Working with individual set: READ-TP
-
Number of patients in set: 69
The input for this pipeline is a set of individuals with the following files associated for each:
-
An annotated .maf file describing the mutations called for the respective individual, and their properties.
-
A .wig file that contains information about the coverage of the sample.
-
MAF used for this analysis:READ-TP.final_analysis_set.maf
-
Significantly mutated genes (q ≤ 0.1): 15
-
Mutations seen in COSMIC: 222
-
Significantly mutated genes in COSMIC territory: 10
-
Genes with clustered mutations (≤ 3 aa apart): 117
-
Significantly mutated genesets: 111
-
Significantly mutated genesets: (excluding sig. mutated genes):0
-
Read 38 MAFs of type "Broad"
-
Read 35 MAFs of type "Baylor"
-
Total number of mutations in input MAFs: 29413
-
After removing 257 invalidated mutations: 29156
-
After removing 200 noncoding mutations: 28956
-
After collapsing adjacent/redundant mutations: 21679
-
Number of mutations before filtering: 21679
-
After removing 200 mutations outside gene set: 21479
-
After removing 172 mutations outside category set: 21307
-
After removing 2 "impossible" mutations in
-
gene-patient-category bins of zero coverage: 20933
Table 1. Get Full Table Table representing breakdown of mutations by type.
| type | count |
|---|---|
| De_novo_Start_InFrame | 4 |
| De_novo_Start_OutOfFrame | 30 |
| Frame_Shift_Del | 151 |
| Frame_Shift_Ins | 155 |
| In_Frame_Del | 27 |
| In_Frame_Ins | 7 |
| Missense_Mutation | 14471 |
| Nonsense_Mutation | 1779 |
| Nonstop_Mutation | 6 |
| Read-through | 10 |
| Silent | 4629 |
| Splice_Site | 38 |
| Total | 21307 |
Table 2. Get Full Table A breakdown of mutation rates per category discovered for this individual set.
| category | n | N | rate | rate_per_mb | relative_rate |
|---|---|---|---|---|---|
| *CpG->T | 4919 | 99673101 | 0.000049 | 49 | 5.4 |
| *Cp(A/C/T)->mut | 6673 | 832257993 | 8e-06 | 8 | 0.89 |
| A->mut | 2743 | 908854391 | 3e-06 | 3 | 0.33 |
| *CpG->(G/A) | 135 | 99673101 | 1.4e-06 | 1.4 | 0.15 |
| indel+null | 2050 | 1840785523 | 1.1e-06 | 1.1 | 0.12 |
| double_null | 157 | 1840785523 | 8.5e-08 | 0.085 | 0.0094 |
| Total | 16677 | 1840785523 | 9.1e-06 | 9.1 | 1 |
The x axis represents the samples. The y axis represents the exons, one row per exon, and they are sorted by average coverage across samples. For exons with exactly the same average coverage, they are sorted next by the %GC of the exon. (The secondary sort is especially useful for the zero-coverage exons at the bottom).
Figure 1.
Figure 2. Patients counts and rates file used to generate this plot: READ-TP.patients.counts_and_rates.txt
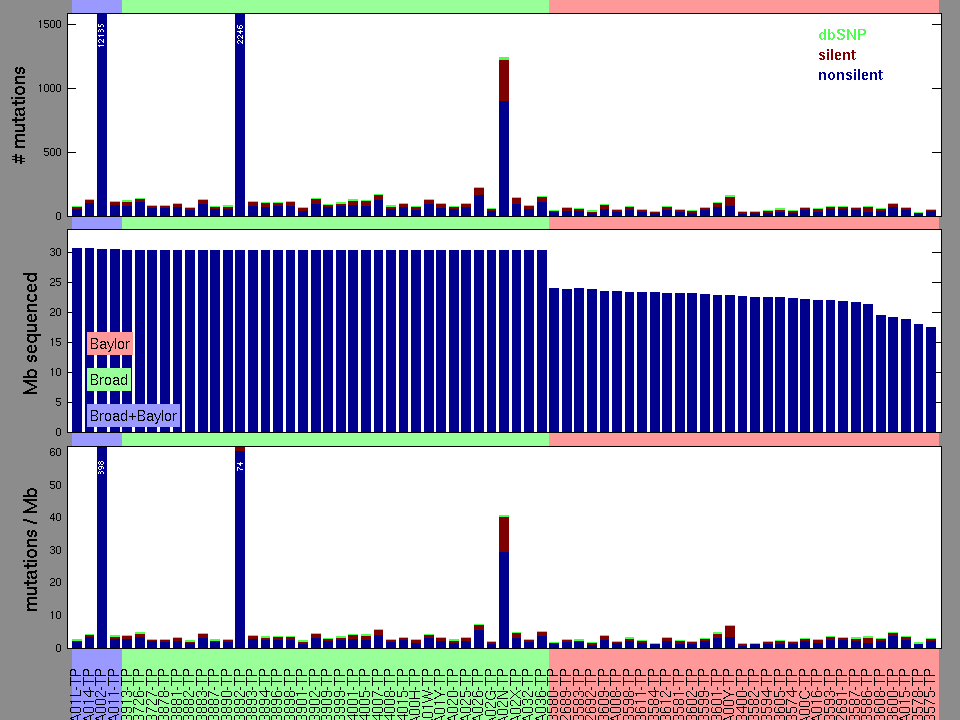
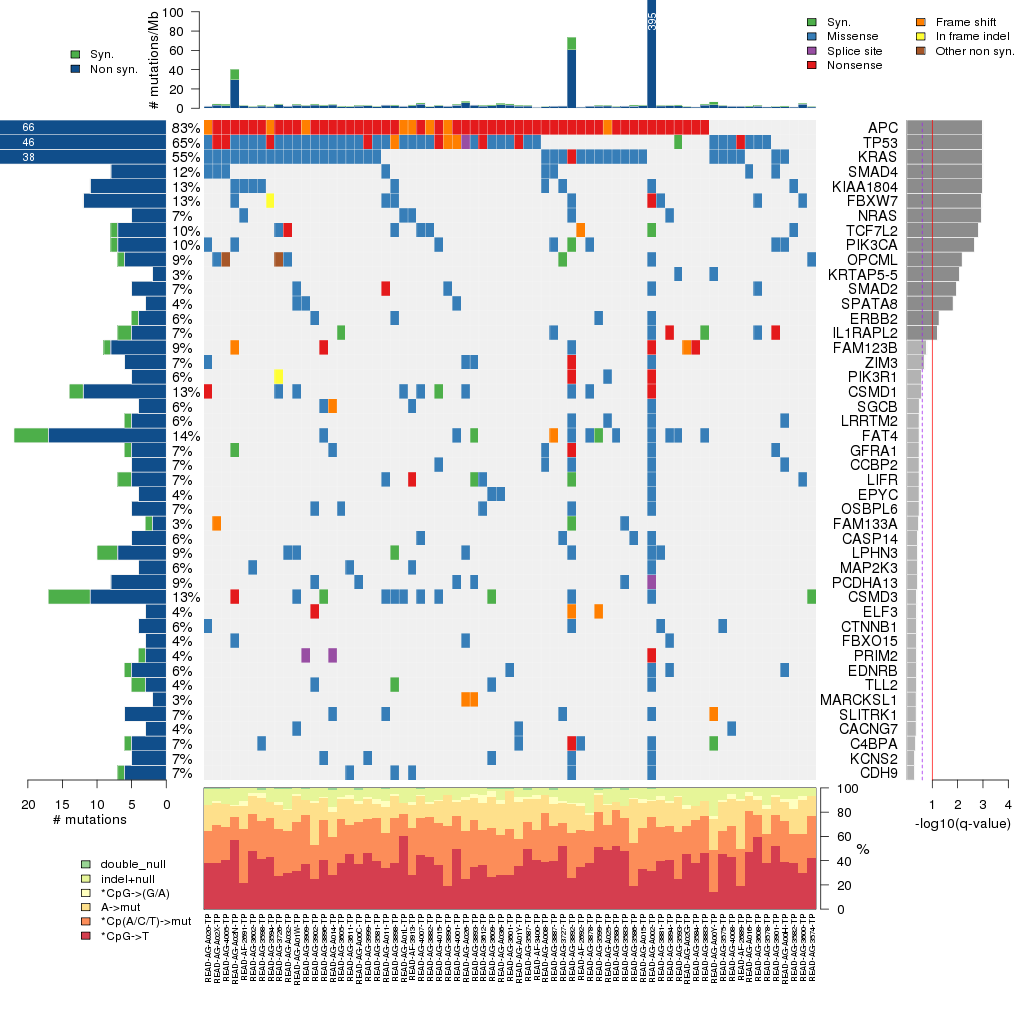
Figure 3. Get High-res Image The matrix in the center of the figure represents individual mutations in patient samples, color-coded by type of mutation, for the significantly mutated genes. The rate of synonymous and non-synonymous mutations is displayed at the top of the matrix. The barplot on the left of the matrix shows the number of mutations in each gene. The percentages represent the fraction of tumors with at least one mutation in the specified gene. The barplot to the right of the matrix displays the q-values for the most significantly mutated genes. The purple boxplots below the matrix (only displayed if required columns are present in the provided MAF) represent the distributions of allelic fractions observed in each sample. The plot at the bottom represents the base substitution distribution of individual samples, using the same categories that were used to calculate significance.
Column Descriptions:
-
N = number of sequenced bases in this gene across the individual set
-
n = number of (nonsilent) mutations in this gene across the individual set
-
npat = number of patients (individuals) with at least one nonsilent mutation
-
nsite = number of unique sites having a non-silent mutation
-
nsil = number of silent mutations in this gene across the individual set
-
n1 = number of nonsilent mutations of type: *CpG->T
-
n2 = number of nonsilent mutations of type: *Cp(A/C/T)->mut
-
n3 = number of nonsilent mutations of type: A->mut
-
n4 = number of nonsilent mutations of type: *CpG->(G/A)
-
n5 = number of nonsilent mutations of type: indel+null
-
n6 = number of nonsilent mutations of type: double_null
-
p_classic = p-value for the observed amount of nonsilent mutations being elevated in this gene
-
p_cons = p-value for enrichment of mutations at evolutionarily most-conserved sites in gene
-
p_joint = p-value for clustering + conservation
-
p = p-value (overall)
-
q = q-value, False Discovery Rate (Benjamini-Hochberg procedure)
Table 3. Get Full Table A Ranked List of Significantly Mutated Genes. Number of significant genes found: 15. Number of genes displayed: 35. Click on a gene name to display its stick figure depicting the distribution of mutations and mutation types across the chosen gene (this feature may not be available for all significant genes).
| rank | gene | description | N | n | npat | nsite | nsil | n1 | n2 | n3 | n4 | n5 | n6 | p_classic | p_cons | p_joint | p | q |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | APC | adenomatous polyposis coli | 576224 | 66 | 57 | 56 | 0 | 1 | 4 | 4 | 0 | 39 | 18 | 3.9e-15 | 0.97 | 0 | <1.00e-15 | <5.97e-12 |
| 2 | TP53 | tumor protein p53 | 79667 | 45 | 45 | 30 | 1 | 19 | 6 | 6 | 2 | 12 | 0 | 1.2e-15 | 6e-07 | 0 | <1.00e-15 | <5.97e-12 |
| 3 | KRAS | v-Ki-ras2 Kirsten rat sarcoma viral oncogene homolog | 48604 | 38 | 38 | 8 | 0 | 0 | 36 | 1 | 0 | 1 | 0 | 6e-15 | 0.0029 | 0 | <1.00e-15 | <5.97e-12 |
| 4 | SMAD4 | SMAD family member 4 | 115264 | 8 | 8 | 6 | 0 | 2 | 3 | 3 | 0 | 0 | 0 | 8.1e-11 | 0.2 | 0.26 | 5.42e-10 | 2.43e-06 |
| 5 | KIAA1804 | 162266 | 11 | 9 | 9 | 0 | 7 | 3 | 1 | 0 | 0 | 0 | 1.2e-08 | 0.051 | 0.05 | 1.39e-08 | 4.97e-05 | |
| 6 | FBXW7 | F-box and WD repeat domain containing 7 | 177744 | 12 | 9 | 10 | 0 | 6 | 2 | 2 | 0 | 2 | 0 | 2e-08 | 0.08 | 0.079 | 3.26e-08 | 9.74e-05 |
| 7 | NRAS | neuroblastoma RAS viral (v-ras) oncogene homolog | 40433 | 5 | 5 | 4 | 0 | 0 | 3 | 2 | 0 | 0 | 0 | 1.1e-07 | 0.49 | 0.026 | 5.75e-08 | 0.000147 |
| 8 | TCF7L2 | transcription factor 7-like 2 (T-cell specific, HMG-box) | 119026 | 7 | 7 | 7 | 1 | 2 | 3 | 0 | 0 | 2 | 0 | 1e-07 | 0.085 | 0.11 | 2.21e-07 | 0.000495 |
| 9 | PIK3CA | phosphoinositide-3-kinase, catalytic, alpha polypeptide | 194975 | 7 | 7 | 7 | 1 | 1 | 3 | 3 | 0 | 0 | 0 | 2.1e-07 | 0.46 | 0.15 | 5.72e-07 | 0.00114 |
| 10 | OPCML | opioid binding protein/cell adhesion molecule-like | 73709 | 6 | 6 | 6 | 1 | 1 | 3 | 0 | 0 | 2 | 0 | 2.8e-07 | 0.51 | 0.68 | 3.17e-06 | 0.00567 |
| 11 | KRTAP5-5 | keratin associated protein 5-5 | 34487 | 2 | 2 | 1 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0.000021 | 0.0062 | 0.013 | 4.50e-06 | 0.00733 |
| 12 | SMAD2 | SMAD family member 2 | 98964 | 5 | 5 | 5 | 0 | 0 | 3 | 1 | 0 | 1 | 0 | 0.000022 | 0.37 | 0.02 | 6.84e-06 | 0.0102 |
| 13 | SPATA8 | spermatogenesis associated 8 | 20140 | 3 | 3 | 3 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 4.2e-06 | 0.51 | 0.16 | 1.03e-05 | 0.0142 |
| 14 | ERBB2 | v-erb-b2 erythroblastic leukemia viral oncogene homolog 2, neuro/glioblastoma derived oncogene homolog (avian) | 227547 | 4 | 4 | 2 | 1 | 4 | 0 | 0 | 0 | 0 | 0 | 0.024 | 0.031 | 0.00013 | 4.17e-05 | 0.0533 |
| 15 | IL1RAPL2 | interleukin 1 receptor accessory protein-like 2 | 139823 | 5 | 5 | 4 | 2 | 2 | 1 | 0 | 0 | 2 | 0 | 0.000022 | 1 | 0.17 | 4.90e-05 | 0.0586 |
| 16 | FAM123B | family with sequence similarity 123B | 190503 | 8 | 6 | 8 | 1 | 0 | 2 | 1 | 0 | 5 | 0 | 0.000081 | 0.71 | 0.14 | 0.000144 | 0.161 |
| 17 | ZIM3 | zinc finger, imprinted 3 | 98103 | 6 | 5 | 6 | 0 | 1 | 1 | 3 | 0 | 1 | 0 | 6e-05 | 0.12 | 0.25 | 0.000184 | 0.194 |
| 18 | PIK3R1 | phosphoinositide-3-kinase, regulatory subunit 1 (alpha) | 152490 | 5 | 4 | 5 | 0 | 2 | 0 | 0 | 0 | 1 | 2 | 0.00052 | 0.62 | 0.043 | 0.000260 | 0.259 |
| 19 | CSMD1 | CUB and Sushi multiple domains 1 | 392008 | 12 | 9 | 12 | 2 | 4 | 4 | 2 | 0 | 1 | 1 | 0.000024 | 0.75 | 1 | 0.000279 | 0.263 |
| 20 | SGCB | sarcoglycan, beta (43kDa dystrophin-associated glycoprotein) | 64145 | 4 | 4 | 4 | 0 | 0 | 3 | 0 | 0 | 0 | 1 | 0.000046 | 0.74 | 0.7 | 0.000366 | 0.328 |
| 21 | LRRTM2 | leucine rich repeat transmembrane neuronal 2 | 59242 | 5 | 4 | 5 | 1 | 1 | 1 | 2 | 1 | 0 | 0 | 0.000035 | 0.82 | 1 | 0.000397 | 0.333 |
| 22 | FAT4 | FAT tumor suppressor homolog 4 (Drosophila) | 968552 | 17 | 10 | 17 | 5 | 5 | 8 | 3 | 0 | 1 | 0 | 0.00043 | 0.56 | 0.086 | 0.000411 | 0.333 |
| 23 | GFRA1 | GDNF family receptor alpha 1 | 86296 | 5 | 5 | 5 | 1 | 1 | 0 | 3 | 0 | 1 | 0 | 0.000046 | 0.97 | 0.88 | 0.000452 | 0.333 |
| 24 | CCBP2 | chemokine binding protein 2 | 79700 | 5 | 5 | 5 | 0 | 1 | 2 | 2 | 0 | 0 | 0 | 5e-05 | 0.36 | 0.84 | 0.000468 | 0.333 |
| 25 | LIFR | leukemia inhibitory factor receptor alpha | 228178 | 5 | 5 | 5 | 2 | 0 | 2 | 1 | 1 | 1 | 0 | 0.00036 | 0.069 | 0.12 | 0.000492 | 0.333 |
| 26 | EPYC | epiphycan | 67872 | 4 | 3 | 4 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0.0006 | 0.49 | 0.075 | 0.000497 | 0.333 |
| 27 | OSBPL6 | oxysterol binding protein-like 6 | 208053 | 5 | 5 | 5 | 0 | 1 | 2 | 0 | 2 | 0 | 0 | 0.0003 | 0.078 | 0.16 | 0.000502 | 0.333 |
| 28 | FAM133A | family with sequence similarity 133, member A | 38160 | 2 | 2 | 2 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0.0012 | 0.034 | 0.041 | 0.000547 | 0.350 |
| 29 | CASP14 | caspase 14, apoptosis-related cysteine peptidase | 51900 | 5 | 4 | 4 | 0 | 4 | 1 | 0 | 0 | 0 | 0 | 0.00018 | 0.7 | 0.3 | 0.000599 | 0.370 |
| 30 | LPHN3 | latrophilin 3 | 147364 | 7 | 6 | 7 | 3 | 3 | 3 | 1 | 0 | 0 | 0 | 0.000059 | 0.45 | 1 | 0.000633 | 0.374 |
| 31 | MAP2K3 | mitogen-activated protein kinase kinase 3 | 67262 | 4 | 4 | 4 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 6e-05 | 0.65 | 1 | 0.000648 | 0.374 |
| 32 | PCDHA13 | protocadherin alpha 13 | 162857 | 8 | 6 | 8 | 0 | 3 | 1 | 2 | 1 | 1 | 0 | 0.000098 | 0.97 | 0.66 | 0.000689 | 0.385 |
| 33 | CSMD3 | CUB and Sushi multiple domains 3 | 787754 | 11 | 9 | 11 | 6 | 2 | 4 | 2 | 2 | 1 | 0 | 0.00014 | 0.23 | 0.52 | 0.000756 | 0.402 |
| 34 | ELF3 | E74-like factor 3 (ets domain transcription factor, epithelial-specific ) | 71547 | 3 | 3 | 3 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 0.00087 | 0.35 | 0.083 | 0.000764 | 0.402 |
| 35 | CTNNB1 | catenin (cadherin-associated protein), beta 1, 88kDa | 162026 | 4 | 4 | 4 | 0 | 1 | 2 | 1 | 0 | 0 | 0 | 0.00083 | 0.38 | 0.094 | 0.000812 | 0.407 |
In this analysis, COSMIC is used as a filter to increase power by restricting the territory of each gene. Cosmic version: v48.
Table 4. Get Full Table Significantly mutated genes (COSMIC territory only). To access the database please go to: COSMIC. Number of significant genes found: 10. Number of genes displayed: 10
| rank | gene | description | n | cos | n_cos | N_cos | cos_ev | p | q |
|---|---|---|---|---|---|---|---|---|---|
| 1 | KRAS | v-Ki-ras2 Kirsten rat sarcoma viral oncogene homolog | 38 | 52 | 37 | 3588 | 363199 | 1.6e-13 | 7.2e-10 |
| 2 | TP53 | tumor protein p53 | 45 | 824 | 45 | 56856 | 17987 | 1.6e-12 | 2.4e-09 |
| 3 | APC | adenomatous polyposis coli | 66 | 839 | 50 | 57891 | 1048 | 1.6e-12 | 2.4e-09 |
| 4 | NRAS | neuroblastoma RAS viral (v-ras) oncogene homolog | 5 | 33 | 5 | 2277 | 5755 | 3.1e-11 | 3.5e-08 |
| 5 | FBXW7 | F-box and WD repeat domain containing 7 | 12 | 91 | 6 | 6279 | 329 | 4.5e-11 | 4.1e-08 |
| 6 | SMAD4 | SMAD family member 4 | 8 | 159 | 6 | 10971 | 39 | 1.2e-09 | 9.2e-07 |
| 7 | KRTAP5-5 | keratin associated protein 5-5 | 2 | 1 | 2 | 69 | 2 | 1.9e-07 | 0.00012 |
| 8 | ERBB2 | v-erb-b2 erythroblastic leukemia viral oncogene homolog 2, neuro/glioblastoma derived oncogene homolog (avian) | 4 | 42 | 3 | 2898 | 6 | 3e-06 | 0.0017 |
| 9 | PIK3CA | phosphoinositide-3-kinase, catalytic, alpha polypeptide | 7 | 220 | 4 | 15180 | 1382 | 0.000013 | 0.0067 |
| 10 | LRP1B | low density lipoprotein-related protein 1B (deleted in tumors) | 20 | 18 | 2 | 1242 | 2 | 0.000063 | 0.028 |
Note:
n - number of (nonsilent) mutations in this gene across the individual set.
cos = number of unique mutated sites in this gene in COSMIC
n_cos = overlap between n and cos.
N_cos = number of individuals times cos.
cos_ev = total evidence: number of reports in COSMIC for mutations seen in this gene.
p = p-value for seeing the observed amount of overlap in this gene)
q = q-value, False Discovery Rate (Benjamini-Hochberg procedure)
Table 5. Get Full Table Genes with Clustered Mutations
| num | gene | desc | n | mindist | nmuts0 | nmuts3 | nmuts12 | npairs0 | npairs3 | npairs12 |
|---|---|---|---|---|---|---|---|---|---|---|
| 3873 | KRAS | v-Ki-ras2 Kirsten rat sarcoma viral oncogene homolog | 38 | 0 | 278 | 416 | 445 | 278 | 416 | 445 |
| 7548 | TP53 | tumor protein p53 | 45 | 0 | 37 | 61 | 105 | 37 | 61 | 105 |
| 392 | APC | adenomatous polyposis coli | 66 | 0 | 11 | 21 | 47 | 11 | 21 | 47 |
| 2614 | FBXW7 | F-box and WD repeat domain containing 7 | 12 | 0 | 6 | 6 | 6 | 6 | 6 | 6 |
| 4876 | NRAS | neuroblastoma RAS viral (v-ras) oncogene homolog | 5 | 0 | 6 | 6 | 6 | 6 | 6 | 6 |
| 6842 | SMAD4 | SMAD family member 4 | 8 | 0 | 4 | 4 | 6 | 4 | 4 | 6 |
| 2361 | ERBB2 | v-erb-b2 erythroblastic leukemia viral oncogene homolog 2, neuro/glioblastoma derived oncogene homolog (avian) | 4 | 0 | 3 | 3 | 3 | 3 | 3 | 3 |
| 3783 | KIAA1804 | 11 | 0 | 2 | 6 | 7 | 2 | 6 | 7 | |
| 3466 | IL1RAPL2 | interleukin 1 receptor accessory protein-like 2 | 5 | 0 | 1 | 3 | 3 | 1 | 3 | 3 |
| 2083 | DNAH5 | dynein, axonemal, heavy chain 5 | 19 | 0 | 1 | 2 | 2 | 1 | 2 | 2 |
Note:
n - number of mutations in this gene in the individual set.
mindist - distance (in aa) between closest pair of mutations in this gene
npairs3 - how many pairs of mutations are within 3 aa of each other.
npairs12 - how many pairs of mutations are within 12 aa of each other.
Table 6. Get Full Table A Ranked List of Significantly Mutated Genesets. (Source: MSigDB GSEA Cannonical Pathway Set).Number of significant genesets found: 111. Number of genesets displayed: 10
| rank | geneset | description | genes | N_genes | mut_tally | N | n | npat | nsite | nsil | n1 | n2 | n3 | n4 | n5 | n6 | p | q |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | WNT_SIGNALING | Wnt signaling genes | APC, ARHA, AXIN1, C2orf31, CCND1, CCND2, CCND3, CSNK1E, CSNK1E, LOC400927, CTNNB1, DIPA, DVL1, DVL2, DVL3, FBXW2, FOSL1, FRAT1, FZD1, FZD10, FZD2, FZD3, FZD5, FZD6, FZD7, FZD8, FZD9, GSK3B, JUN, LDLR, MAPK10, MAPK9, MYC, PAFAH1B1, PLAU, PPP2R5C, PPP2R5E, PRKCA, PRKCB1, PRKCD, PRKCE, PRKCG, PRKCH, PRKCI, PRKCM, PRKCQ, PRKCZ, PRKD1, RAC1, RHOA, SFRP4, TCF7, WNT1, WNT10A, WNT10B, WNT11, WNT16, WNT2, WNT2B, WNT3, WNT4, WNT5A, WNT5B, WNT6, WNT7A, WNT7B | 57 | APC(66), AXIN1(1), CTNNB1(4), DVL2(1), DVL3(2), FBXW2(1), FZD1(1), FZD10(2), FZD3(3), FZD6(3), GSK3B(1), LDLR(1), MAPK10(4), MAPK9(2), PLAU(1), PPP2R5C(1), PRKCA(2), PRKCE(2), PRKCG(2), PRKCH(1), PRKCQ(1), PRKD1(5), RHOA(1), SFRP4(1), TCF7(3), WNT10B(1), WNT2(1), WNT2B(2), WNT6(1) | 5514820 | 117 | 58 | 107 | 13 | 15 | 27 | 8 | 0 | 49 | 18 | <1.00e-15 | <8.25e-14 |
| 2 | TELPATHWAY | Telomerase is a ribonucleotide protein that adds telomeric repeats to the 3' ends of chromosomes. | AKT1, BCL2, EGFR, G22P1, HSPCA, IGF1R, KRAS2, MYC, POLR2A, PPP2CA, PRKCA, RB1, TEP1, TERF1, TERT, TNKS, TP53, XRCC5 | 15 | EGFR(1), IGF1R(1), PRKCA(2), RB1(3), TERF1(1), TP53(45), XRCC5(2) | 2767314 | 55 | 48 | 40 | 6 | 22 | 9 | 9 | 2 | 13 | 0 | <1.00e-15 | <8.25e-14 |
| 3 | HSA04810_REGULATION_OF_ACTIN_CYTOSKELETON | Genes involved in regulation of actin cytoskeleton | ABI2, ACTN1, ACTN2, ACTN3, ACTN4, APC, APC2, ARAF, ARHGEF1, ARHGEF12, ARHGEF4, ARHGEF6, ARHGEF7, ARPC1A, ARPC1B, ARPC2, ARPC3, ARPC4, ARPC5, ARPC5L, BAIAP2, BCAR1, BDKRB1, BDKRB2, BRAF, C3orf10, CD14, CDC42, CFL1, CFL2, CHRM1, CHRM2, CHRM3, CHRM4, CHRM5, CRK, CRKL, CSK, CYFIP1, CYFIP2, DIAPH1, DIAPH2, DIAPH3, DOCK1, EGF, EGFR, EZR, F2, F2R, FGD1, FGD3, FGF1, FGF10, FGF11, FGF12, FGF13, FGF14, FGF16, FGF17, FGF18, FGF19, FGF2, FGF20, FGF21, FGF22, FGF23, FGF3, FGF4, FGF5, FGF6, FGF7, FGF8, FGF9, FGFR1, FGFR2, FGFR3, FGFR4, FN1, GIT1, GNA12, GNA13, GNG12, GRLF1, GSN, HRAS, INS, IQGAP1, IQGAP2, IQGAP3, ITGA1, ITGA10, ITGA11, ITGA2, ITGA2B, ITGA3, ITGA4, ITGA5, ITGA6, ITGA7, ITGA8, ITGA9, ITGAD, ITGAE, ITGAL, ITGAM, ITGAV, ITGAX, ITGB1, ITGB2, ITGB3, ITGB4, ITGB5, ITGB6, ITGB7, ITGB8, KRAS, LIMK1, LIMK2, LOC200025, LOC645126, LOC653888, MAP2K1, MAP2K2, MAPK1, MAPK3, MLCK, MOS, MRAS, MRCL3, MRLC2, MSN, MYH10, MYH14, MYH9, MYL2, MYL5, MYL7, MYL8P, MYL9, MYLC2PL, MYLK, MYLK2, MYLPF, NCKAP1, NCKAP1L, NRAS, PAK1, PAK2, PAK3, PAK4, PAK6, PAK7, PDGFA, PDGFB, PDGFRA, PDGFRB, PFN1, PFN2, PFN3, PFN4, PIK3CA, PIK3CB, PIK3CD, PIK3CG, PIK3R1, PIK3R2, PIK3R3, PIK3R5, PIP4K2A, PIP4K2B, PIP4K2C, PIP5K1A, PIP5K1B, PIP5K1C, PIP5K3, PPP1CA, PPP1CB, PPP1CC, PPP1R12A, PPP1R12B, PTK2, PXN, RAC1, RAC2, RAC3, RAF1, RDX, RHOA, ROCK1, ROCK2, RRAS, RRAS2, SCIN, SLC9A1, SOS1, SOS2, SSH1, SSH2, SSH3, TIAM1, TIAM2, TMSB4X, TMSB4Y, TMSL3, VAV1, VAV2, VAV3, VCL, WAS, WASF1, WASF2, WASL | 203 | ABI2(1), ACTN1(2), ACTN2(1), ACTN3(1), ACTN4(1), APC(66), ARHGEF1(1), ARHGEF12(2), ARHGEF4(1), ARHGEF6(3), ARPC2(1), ARPC5L(1), BAIAP2(1), BDKRB2(1), BRAF(2), CDC42(1), CHRM2(3), CHRM4(1), CHRM5(1), CSK(2), CYFIP1(1), CYFIP2(1), DIAPH2(3), DIAPH3(2), DOCK1(2), EGFR(1), F2(1), FGD1(2), FGD3(1), FGF11(1), FGF12(1), FGF13(1), FGF19(1), FGF20(1), FGF5(2), FGFR1(1), FGFR2(5), FN1(4), GIT1(1), GRLF1(5), IQGAP1(3), IQGAP2(3), ITGA10(4), ITGA11(2), ITGA2(1), ITGA2B(2), ITGA4(5), ITGA6(1), ITGA8(3), ITGA9(2), ITGAD(1), ITGAE(2), ITGAL(3), ITGAM(3), ITGAV(4), ITGAX(2), ITGB2(1), ITGB3(2), ITGB4(1), ITGB5(1), ITGB8(1), KRAS(38), LIMK1(1), LIMK2(1), MAP2K1(1), MAP2K2(1), MAPK3(1), MOS(1), MSN(3), MYH10(2), MYH14(3), MYH9(3), MYL9(2), MYLK(3), MYLK2(1), NCKAP1(1), NCKAP1L(4), NRAS(5), PAK1(1), PAK2(1), PAK3(2), PAK7(3), PDGFRA(4), PDGFRB(1), PIK3CA(7), PIK3CD(1), PIK3CG(2), PIK3R1(5), PIK3R3(4), PIP5K1B(1), PIP5K1C(1), PPP1CB(1), PPP1CC(1), PPP1R12A(1), PPP1R12B(4), RAF1(2), RDX(1), RHOA(1), ROCK1(7), ROCK2(4), RRAS2(1), SCIN(1), SLC9A1(2), SOS1(2), SOS2(2), SSH1(2), SSH3(1), TIAM1(5), TIAM2(2), VAV1(2), VAV2(2), VAV3(2), VCL(1), WASF1(2), WASL(2) | 26346557 | 332 | 66 | 291 | 70 | 74 | 124 | 38 | 4 | 72 | 20 | 1.11e-15 | 8.25e-14 |
| 4 | ALKPATHWAY | Activin receptor-like kinase 3 (ALK3) is required during gestation for cardiac muscle development. | ACVR1, APC, ATF2, AXIN1, BMP10, BMP2, BMP4, BMP5, BMP7, BMPR1A, BMPR2, CHRD, CTNNB1, DVL1, FZD1, GATA4, GSK3B, MADH1, MADH4, MADH5, MADH6, MAP3K7, MEF2C, MYL2, NKX2-5, NOG, NPPA, NPPB, RFC1, TCF1, TGFB1, TGFB2, TGFB3, TGFBR1, TGFBR2, TGFBR3, WNT1 | 31 | ACVR1(1), APC(66), ATF2(1), AXIN1(1), BMP10(1), BMP2(1), BMP4(1), BMP5(1), BMP7(1), BMPR2(3), CTNNB1(4), FZD1(1), GSK3B(1), MAP3K7(2), MEF2C(2), NPPB(1), RFC1(4), TGFB2(4), TGFBR1(3), TGFBR3(3) | 3414527 | 102 | 59 | 92 | 3 | 13 | 19 | 9 | 0 | 43 | 18 | 1.11e-15 | 8.25e-14 |
| 5 | HSA04664_FC_EPSILON_RI_SIGNALING_PATHWAY | Genes involved in Fc epsilon RI signaling pathway | AKT1, AKT2, AKT3, BTK, CSF2, FCER1A, FCER1G, FYN, GAB2, GRB2, HRAS, IL13, IL3, IL4, IL5, INPP5D, KRAS, LAT, LCP2, LYN, MAP2K1, MAP2K2, MAP2K3, MAP2K4, MAP2K6, MAP2K7, MAPK1, MAPK10, MAPK11, MAPK12, MAPK13, MAPK14, MAPK3, MAPK8, MAPK9, MS4A2, NRAS, PDK1, PIK3CA, PIK3CB, PIK3CD, PIK3CG, PIK3R1, PIK3R2, PIK3R3, PIK3R5, PLA2G10, PLA2G12A, PLA2G12B, PLA2G1B, PLA2G2A, PLA2G2D, PLA2G2E, PLA2G2F, PLA2G3, PLA2G4A, PLA2G5, PLA2G6, PLCG1, PLCG2, PRKCA, PRKCB1, PRKCD, PRKCE, RAC1, RAC2, RAC3, RAF1, SOS1, SOS2, SYK, TNF, VAV1, VAV2, VAV3 | 74 | AKT2(1), AKT3(1), BTK(1), FCER1A(1), FYN(1), GRB2(1), INPP5D(2), KRAS(38), LAT(1), LCP2(1), MAP2K1(1), MAP2K2(1), MAP2K3(4), MAP2K4(2), MAP2K6(1), MAPK10(4), MAPK13(1), MAPK3(1), MAPK8(5), MAPK9(2), MS4A2(2), NRAS(5), PDK1(2), PIK3CA(7), PIK3CD(1), PIK3CG(2), PIK3R1(5), PIK3R3(4), PLA2G4A(3), PLA2G6(2), PLCG2(4), PRKCA(2), PRKCE(2), RAF1(2), SOS1(2), SOS2(2), SYK(3), VAV1(2), VAV2(2), VAV3(2) | 6895491 | 126 | 49 | 95 | 19 | 28 | 63 | 16 | 2 | 15 | 2 | 1.11e-15 | 8.25e-14 |
| 6 | ST_WNT_BETA_CATENIN_PATHWAY | Beta-catenin is degraded in the absence of Wnt signaling; when extracellular Wnt binds Frizzled receptors, beta-catenin accumulates in the nucleus and may promote cell survival. | AKT1, AKT2, AKT3, ANKRD6, APC, AXIN1, AXIN2, C22orf2, CER1, CSNK1A1, CTNNB1, DACT1, DKK1, DKK2, DKK3, DKK4, DVL1, FRAT1, FSTL1, GSK3A, GSK3B, IDAX, LAMR1, LRP1, MVP, NKD1, NKD2, PIN1, PSEN1, PTPRA, SENP2, SFRP1, TSHB, WIF1 | 29 | AKT2(1), AKT3(1), APC(66), AXIN1(1), AXIN2(2), CTNNB1(4), DACT1(1), DKK1(2), DKK2(1), DKK4(3), FSTL1(1), GSK3B(1), LRP1(3), SENP2(1), SFRP1(1), TSHB(1) | 3759900 | 90 | 59 | 80 | 4 | 8 | 14 | 11 | 0 | 39 | 18 | 1.33e-15 | 8.25e-14 |
| 7 | HSA04370_VEGF_SIGNALING_PATHWAY | Genes involved in VEGF signaling pathway | AKT1, AKT2, AKT3, BAD, CASP9, CDC42, CHP, HRAS, KDR, KRAS, MAP2K1, MAP2K2, MAPK1, MAPK11, MAPK12, MAPK13, MAPK14, MAPK3, MAPKAPK2, MAPKAPK3, NFAT5, NFATC1, NFATC2, NFATC3, NFATC4, NOS3, NRAS, PIK3CA, PIK3CB, PIK3CD, PIK3CG, PIK3R1, PIK3R2, PIK3R3, PIK3R5, PLA2G10, PLA2G12A, PLA2G12B, PLA2G1B, PLA2G2A, PLA2G2D, PLA2G2E, PLA2G2F, PLA2G3, PLA2G4A, PLA2G5, PLA2G6, PLCG1, PLCG2, PPP3CA, PPP3CB, PPP3CC, PPP3R1, PPP3R2, PRKCA, PRKCB1, PRKCG, PTGS2, PTK2, PXN, RAC1, RAC2, RAC3, RAF1, SH2D2A, SHC2, SPHK1, SPHK2, SRC, VEGFA | 69 | AKT2(1), AKT3(1), CDC42(1), KDR(2), KRAS(38), MAP2K1(1), MAP2K2(1), MAPK13(1), MAPK3(1), NFATC1(1), NFATC2(2), NFATC3(1), NFATC4(1), NRAS(5), PIK3CA(7), PIK3CD(1), PIK3CG(2), PIK3R1(5), PIK3R3(4), PLA2G4A(3), PLA2G6(2), PLCG2(4), PPP3CA(2), PPP3CB(1), PPP3CC(1), PRKCA(2), PRKCG(2), PTGS2(1), RAF1(2), SH2D2A(1), SHC2(1), SPHK1(1) | 6915053 | 99 | 50 | 68 | 19 | 27 | 50 | 10 | 0 | 10 | 2 | 1.44e-15 | 8.25e-14 |
| 8 | TIDPATHWAY | On ligand binding, interferon gamma receptors stimulate JAK2 kinase to phosphorylate STAT transcription factors, which promote expression of interferon responsive genes. | DNAJA3, HSPA1A, IFNG, IFNGR1, IFNGR2, IKBKB, JAK2, LIN7A, NFKB1, NFKBIA, RB1, RELA, TIP-1, TNF, TNFRSF1A, TNFRSF1B, TP53, USH1C, WT1 | 17 | DNAJA3(1), IFNGR1(1), IFNGR2(1), IKBKB(2), JAK2(3), NFKB1(3), RB1(3), TP53(45), USH1C(3), WT1(2) | 1809425 | 64 | 48 | 49 | 6 | 25 | 14 | 7 | 2 | 15 | 1 | 1.55e-15 | 8.25e-14 |
| 9 | TGFBPATHWAY | The TGF-beta receptor responds to ligand binding by activating the SMAD family of transcriptional regulations, commonly blocking cell growth. | APC, CDH1, CREBBP, EP300, MADH2, MADH3, MADH4, MADH7, MADHIP, MAP2K1, MAP3K7, MAP3K7IP1, MAPK3, SKIL, TGFB1, TGFB2, TGFB3, TGFBR1, TGFBR2 | 13 | APC(66), CDH1(1), CREBBP(4), EP300(2), MAP2K1(1), MAP3K7(2), MAPK3(1), SKIL(1), TGFB2(4), TGFBR1(3) | 2554178 | 85 | 57 | 75 | 4 | 5 | 10 | 8 | 0 | 44 | 18 | 1.78e-15 | 8.25e-14 |
| 10 | ST_FAS_SIGNALING_PATHWAY | The Fas receptor induces apoptosis and NF-kB activation when bound to Fas ligand. | ADPRT, ALG2, BAK1, BAX, BFAR, BIRC4, BTK, CAD, CASP10, CASP3, CASP8, CASP8AP2, CD7, CDK2AP1, CSNK1A1, DAXX, DEDD, DEDD2, DFFA, DIABLO, EGFR, EPHB2, FADD, FAF1, FAIM2, FREQ, HRB, HSPB1, IL1A, IL8, MAP2K4, MAP2K7, MAP3K1, MAP3K5, MAPK1, MAPK10, MAPK8, MAPK8IP1, MAPK8IP2, MAPK8IP3, MAPK9, MCP, MET, NFAT5, NFKB1, NFKB2, NFKBIA, NFKBIB, NFKBIE, NFKBIL1, NFKBIL2, NR0B2, PFN1, PFN2, PTPN13, RALBP1, RIPK1, ROCK1, SMPD1, TNFRSF6, TNFRSF6B, TP53, TPX2, TRAF2, TUFM, VIL2 | 59 | BTK(1), CAD(1), CASP3(1), CASP8AP2(6), DAXX(1), DEDD(1), DFFA(1), EGFR(1), EPHB2(1), IL8(1), MAP2K4(2), MAP3K1(2), MAP3K5(1), MAPK10(4), MAPK8(5), MAPK8IP3(1), MAPK9(2), MET(1), NFKB1(3), NFKB2(2), PTPN13(9), RALBP1(2), ROCK1(7), TP53(45), TPX2(1) | 6826271 | 102 | 50 | 87 | 17 | 34 | 28 | 17 | 3 | 20 | 0 | 2.00e-15 | 8.25e-14 |
Table 7. Get Full Table A Ranked List of Significantly Mutated Genesets (Excluding Significantly Mutated Genes). Number of significant genesets found: 0. Number of genesets displayed: 10
| rank | geneset | description | genes | N_genes | mut_tally | N | n | npat | nsite | nsil | n1 | n2 | n3 | n4 | n5 | n6 | p | q |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | C21_STEROID_HORMONE_METABOLISM | AKR1C4, AKR1D1, CYP11A1, CYP11B1, CYP11B2, CYP17A1, CYP21A2, HSD11B1, HSD11B2, HSD3B1, HSD3B2 | 11 | AKR1C4(1), AKR1D1(1), CYP11A1(2), CYP11B1(4), CYP21A2(1), HSD3B1(1), HSD3B2(1) | 837086 | 11 | 10 | 11 | 2 | 3 | 5 | 1 | 0 | 2 | 0 | 0.0014 | 0.3 | |
| 2 | HSA00140_C21_STEROID_HORMONE_METABOLISM | Genes involved in C21-steroid hormone metabolism | AKR1C4, AKR1D1, CYP11A1, CYP11B1, CYP11B2, CYP17A1, CYP21A2, HSD11B1, HSD11B2, HSD3B1, HSD3B2 | 11 | AKR1C4(1), AKR1D1(1), CYP11A1(2), CYP11B1(4), CYP21A2(1), HSD3B1(1), HSD3B2(1) | 837086 | 11 | 10 | 11 | 2 | 3 | 5 | 1 | 0 | 2 | 0 | 0.0014 | 0.3 |
| 3 | ERBB4PATHWAY | ErbB4 (aka HER4) is a receptor tyrosine kinase that binds neuregulins as well as members of the EGF family, which also target EGF receptors. | ADAM17, ERBB4, NRG2, NRG3, PRKCA, PRKCB1, PSEN1 | 6 | ADAM17(1), ERBB4(5), NRG2(2), NRG3(4), PRKCA(2) | 908762 | 14 | 9 | 14 | 1 | 4 | 5 | 1 | 1 | 3 | 0 | 0.0014 | 0.3 |
| 4 | HCMVPATHWAY | Cytomegalovirus activates MAP kinase pathways in the host cell, inducing transcription of viral genes. | AKT1, CREB1, MAP2K1, MAP2K2, MAP2K3, MAP2K6, MAP3K1, MAPK1, MAPK14, MAPK3, NFKB1, PIK3CA, PIK3R1, RB1, RELA, SP1 | 15 | MAP2K1(1), MAP2K2(1), MAP2K3(4), MAP2K6(1), MAP3K1(2), MAPK3(1), NFKB1(3), PIK3R1(5), RB1(3) | 1720824 | 21 | 10 | 21 | 3 | 7 | 4 | 4 | 1 | 3 | 2 | 0.004 | 0.54 |
| 5 | HSA00240_PYRIMIDINE_METABOLISM | Genes involved in pyrimidine metabolism | AICDA, AK3, CAD, CANT1, CDA, CMPK, CTPS, CTPS2, DCK, DCTD, DHODH, DPYD, DPYS, DTYMK, DUT, ECGF1, ENTPD1, ENTPD3, ENTPD4, ENTPD5, ENTPD6, ENTPD8, ITPA, NME1, NME2, NME4, NME6, NME7, NP, NT5C, NT5C1A, NT5C1B, NT5C2, NT5C3, NT5E, NT5M, NUDT2, PNPT1, POLA1, POLA2, POLD1, POLD2, POLD3, POLD4, POLE, POLE2, POLE3, POLE4, POLR1A, POLR1B, POLR1C, POLR1D, POLR2A, POLR2B, POLR2C, POLR2D, POLR2E, POLR2F, POLR2G, POLR2H, POLR2I, POLR2J, POLR2K, POLR2L, POLR3A, POLR3B, POLR3G, POLR3GL, POLR3H, POLR3K, PRIM1, PRIM2, RFC5, RRM1, RRM2, RRM2B, TK1, TK2, TXNRD1, TXNRD2, TYMS, UCK1, UCK2, UMPS, UPB1, UPP1, UPP2, UPRT, ZNRD1 | 86 | AICDA(1), CAD(1), CTPS(1), DCK(1), DHODH(1), DPYD(6), DPYS(1), DTYMK(1), ENTPD5(1), ENTPD6(1), NME6(1), NME7(2), NT5C1B(1), NT5C2(1), NT5E(1), PNPT1(5), POLA1(3), POLE(4), POLE2(1), POLR1A(3), POLR1B(2), POLR2B(3), POLR2K(1), POLR3A(4), POLR3B(5), POLR3K(1), PRIM2(3), RFC5(1), RRM1(1), TK2(1), TXNRD1(1), TXNRD2(1), TYMS(1), UMPS(1), UPB1(2), UPP2(1), UPRT(1) | 7933506 | 67 | 28 | 65 | 15 | 18 | 26 | 10 | 0 | 13 | 0 | 0.0046 | 0.54 |
| 6 | CREMPATHWAY | The transcription factor CREM activates a post-meiotic transcriptional cascade culminating in spermatogenesis. | ADCY1, CREM, FHL5, FSHB, FSHR, GNAS, XPO1 | 7 | ADCY1(4), FHL5(3), FSHB(1), FSHR(1), XPO1(1) | 917313 | 10 | 9 | 10 | 4 | 4 | 1 | 3 | 1 | 1 | 0 | 0.0053 | 0.54 |
| 7 | GSPATHWAY | Activated G-protein coupled receptors stimulate cAMP production and thus activate protein kinase A, involved in a number of signal transduction pathways. | ADCY1, GNAS, GNB1, GNGT1, PRKACA, PRKAR1A | 6 | ADCY1(4), GNGT1(1), PRKACA(1), PRKAR1A(4) | 607553 | 10 | 8 | 10 | 1 | 3 | 4 | 1 | 0 | 2 | 0 | 0.0071 | 0.62 |
| 8 | PAR1PATHWAY | Activated extracellular thrombin cleaves and activates the G-protein coupled receptors PAR1 and PAR4, which activate platelets. | ADCY1, ARHA, ARHGEF1, F2, F2R, F2RL3, GNA12, GNA13, GNAI1, GNAQ, GNB1, GNGT1, MAP3K7, PIK3CA, PIK3R1, PLCB1, PPP1R12B, PRKCA, PRKCB1, PTK2B, ROCK1 | 18 | ADCY1(4), ARHGEF1(1), F2(1), GNAI1(1), GNAQ(1), GNGT1(1), MAP3K7(2), PIK3R1(5), PPP1R12B(4), PRKCA(2), ROCK1(7) | 2322908 | 29 | 13 | 29 | 7 | 8 | 7 | 5 | 0 | 7 | 2 | 0.008 | 0.62 |
| 9 | NEUROTRANSMITTERSPATHWAY | Biosynthesis of neurotransmitters | DBH, GAD1, HDC, PNMT, TH, TPH1 | 6 | DBH(1), GAD1(2), HDC(5), TPH1(2) | 572489 | 10 | 7 | 10 | 2 | 3 | 5 | 1 | 0 | 1 | 0 | 0.01 | 0.69 |
| 10 | HSA00150_ANDROGEN_AND_ESTROGEN_METABOLISM | Genes involved in androgen and estrogen metabolism | AKR1C4, AKR1D1, ARSD, ARSE, CARM1, CYP11B1, CYP11B2, CYP19A1, HEMK1, HSD11B1, HSD11B2, HSD17B1, HSD17B12, HSD17B2, HSD17B3, HSD17B7, HSD17B8, HSD3B1, HSD3B2, LCMT1, LCMT2, METTL2B, METTL6, PRMT2, PRMT3, PRMT5, PRMT6, PRMT7, PRMT8, SRD5A1, SRD5A2, STS, SULT1E1, SULT2A1, SULT2B1, UGT1A1, UGT1A10, UGT1A3, UGT1A4, UGT1A5, UGT1A6, UGT1A7, UGT1A8, UGT1A9, UGT2A1, UGT2A3, UGT2B10, UGT2B11, UGT2B15, UGT2B17, UGT2B28, UGT2B4, UGT2B7, WBSCR22 | 53 | AKR1C4(1), AKR1D1(1), CYP11B1(4), CYP19A1(3), HSD17B2(1), HSD17B3(1), HSD3B1(1), HSD3B2(1), LCMT1(2), METTL2B(1), METTL6(3), PRMT3(1), PRMT7(1), PRMT8(2), SRD5A2(1), STS(1), SULT1E1(1), SULT2A1(1), UGT1A4(1), UGT1A6(1), UGT1A8(1), UGT1A9(1), UGT2A3(2), UGT2B11(2), UGT2B17(3), UGT2B28(1), UGT2B4(1), UGT2B7(2) | 4462401 | 42 | 18 | 42 | 9 | 9 | 19 | 6 | 1 | 7 | 0 | 0.012 | 0.7 |
In brief, we tabulate the number of mutations and the number of covered bases for each gene. The counts are broken down by mutation context category: four context categories that are discovered by MutSig, and one for indel and 'null' mutations, which include indels, nonsense mutations, splice-site mutations, and non-stop (read-through) mutations. For each gene, we calculate the probability of seeing the observed constellation of mutations, i.e. the product P1 x P2 x ... x Pm, or a more extreme one, given the background mutation rates calculated across the dataset. [1]
This is an experimental feature. The full results of the analysis summarized in this report can be downloaded from the TCGA Data Coordination Center.