This pipeline calculates clusters based on consensus hierarchical clustering with agglomerative average linkage[1],[2]. This pipeline has the following features:
-
Classify samples into consensus clusters.
-
Determine differentially expressed marker miRs for each subtype.
We filtered the data to 150 most variable miRs. Consensus average linkage hierarchical clustering of 411 samples and 150 miRs identified 3 subtypes with the stability of the clustering increasing for k = 2 to k = 8 and the average silhouette width calculation for selecting the robust clusters.
Figure 1. Silhouette width was calculated and the average silhouette width for all samples within one cluster was shown below according to different clusters (left panel). The robust cluster was pointed out by blue symbol (left panel) and the silhouette width of each sample in robust cluster was shown on right panel.
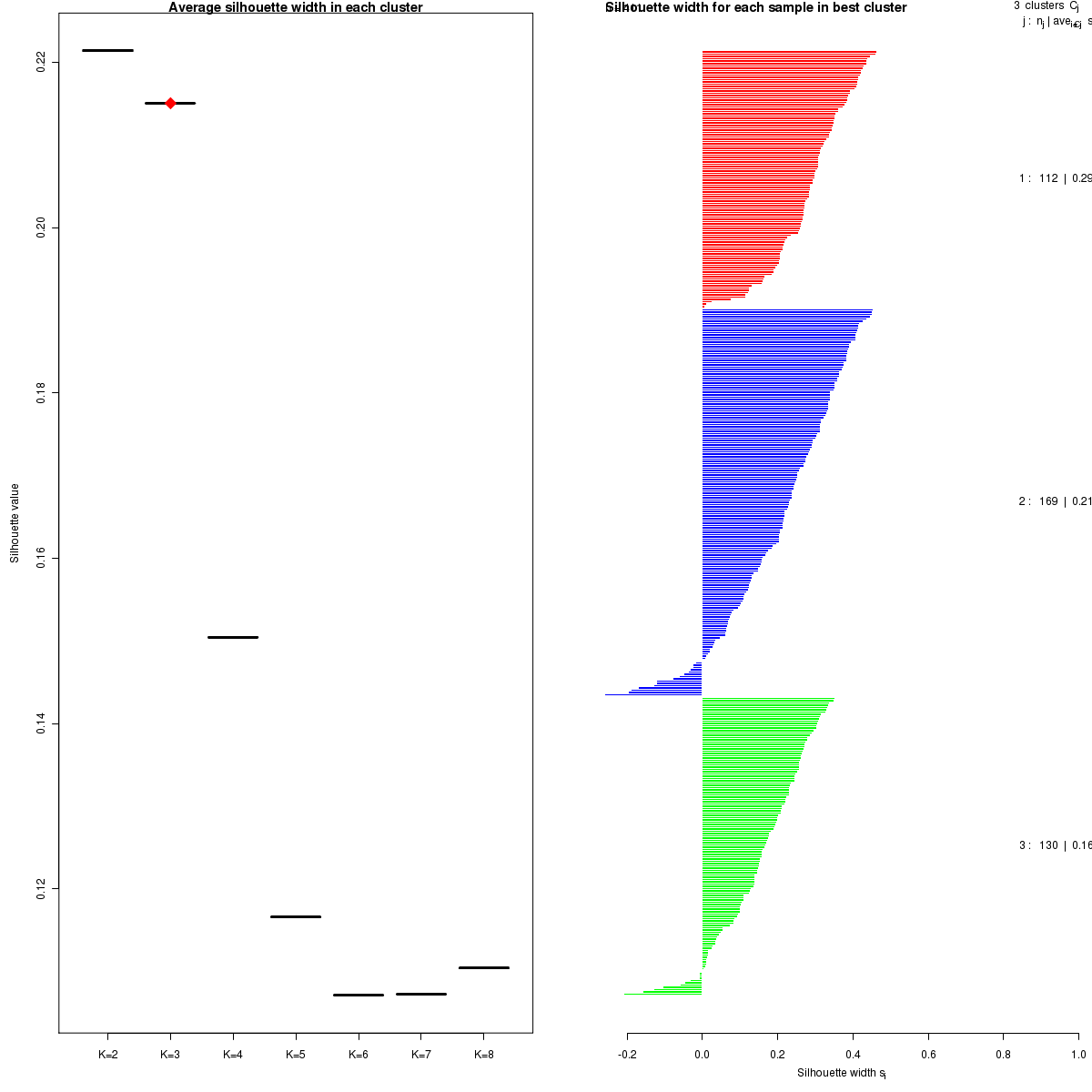
Figure 2. Tumours were separated into 3 clusters on the basis of miR expression with 411 samples and 843 marker miRs. The color bar of the row indicates the marker miRs for the corresponding cluster.
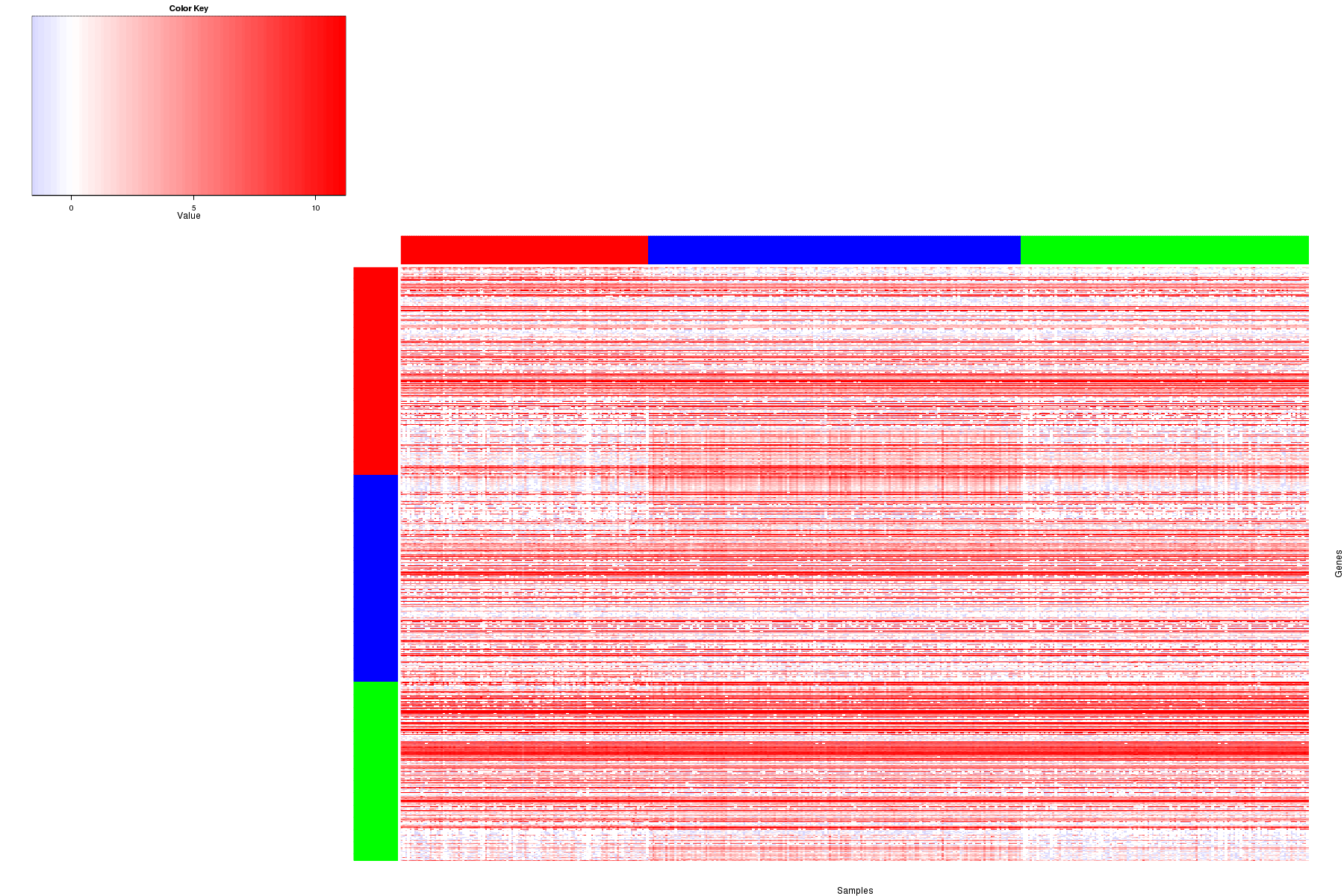
Figure 3. The miR expression heatmap with a standard hierarchical clustering for 411 samples and 150 most variable miRs.
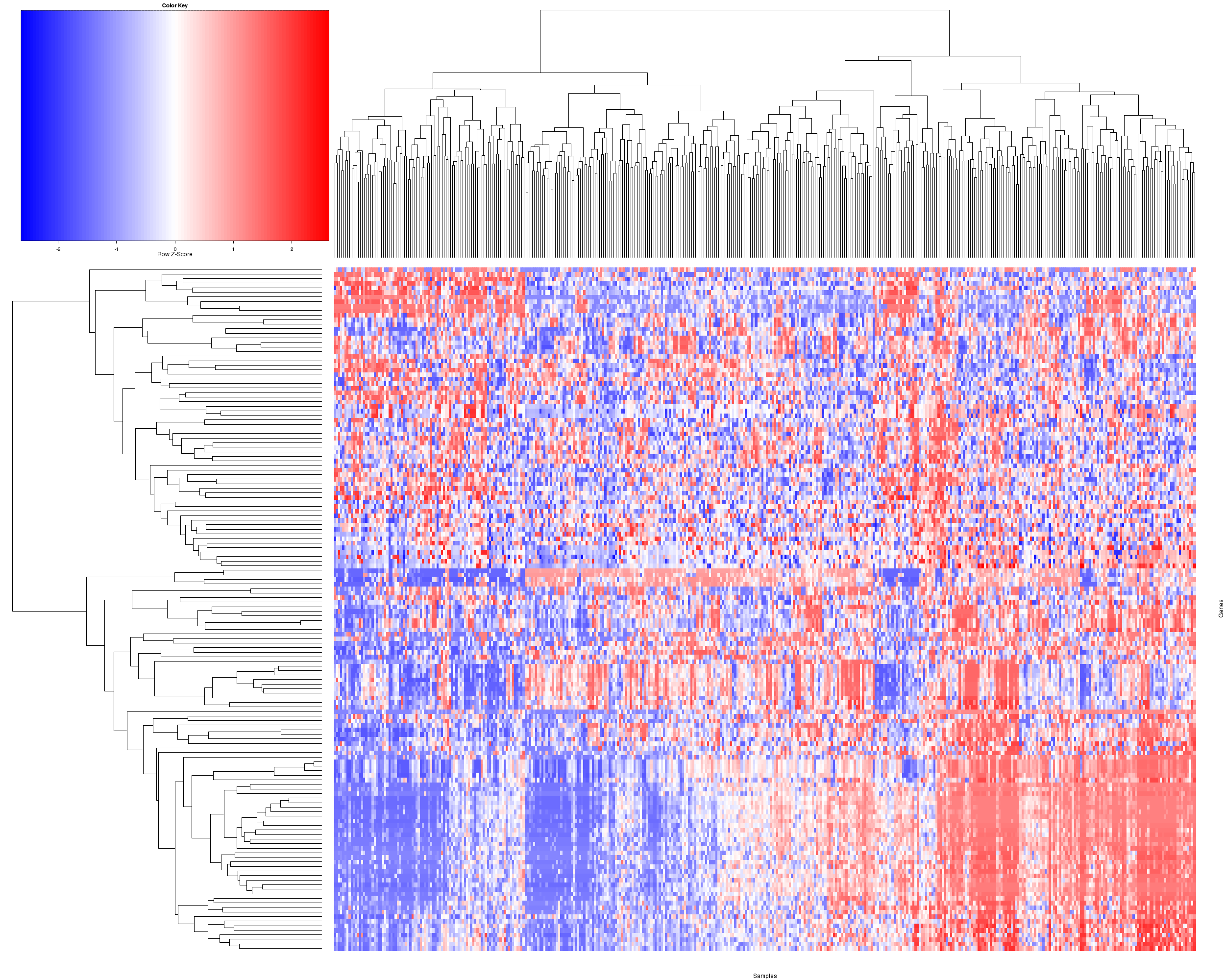
Figure 4. The consensus matrix after clustering shows 3 robust clusters with limited overlap between clusters.

Figure 5. The correlation matrix also shows 3 robust clusters.

Table 1. Get Full Table List of samples with 3 subtypes and silhouette width.
| SampleName | cluster | silhouetteValue |
|---|---|---|
| TCGA-BJ-A0YZ-01 | 1 | 0.31 |
| TCGA-BJ-A0Z0-01 | 1 | 0.21 |
| TCGA-BJ-A0Z2-01 | 1 | 0.27 |
| TCGA-BJ-A0ZA-01 | 1 | 0.16 |
| TCGA-BJ-A0ZC-01 | 1 | 0.41 |
| TCGA-BJ-A0ZE-01 | 1 | 0.21 |
| TCGA-BJ-A0ZF-01 | 1 | 0.38 |
| TCGA-BJ-A18Y-01 | 1 | 0.19 |
| TCGA-BJ-A190-01 | 1 | 0.36 |
| TCGA-BJ-A191-01 | 1 | 0.27 |
Table 2. Get Full Table List of samples belonging to each cluster in different k clusters.
| TCGA_ID | K.2 | K.3 | K.4 | K.5 | K.6 | K.7 | K.8 |
|---|---|---|---|---|---|---|---|
| TCGA-BJ-A0ZB-01 | 1 | 2 | 3 | 4 | 5 | 7 | 7 |
| TCGA-BJ-A0ZG-01 | 1 | 2 | 3 | 4 | 5 | 7 | 7 |
| TCGA-BJ-A18Z-01 | 1 | 2 | 3 | 4 | 5 | 7 | 7 |
| TCGA-BJ-A28T-01 | 1 | 2 | 3 | 4 | 5 | 7 | 7 |
| TCGA-BJ-A28W-01 | 1 | 2 | 3 | 4 | 5 | 7 | 7 |
| TCGA-BJ-A28X-01 | 1 | 2 | 3 | 4 | 5 | 7 | 7 |
| TCGA-BJ-A28Z-01 | 1 | 2 | 3 | 4 | 5 | 7 | 7 |
| TCGA-BJ-A291-01 | 1 | 2 | 3 | 4 | 5 | 7 | 7 |
| TCGA-BJ-A2NA-01 | 1 | 2 | 3 | 4 | 5 | 7 | 7 |
| TCGA-BJ-A3PR-01 | 1 | 2 | 3 | 4 | 5 | 7 | 7 |
Samples most representative of the clusters, hereby called core samples were identified based on positive silhouette width, indicating higher similarity to their own class than to any other class member. Core samples were used to select differentially expressed marker miRs for each subtype by comparing the subclass versus the other subclasses, using Student's t-test.
Table 3. Get Full Table List of marker miRs with p<= 0.05 (The positive value of column difference means miR is upregulated in this subtype and vice versa).
| Composite.Element.REF | p | difference | q | subclass |
|---|---|---|---|---|
| HSA-MIR-204 | 6.8e-42 | 3.6 | 1.1e-39 | 1 |
| HSA-MIR-7-2 | 6.8e-34 | 3.4 | 6.8e-32 | 1 |
| HSA-MIR-1179 | 5.5e-31 | 2.9 | 2.8e-29 | 1 |
| HSA-MIR-7-3 | 9.3e-18 | 2.6 | 8.7e-17 | 1 |
| HSA-MIR-873 | 9.8e-21 | 2.3 | 1.5e-19 | 1 |
| HSA-MIR-891B | 1.2e-07 | 2.2 | 3.6e-07 | 1 |
| HSA-MIR-892A | 1.6e-07 | 2.1 | 4.9e-07 | 1 |
| HSA-MIR-577 | 3e-24 | 2 | 6.9e-23 | 1 |
| HSA-MIR-301B | 1.7e-23 | 1.8 | 3.5e-22 | 1 |
| HSA-MIR-345 | 1.5e-25 | 1.8 | 4.6e-24 | 1 |
miRseq (at precursor level) of RPM value (reads per million reads aligned to miRBase precursor) with log2 transformed was as the input data for the clustering
Consensus Hierarchical clustering is a resampling-based clustering. It provides for a method to represent the consensus across multiple runs of a clustering algorithm and to assess the stability of the discovered clusters. To this end, perturbations of the original data are simulated by resampling techniques [1],[2].
Silhouette width is defined as the ratio of average distance of each sample to samples in the same cluster to the smallest distance to samples not in the same cluster. If silhouette width is close to 1, it means that sample is well clustered. If silhouette width is close to -1, it means that sample is misclassified [3][4].
This is an experimental feature. The full results of the analysis summarized in this report can be downloaded from the TCGA Data Coordination Center.