GISTIC identifies genomic regions that are significantly gained or lost across a set of tumors. The pipeline first filters out normal samples from the segmented copy-number data by inspecting the TCGA barcodes and then executes GISTIC version 2.0.21 (Firehose task version: 127).
There were 115 tumor samples used in this analysis: 16 significant arm-level results, 4 significant focal amplifications, and 16 significant focal deletions were found.
Figure 1. Genomic positions of amplified regions: the X-axis represents the normalized amplification signals (top) and significance by Q value (bottom). The green line represents the significance cutoff at Q value=0.25.
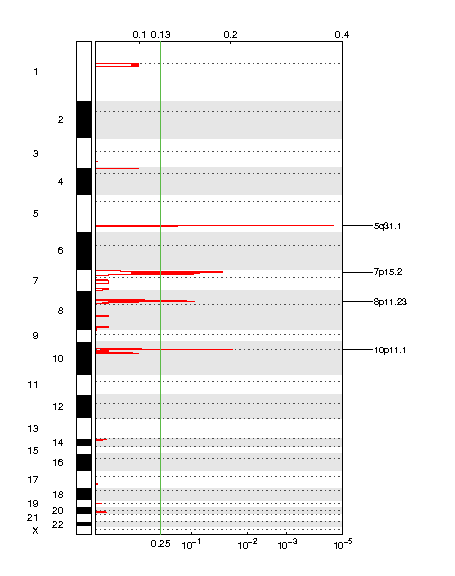
Table 1. Get Full Table Amplifications Table - 4 significant amplifications found. Click the link in the last column to view a comprehensive list of candidate genes. If no genes were identified within the peak, the nearest gene appears in brackets.
| Cytoband | Q value | Residual Q value | Wide Peak Boundaries | # Genes in Wide Peak |
|---|---|---|---|---|
| 5q31.1 | 2.4231e-05 | 2.4231e-05 | chr5:135102172-135142341 | 0 [SLC25A48] |
| 10p11.1 | 0.019986 | 0.019986 | chr10:38771600-38888819 | 0 [LOC399744] |
| 7p15.2 | 0.031008 | 0.031008 | chr7:23747603-33899458 | 91 |
| 8p11.23 | 0.090124 | 0.090124 | chr8:36722500-37773697 | 8 |
This is the comprehensive list of amplified genes in the wide peak for 7p15.2.
Table S1. Genes in bold are cancer genes as defined by The Sanger Institute: Cancer Gene Census[7].
| Genes |
|---|
| HNRNPA2B1 |
| HOXA9 |
| HOXA11 |
| HOXA13 |
| JAZF1 |
| hsa-mir-550-2 |
| hsa-mir-550-1 |
| hsa-mir-196b |
| hsa-mir-148a |
| ADCYAP1R1 |
| AQP1 |
| CHN2 |
| CRHR2 |
| DFNA5 |
| EVX1 |
| GARS |
| GHRHR |
| HOXA1 |
| HOXA2 |
| HOXA3 |
| HOXA4 |
| HOXA5 |
| HOXA6 |
| HOXA7 |
| HOXA10 |
| NPY |
| PDE1C |
| RP9 |
| TAX1BP1 |
| SKAP2 |
| CREB5 |
| NFE2L3 |
| SCRN1 |
| KIAA0087 |
| TRIL |
| NOD1 |
| PPP1R17 |
| HIBADH |
| INMT |
| FKBP9 |
| CBX3 |
| AVL9 |
| LSM5 |
| KBTBD2 |
| OSBPL3 |
| BBS9 |
| SNX10 |
| NT5C3 |
| MPP6 |
| CYCS |
| CPVL |
| FKBP14 |
| STK31 |
| NEUROD6 |
| NPVF |
| GGCT |
| FAM188B |
| PLEKHA8 |
| C7orf31 |
| HOXA11-AS1 |
| DKFZP586I1420 |
| C7orf41 |
| PRR15 |
| CCDC129 |
| ZNRF2 |
| C7orf71 |
| LOC401320 |
| LOC401321 |
| MIR148A |
| LOC441204 |
| ZNRF2P1 |
| RP9P |
| DPY19L2P3 |
| MIR196B |
| WIPF3 |
| LOC646762 |
| MIR550A1 |
| MIR550A2 |
| JAZF1-AS1 |
| DPY19L1P1 |
| LOC100130673 |
| LOC100133311 |
| ZNRF2P2 |
| HOTTIP |
| MIR550B2 |
| MIR550B1 |
| HOTAIRM1 |
| LOC100506497 |
| INMT-FAM188B |
| HOXA10-HOXA9 |
| MIR550A3 |
This is the comprehensive list of amplified genes in the wide peak for 8p11.23.
Table S2. Genes in bold are cancer genes as defined by The Sanger Institute: Cancer Gene Census[7].
| Genes |
|---|
| ERLIN2 |
| PROSC |
| GPR124 |
| BRF2 |
| ZNF703 |
| RAB11FIP1 |
| KCNU1 |
| LOC728024 |
Figure 2. Genomic positions of deleted regions: the X-axis represents the normalized deletion signals (top) and significance by Q value (bottom). The green line represents the significance cutoff at Q value=0.25.
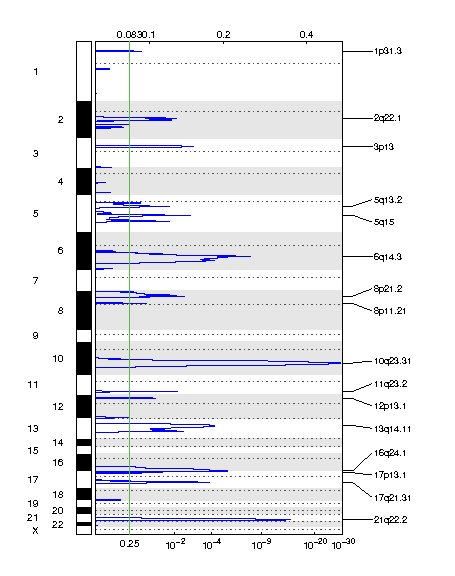
Table 2. Get Full Table Deletions Table - 16 significant deletions found. Click the link in the last column to view a comprehensive list of candidate genes. If no genes were identified within the peak, the nearest gene appears in brackets.
| Cytoband | Q value | Residual Q value | Wide Peak Boundaries | # Genes in Wide Peak |
|---|---|---|---|---|
| 10q23.31 | 1.1524e-29 | 1.1524e-29 | chr10:89605005-90036483 | 4 |
| 21q22.2 | 9.4171e-15 | 9.4171e-15 | chr21:39900175-42862782 | 26 |
| 6q14.3 | 2.5979e-08 | 2.5979e-08 | chr6:84879631-87907117 | 11 |
| 16q24.1 | 5.3598e-06 | 5.3598e-06 | chr16:78508930-90354753 | 122 |
| 13q14.11 | 6.0495e-05 | 6.0495e-05 | chr13:37403671-58065063 | 137 |
| 17q21.31 | 0.00014529 | 0.00014529 | chr17:41809000-42771669 | 30 |
| 3p13 | 0.0012346 | 0.0012346 | chr3:70330075-72954816 | 10 |
| 5q15 | 0.0019191 | 0.0019191 | chr5:96716255-100717422 | 8 |
| 11q23.2 | 0.0079663 | 0.0079663 | chr11:113676693-114556953 | 11 |
| 2q22.1 | 0.0083212 | 0.0083212 | chr2:136747893-149637131 | 19 |
| 8p21.2 | 0.0037559 | 0.008686 | chr8:9632689-27470746 | 146 |
| 5q13.2 | 0.017059 | 0.017059 | chr5:54459221-77689173 | 132 |
| 17p13.1 | 0.030995 | 0.030995 | chr17:6726127-7961035 | 81 |
| 12p13.1 | 0.049968 | 0.049968 | chr12:11587862-14028033 | 31 |
| 1p31.3 | 0.13253 | 0.13253 | chr1:63261852-67387711 | 28 |
| 8p11.21 | 0.096041 | 0.22375 | chr8:33955044-47636734 | 65 |
This is the comprehensive list of deleted genes in the wide peak for 10q23.31.
Table S3. Genes in bold are cancer genes as defined by The Sanger Institute: Cancer Gene Census[7].
| Genes |
|---|
| PTEN |
| RNLS |
| CFL1P1 |
| KLLN |
This is the comprehensive list of deleted genes in the wide peak for 21q22.2.
Table S4. Genes in bold are cancer genes as defined by The Sanger Institute: Cancer Gene Census[7].
| Genes |
|---|
| ERG |
| TMPRSS2 |
| hsa-mir-3197 |
| DSCAM |
| ETS2 |
| HMGN1 |
| MX1 |
| MX2 |
| PCP4 |
| SH3BGR |
| WRB |
| PSMG1 |
| B3GALT5 |
| BACE2 |
| BRWD1 |
| FAM3B |
| C21orf88 |
| LCA5L |
| IGSF5 |
| PLAC4 |
| BRWD1-IT2 |
| LINC00323 |
| LINC00114 |
| MIR3197 |
| DSCAM-AS1 |
| MIR4760 |
This is the comprehensive list of deleted genes in the wide peak for 6q14.3.
Table S5. Genes in bold are cancer genes as defined by The Sanger Institute: Cancer Gene Census[7].
| Genes |
|---|
| CGA |
| HTR1E |
| NT5E |
| TBX18 |
| SYNCRIP |
| KIAA1009 |
| ZNF292 |
| SNORD50A |
| SNX14 |
| SNHG5 |
| SNORD50B |
This is the comprehensive list of deleted genes in the wide peak for 16q24.1.
Table S6. Genes in bold are cancer genes as defined by The Sanger Institute: Cancer Gene Census[7].
| Genes |
|---|
| CBFA2T3 |
| FANCA |
| MAF |
| hsa-mir-1910 |
| hsa-mir-3182 |
| AFG3L1P |
| APRT |
| C16orf3 |
| CA5A |
| CDH13 |
| CDH15 |
| COX4I1 |
| CYBA |
| DPEP1 |
| FOXF1 |
| FOXL1 |
| FOXC2 |
| GALNS |
| GAS8 |
| GCSH |
| HSBP1 |
| HSD17B2 |
| IRF8 |
| MC1R |
| MVD |
| CHMP1A |
| PLCG2 |
| RPL13 |
| SPG7 |
| GAN |
| SLC7A5 |
| CDK10 |
| MBTPS1 |
| TAF1C |
| USP10 |
| C16orf7 |
| KIAA0513 |
| PIEZO1 |
| ATP2C2 |
| MPHOSPH6 |
| COX4NB |
| TUBB3 |
| PRDM7 |
| TCF25 |
| ZCCHC14 |
| KIAA0182 |
| ATMIN |
| COTL1 |
| MLYCD |
| CPNE7 |
| IL17C |
| ANKRD11 |
| OSGIN1 |
| GINS2 |
| TRAPPC2L |
| WWOX |
| BCMO1 |
| NECAB2 |
| KLHDC4 |
| DEF8 |
| BANP |
| ZDHHC7 |
| CENPN |
| C16orf61 |
| JPH3 |
| KIAA1609 |
| WFDC1 |
| MTHFSD |
| DBNDD1 |
| KLHL36 |
| FBXO31 |
| CMIP |
| CDT1 |
| MAP1LC3B |
| DYNLRB2 |
| HSDL1 |
| CRISPLD2 |
| SPIRE2 |
| ZNF469 |
| CENPBD1 |
| ZNF276 |
| KCNG4 |
| SDR42E1 |
| PKD1L2 |
| RNF166 |
| C16orf46 |
| DNAAF1 |
| SPATA2L |
| C16orf55 |
| ZC3H18 |
| CDYL2 |
| SLC38A8 |
| SLC22A31 |
| FLJ30679 |
| LOC146513 |
| ZFPM1 |
| ADAD2 |
| MGC23284 |
| LINC00311 |
| ZNF778 |
| ACSF3 |
| LINC00304 |
| SNAI3 |
| FAM92B |
| CTU2 |
| PABPN1L |
| LOC400548 |
| LOC400550 |
| LOC400558 |
| C16orf74 |
| SNORD68 |
| LOC727710 |
| LOC732275 |
| LOC100128881 |
| LOC100129617 |
| LOC100130015 |
| LOC100287036 |
| MIR1910 |
| MIR3182 |
| C16orf95 |
| MIR4720 |
| MIR4722 |
This is the comprehensive list of deleted genes in the wide peak for 13q14.11.
Table S7. Genes in bold are cancer genes as defined by The Sanger Institute: Cancer Gene Census[7].
| Genes |
|---|
| LCP1 |
| RB1 |
| LHFP |
| TTL |
| hsa-mir-1297 |
| hsa-mir-759 |
| hsa-mir-15a |
| hsa-mir-3168 |
| hsa-mir-621 |
| hsa-mir-4305 |
| ATP7B |
| RCBTB2 |
| CPB2 |
| ELF1 |
| ESD |
| FOXO1 |
| MLNR |
| GTF2F2 |
| GUCY1B2 |
| HTR2A |
| KPNA3 |
| SMAD9 |
| NEK3 |
| PCDH8 |
| RFXAP |
| TPT1 |
| TRPC4 |
| TNFSF11 |
| SUCLA2 |
| DLEU2 |
| TSC22D1 |
| ITM2B |
| MTRF1 |
| UTP14C |
| LPAR6 |
| SLC25A15 |
| TRIM13 |
| MRPS31 |
| DLEU1 |
| OLFM4 |
| POSTN |
| SUGT1 |
| LECT1 |
| WBP4 |
| AKAP11 |
| EXOSC8 |
| FNDC3A |
| KIAA0564 |
| ZC3H13 |
| LRCH1 |
| INTS6 |
| CKAP2 |
| NUFIP1 |
| C13orf15 |
| MED4 |
| DNAJC15 |
| ALG5 |
| VPS36 |
| PHF11 |
| UFM1 |
| ENOX1 |
| RCBTB1 |
| NUDT15 |
| KIAA1704 |
| FAM48A |
| THSD1 |
| CYSLTR2 |
| SPRYD7 |
| COG6 |
| NAA16 |
| RNASEH2B |
| DHRS12 |
| KIAA0226L |
| PROSER1 |
| CDADC1 |
| CAB39L |
| CCDC70 |
| COG3 |
| SETDB2 |
| KBTBD7 |
| EBPL |
| KBTBD6 |
| EPSTI1 |
| ARL11 |
| WDFY2 |
| LINC00284 |
| CSNK1A1L |
| PRR20A |
| FAM216B |
| LACC1 |
| LINC00330 |
| HNRNPA1L2 |
| ST13P4 |
| DGKH |
| CCDC122 |
| STOML3 |
| FAM194B |
| SPERT |
| DLEU7 |
| FAM124A |
| TPTE2P3 |
| CTAGE10P |
| SLC25A30 |
| SUGT1P3 |
| SIAH3 |
| KCNRG |
| LINC00282 |
| FREM2 |
| NEK5 |
| THSD1P1 |
| KCTD4 |
| NHLRC3 |
| SERP2 |
| LINC00547 |
| LINC00548 |
| MIR15A |
| MIR16-1 |
| ALG11 |
| TSC22D1-AS1 |
| SERPINE3 |
| SNORA31 |
| MIR621 |
| PRR20B |
| PRR20C |
| PRR20D |
| PRR20E |
| TPT1-AS1 |
| MIR1297 |
| MIR759 |
| MIR320D1 |
| MIR4305 |
| MIR3613 |
| OR7E37P |
| LOC100507240 |
| LOC100509894 |
| MIR4703 |
| LOC100616668 |
This is the comprehensive list of deleted genes in the wide peak for 17q21.31.
Table S8. Genes in bold are cancer genes as defined by The Sanger Institute: Cancer Gene Census[7].
| Genes |
|---|
| DUSP3 |
| FZD2 |
| GRN |
| ITGA2B |
| MPP2 |
| MPP3 |
| PPY |
| PYY |
| SLC4A1 |
| UBTF |
| HDAC5 |
| RUNDC3A |
| GPATCH8 |
| FAM215A |
| SOST |
| SLC25A39 |
| ATXN7L3 |
| C17orf53 |
| TMUB2 |
| TMEM101 |
| G6PC3 |
| ASB16 |
| LSM12 |
| CCDC43 |
| CD300LG |
| NAGS |
| C17orf105 |
| FAM171A2 |
| C17orf104 |
| C17orf65 |
This is the comprehensive list of deleted genes in the wide peak for 3p13.
Table S9. Genes in bold are cancer genes as defined by The Sanger Institute: Cancer Gene Census[7].
| Genes |
|---|
| FOXP1 |
| hsa-mir-1284 |
| GPR27 |
| RYBP |
| SHQ1 |
| PROK2 |
| LOC201617 |
| EIF4E3 |
| GXYLT2 |
| MIR1284 |
This is the comprehensive list of deleted genes in the wide peak for 5q15.
Table S10. Genes in bold are cancer genes as defined by The Sanger Institute: Cancer Gene Census[7].
| Genes |
|---|
| hsa-mir-548p |
| CHD1 |
| ST8SIA4 |
| RGMB |
| FAM174A |
| FLJ35946 |
| LOC100133050 |
| LOC100289230 |
This is the comprehensive list of deleted genes in the wide peak for 11q23.2.
Table S11. Genes in bold are cancer genes as defined by The Sanger Institute: Cancer Gene Census[7].
| Genes |
|---|
| HTR3A |
| NNMT |
| ZBTB16 |
| HTR3B |
| RBM7 |
| REXO2 |
| C11orf71 |
| FAM55D |
| USP28 |
| FAM55A |
| FAM55B |
This is the comprehensive list of deleted genes in the wide peak for 2q22.1.
Table S12. Genes in bold are cancer genes as defined by The Sanger Institute: Cancer Gene Census[7].
| Genes |
|---|
| ACVR2A |
| HNMT |
| KIF5C |
| ORC4 |
| CXCR4 |
| KYNU |
| ZEB2 |
| NXPH2 |
| EPC2 |
| LRP1B |
| MBD5 |
| ARHGAP15 |
| GTDC1 |
| THSD7B |
| SPOPL |
| DKFZp686O1327 |
| LOC647012 |
| PABPC1P2 |
| ZEB2-AS1 |
This is the comprehensive list of deleted genes in the wide peak for 8p21.2.
Table S13. Genes in bold are cancer genes as defined by The Sanger Institute: Cancer Gene Census[7].
| Genes |
|---|
| PCM1 |
| hsa-mir-548h-4 |
| hsa-mir-320a |
| hsa-mir-548v |
| hsa-mir-383 |
| hsa-mir-598 |
| hsa-mir-1322 |
| hsa-mir-4286 |
| hsa-mir-124-1 |
| NAT1 |
| NAT2 |
| ADRA1A |
| ASAH1 |
| ATP6V1B2 |
| BLK |
| BMP1 |
| POLR3D |
| BNIP3L |
| CHRNA2 |
| CLU |
| CTSB |
| DPYSL2 |
| EGR3 |
| EPB49 |
| EPHX2 |
| PTK2B |
| FDFT1 |
| FGL1 |
| GATA4 |
| GFRA2 |
| GNRH1 |
| LOXL2 |
| LPL |
| MSR1 |
| MSRA |
| NEFM |
| NEFL |
| NKX3-1 |
| PDGFRL |
| PPP2R2A |
| PPP3CC |
| SFTPC |
| SLC7A2 |
| SLC18A1 |
| STC1 |
| TUSC3 |
| TNKS |
| ADAM7 |
| TNFRSF10D |
| TNFRSF10C |
| TNFRSF10B |
| TNFRSF10A |
| FGF17 |
| DOK2 |
| MTMR7 |
| ENTPD4 |
| PHYHIP |
| SORBS3 |
| NPM2 |
| DLC1 |
| PNMA2 |
| ADAM28 |
| LZTS1 |
| XPO7 |
| TRIM35 |
| RHOBTB2 |
| PSD3 |
| SLC39A14 |
| FGF20 |
| ADAMDEC1 |
| CNOT7 |
| ZDHHC2 |
| SLC25A37 |
| KCTD9 |
| PINX1 |
| PIWIL2 |
| INTS10 |
| CSGALNACT1 |
| HR |
| BIN3 |
| MTUS1 |
| KIAA1456 |
| KIAA1967 |
| SH2D4A |
| PDLIM2 |
| EBF2 |
| FAM160B2 |
| MTMR9 |
| NUDT18 |
| DOCK5 |
| FLJ14107 |
| REEP4 |
| STMN4 |
| SOX7 |
| FAM167A |
| SLC35G5 |
| LINC00208 |
| C8orf12 |
| FAM86B1 |
| LONRF1 |
| CHMP7 |
| RP1L1 |
| VPS37A |
| NKX2-6 |
| SGCZ |
| PEBP4 |
| CDCA2 |
| LOC157627 |
| TDH |
| C8orf48 |
| R3HCC1 |
| PRSS55 |
| C8orf74 |
| LGI3 |
| DEFB109P1 |
| DEFB130 |
| NEIL2 |
| LOC254896 |
| XKR6 |
| LOC286059 |
| EFHA2 |
| LOC286114 |
| LOC340357 |
| USP17L2 |
| FAM90A25P |
| LOC389641 |
| LOC392196 |
| MIR124-1 |
| MIR320A |
| MIR383 |
| C8orf58 |
| DEFB135 |
| DEFB136 |
| DEFB134 |
| FAM86B2 |
| MIR598 |
| ZNF705D |
| LOC100128993 |
| FAM66D |
| FAM66A |
| LOC100133267 |
| MIR1322 |
| MIR3926-2 |
| MIR3926-1 |
| LOC100506990 |
| LOC100507156 |
This is the comprehensive list of deleted genes in the wide peak for 5q13.2.
Table S14. Genes in bold are cancer genes as defined by The Sanger Institute: Cancer Gene Census[7].
| Genes |
|---|
| IL6ST |
| PIK3R1 |
| hsa-mir-582 |
| hsa-mir-449c |
| TRIM23 |
| BTF3 |
| CCNB1 |
| CDK7 |
| ERCC8 |
| CRHBP |
| F2R |
| F2RL1 |
| F2RL2 |
| FOXD1 |
| GTF2H2 |
| HEXB |
| HMGCR |
| HTR1A |
| KIF2A |
| TNPO1 |
| CD180 |
| MAP1B |
| MAP3K1 |
| NAIP |
| PDE4D |
| PMCHL2 |
| RAD17 |
| SMN1 |
| SMN2 |
| TAF9 |
| TBCA |
| SERF1A |
| ENC1 |
| AP3B1 |
| PPAP2A |
| PDE8B |
| SCAMP1 |
| CARTPT |
| COL4A3BP |
| CWC27 |
| CCNO |
| NSA2 |
| PLK2 |
| IQGAP2 |
| SMA4 |
| SMA5 |
| ADAMTS6 |
| SV2C |
| MRPS27 |
| PPWD1 |
| OTP |
| SKIV2L2 |
| PART1 |
| FAM169A |
| DIMT1 |
| IPO11 |
| GCNT4 |
| POLK |
| DHX29 |
| DDX4 |
| SGTB |
| AGGF1 |
| WDR41 |
| DEPDC1B |
| BDP1 |
| ERBB2IP |
| NLN |
| ZSWIM6 |
| ANKRA2 |
| MCCC2 |
| CENPK |
| RGNEF |
| SLC30A5 |
| CENPH |
| GPBP1 |
| ANKRD55 |
| PTCD2 |
| ELOVL7 |
| C5orf44 |
| UTP15 |
| ZBED3 |
| GFM2 |
| NDUFAF2 |
| MRPS36 |
| FCHO2 |
| RAB3C |
| C5orf35 |
| IL31RA |
| TMEM171 |
| TMEM174 |
| POC5 |
| SREK1 |
| SLC38A9 |
| MARVELD2 |
| MIER3 |
| CDC20B |
| ZNF366 |
| S100Z |
| CCDC125 |
| GAPT |
| ANKRD31 |
| C5orf64 |
| RNF180 |
| SREK1IP1 |
| IDAS |
| ACTBL2 |
| MAST4 |
| RNF138P1 |
| RGS7BP |
| GPX8 |
| MIR449A |
| C5orf43 |
| LOC647859 |
| GUSBP3 |
| GTF2H2B |
| SNORA47 |
| MIR449B |
| GTF2H2C |
| SERF1B |
| LOC728723 |
| GTF2H2D |
| GUSBP9 |
| LRRC70 |
| FAM159B |
| LOC100170939 |
| LOC100272216 |
| NCRUPAR |
| LOC100303749 |
| MIR449C |
| OCLN |
| MIR4804 |
| MIR4803 |
This is the comprehensive list of deleted genes in the wide peak for 17p13.1.
Table S15. Genes in bold are cancer genes as defined by The Sanger Institute: Cancer Gene Census[7].
| Genes |
|---|
| TP53 |
| hsa-mir-324 |
| hsa-mir-497 |
| ACADVL |
| ALOX12 |
| ALOX12P2 |
| ALOX15B |
| ASGR1 |
| ASGR2 |
| ATP1B2 |
| CD68 |
| CHD3 |
| CHRNB1 |
| CLDN7 |
| DLG4 |
| DVL2 |
| EFNB3 |
| EIF4A1 |
| EIF5A |
| FGF11 |
| GPS2 |
| GUCY2D |
| POLR2A |
| SHBG |
| SLC2A4 |
| SOX15 |
| TNK1 |
| TNFSF13 |
| TNFSF12 |
| KCNAB3 |
| FXR2 |
| MPDU1 |
| ACAP1 |
| CLEC10A |
| GABARAP |
| KDM6B |
| CTDNEP1 |
| C17orf81 |
| SENP3 |
| SNORA67 |
| YBX2 |
| WRAP53 |
| PLSCR3 |
| NLGN2 |
| ZBTB4 |
| TRAPPC1 |
| PHF23 |
| TEKT1 |
| LSMD1 |
| NEURL4 |
| TMEM88 |
| SAT2 |
| CNTROB |
| RPL29P2 |
| CYB5D1 |
| C17orf49 |
| DNAH2 |
| KCTD11 |
| SLC16A11 |
| SLC16A13 |
| C17orf74 |
| C17orf61 |
| BCL6B |
| LOC284023 |
| TMEM102 |
| TMEM95 |
| SPEM1 |
| MIR195 |
| TNFSF12-TNFSF13 |
| RNASEK |
| MIR324 |
| MIR497 |
| SLC35G6 |
| SNORA48 |
| SNORD10 |
| SCARNA21 |
| LOC100506713 |
| MIR497HG |
| RNASEK-C17ORF49 |
| C17orf61-PLSCR3 |
| SENP3-EIF4A1 |
This is the comprehensive list of deleted genes in the wide peak for 12p13.1.
Table S16. Genes in bold are cancer genes as defined by The Sanger Institute: Cancer Gene Census[7].
| Genes |
|---|
| ETV6 |
| hsa-mir-614 |
| hsa-mir-613 |
| CDKN1B |
| CREBL2 |
| EMP1 |
| GPR19 |
| GRIN2B |
| LRP6 |
| GPRC5A |
| HEBP1 |
| DDX47 |
| MANSC1 |
| GPRC5D |
| KIAA1467 |
| BCL2L14 |
| DUSP16 |
| APOLD1 |
| GSG1 |
| HTR7P1 |
| LOH12CR1 |
| C12orf36 |
| LOC338817 |
| RPL13AP20 |
| LOH12CR2 |
| MIR613 |
| MIR614 |
| MIR1244-1 |
| MIR1244-3 |
| MIR1244-2 |
| LOC100506314 |
This is the comprehensive list of deleted genes in the wide peak for 1p31.3.
Table S17. Genes in bold are cancer genes as defined by The Sanger Institute: Cancer Gene Census[7].
| Genes |
|---|
| JAK1 |
| hsa-mir-3117 |
| hsa-mir-101-1 |
| AK4 |
| LEPR |
| ROR1 |
| PDE4B |
| PGM1 |
| DNAJC6 |
| INSL5 |
| ITGB3BP |
| FOXD3 |
| ALG6 |
| LEPROT |
| RAVER2 |
| CACHD1 |
| DLEU2L |
| WDR78 |
| SGIP1 |
| EFCAB7 |
| ATG4C |
| UBE2U |
| LINC00466 |
| TCTEX1D1 |
| MIR101-1 |
| MIR3117 |
| MIR3671 |
| MIR4794 |
This is the comprehensive list of deleted genes in the wide peak for 8p11.21.
Table S18. Genes in bold are cancer genes as defined by The Sanger Institute: Cancer Gene Census[7].
| Genes |
|---|
| FGFR1 |
| WHSC1L1 |
| HOOK3 |
| hsa-mir-486 |
| ADRB3 |
| ANK1 |
| CHRNB3 |
| ADAM3A |
| EIF4EBP1 |
| FNTA |
| ADAM2 |
| IKBKB |
| IDO1 |
| PLAT |
| POLB |
| SFRP1 |
| SLC20A2 |
| STAR |
| TACC1 |
| VDAC3 |
| KAT6A |
| ADAM18 |
| ADAM9 |
| CHRNA6 |
| ASH2L |
| BAG4 |
| AP3M2 |
| ERLIN2 |
| PROSC |
| DDHD2 |
| GPR124 |
| DKK4 |
| LSM1 |
| GOLGA7 |
| THAP1 |
| BRF2 |
| C8orf4 |
| PLEKHA2 |
| ZMAT4 |
| ZNF703 |
| RAB11FIP1 |
| RNF170 |
| TM2D2 |
| SGK196 |
| GINS4 |
| PPAPDC1B |
| C8orf40 |
| GOT1L1 |
| AGPAT6 |
| UNC5D |
| LETM2 |
| HGSNAT |
| NKX6-3 |
| KCNU1 |
| IDO2 |
| HTRA4 |
| ADAM32 |
| ADAM5P |
| RNF5P1 |
| POTEA |
| C8orf86 |
| MIR486 |
| LOC728024 |
| LOC100130964 |
| MIR4469 |
Table 3. Get Full Table Arm-level significance table - 16 significant results found. The significance cutoff is at Q value=0.25.
| Arm | # Genes | Amp Frequency | Amp Z score | Amp Q value | Del Frequency | Del Z score | Del Q value |
|---|---|---|---|---|---|---|---|
| 1p | 2121 | 0.02 | 1.21 | 0.568 | 0.02 | 1.21 | 0.35 |
| 1q | 1955 | 0.03 | 2.6 | 0.0466 | 0.00 | -1.07 | 0.954 |
| 2p | 924 | 0.00 | -1.75 | 0.981 | 0.01 | -1.17 | 0.954 |
| 2q | 1556 | 0.00 | -1.36 | 0.981 | 0.03 | 1.55 | 0.222 |
| 3p | 1062 | 0.04 | 1.38 | 0.482 | 0.01 | -1.02 | 0.954 |
| 3q | 1139 | 0.08 | 3.97 | 0.00142 | 0.00 | -1.58 | 0.954 |
| 4p | 489 | 0.00 | -1.96 | 0.981 | 0.02 | -0.932 | 0.954 |
| 4q | 1049 | 0.01 | -1.08 | 0.981 | 0.00 | -1.68 | 0.954 |
| 5p | 270 | 0.00 | -2.07 | 0.981 | 0.01 | -1.58 | 0.954 |
| 5q | 1427 | 0.00 | -1.46 | 0.981 | 0.01 | -0.776 | 0.954 |
| 6p | 1173 | 0.00 | -1.61 | 0.981 | 0.02 | -0.359 | 0.954 |
| 6q | 839 | 0.00 | -1.73 | 0.981 | 0.08 | 3.33 | 0.00174 |
| 7p | 641 | 0.07 | 2.46 | 0.0557 | 0.01 | -1.27 | 0.954 |
| 7q | 1277 | 0.07 | 3.67 | 0.0016 | 0.00 | -1.51 | 0.954 |
| 8p | 580 | 0.01 | -0.87 | 0.981 | 0.37 | 20.6 | 0 |
| 8q | 859 | 0.09 | 3.72 | 0.0016 | 0.10 | 4.85 | 4.13e-06 |
| 9p | 422 | 0.01 | -1.46 | 0.981 | 0.03 | -0.448 | 0.954 |
| 9q | 1113 | 0.03 | 0.2 | 0.981 | 0.00 | -1.63 | 0.954 |
| 10p | 409 | 0.00 | -1.97 | 0.981 | 0.04 | 0.553 | 0.725 |
| 10q | 1268 | 0.01 | -0.824 | 0.981 | 0.08 | 4.34 | 3.63e-05 |
| 11p | 862 | 0.01 | -1.21 | 0.981 | 0.01 | -1.21 | 0.954 |
| 11q | 1515 | 0.01 | -0.656 | 0.981 | 0.04 | 1.48 | 0.23 |
| 12p | 575 | 0.02 | -0.69 | 0.981 | 0.12 | 5.08 | 1.54e-06 |
| 12q | 1447 | 0.04 | 1.38 | 0.482 | 0.02 | -0.00844 | 0.954 |
| 13q | 654 | 0.01 | -1.22 | 0.981 | 0.11 | 4.66 | 8.87e-06 |
| 14q | 1341 | 0.00 | -1.51 | 0.981 | 0.02 | -0.182 | 0.954 |
| 15q | 1355 | 0.01 | -0.821 | 0.981 | 0.02 | -0.154 | 0.954 |
| 16p | 872 | 0.02 | -0.622 | 0.981 | 0.01 | -1.19 | 0.954 |
| 16q | 702 | 0.01 | -1.16 | 0.981 | 0.13 | 6.42 | 6.62e-10 |
| 17p | 683 | 0.00 | -1.75 | 0.981 | 0.14 | 6.88 | 4.02e-11 |
| 17q | 1592 | 0.00 | -1.36 | 0.981 | 0.01 | -0.617 | 0.954 |
| 18p | 143 | 0.00 | -2.02 | 0.981 | 0.10 | 3.7 | 0.00048 |
| 18q | 446 | 0.00 | -1.83 | 0.981 | 0.16 | 7.32 | 2.4e-12 |
| 19p | 995 | 0.00 | -1.69 | 0.981 | 0.03 | 0.665 | 0.723 |
| 19q | 1709 | 0.00 | -1.27 | 0.981 | 0.02 | 0.3 | 0.899 |
| 20p | 355 | 0.01 | -1.49 | 0.981 | 0.04 | 0.00824 | 0.954 |
| 20q | 753 | 0.04 | 0.436 | 0.981 | 0.03 | -0.113 | 0.954 |
| 21q | 509 | 0.01 | -1.41 | 0.981 | 0.03 | -0.376 | 0.954 |
| 22q | 921 | 0.00 | -1.73 | 0.981 | 0.03 | 0.574 | 0.725 |
| Xq | 1312 | 0.01 | -0.877 | 0.981 | 0.00 | -1.53 | 0.954 |
-
Segmentation File: The segmentation file contains the segmented data for all the samples identified by GLAD, CBS, or some other segmentation algorithm. (See GLAD file format in the Genepattern file formats documentation.) It is a six column, tab-delimited file with an optional first line identifying the columns. Positions are in base pair units.The column headers are: (1) Sample (sample name), (2) Chromosome (chromosome number), (3) Start Position (segment start position, in bases), (4) End Position (segment end position, in bases), (5) Num markers (number of markers in segment), (6) Seg.CN (log2() -1 of copy number).
-
Markers File: The markers file identifies the marker names and positions of the markers in the original dataset (before segmentation). It is a three column, tab-delimited file with an optional header. The column headers are: (1) Marker Name, (2) Chromosome, (3) Marker Position (in bases).
-
Reference Genome: The reference genome file contains information about the location of genes and cytobands on a given build of the genome. Reference genome files are created in Matlab and are not viewable with a text editor.
-
CNV Files: There are two options for the cnv file. The first option allows CNVs to be identified by marker name. The second option allows the CNVs to be identified by genomic location. Option #1: A two column, tab-delimited file with an optional header row. The marker names given in this file must match the marker names given in the markers file. The CNV identifiers are for user use and can be arbitrary. The column headers are: (1) Marker Name, (2) CNV Identifier. Option #2: A 6 column, tab-delimited file with an optional header row. The 'CNV Identifier' is for user use and can be arbitrary. 'Narrow Region Start' and 'Narrow Region End' are also not used. The column headers are: (1) CNV Identifier, (2) Chromosome, (3) Narrow Region Start, (4) Narrow Region End, (5) Wide Region Start, (6) Wide Region End
-
Amplification Threshold: Threshold for copy number amplifications. Regions with a log2 ratio above this value are considered amplified.
-
Deletion Threshold: Threshold for copy number deletions. Regions with a log2 ratio below the negative of this value are considered deletions.
-
Cap Values: Minimum and maximum cap values on analyzed data. Regions with a log2 ratio greater than the cap are set to the cap value; regions with a log2 ratio less than -cap value are set to -cap. Values must be positive.
-
Broad Length Cutoff: Threshold used to distinguish broad from focal events, given in units of fraction of chromosome arm.
-
Remove X-Chromosome: Flag indicating whether to remove data from the X-chromosome before analysis. Allowed values= {1,0} (1: Remove X-Chromosome, 0: Do not remove X-Chromosome.
-
Confidence Level: Confidence level used to calculate the region containing a driver.
-
Join Segment Size: Smallest number of markers to allow in segments from the segmented data. Segments that contain fewer than this number of markers are joined to the neighboring segment that is closest in copy number.
-
Arm Level Peel Off: Flag set to enable arm-level peel-off of events during peak definition. The arm-level peel-off enhancement to the arbitrated peel-off method assigns all events in the same chromosome arm of the same sample to a single peak. It is useful when peaks are split by noise or chromothripsis. Allowed values= {1,0} (1: Use arm level peel off, 0: Use normal arbitrated peel-off).
-
Maximum Sample Segments: Maximum number of segments allowed for a sample in the input data. Samples with more segments than this threshold are excluded from the analysis.
-
Gene GISTIC: When enabled (value = 1), this option causes GISTIC to analyze deletions using genes instead of array markers to locate the lesion. In this mode, the copy number assigned to a gene is the lowest copy number among the markers that represent the gene.
List of inputs used for this run of GISTIC2. All files listed should be included in the archived results.
-
Segmentation File = /xchip/cga/gdac-prod/tcga-gdac/jobResults/PrepareGisticDNASeq/PRAD-TP/8143207/segmentationfile.txt
-
Markers File = /xchip/cga/gdac-prod/tcga-gdac/jobResults/PrepareGisticDNASeq/PRAD-TP/8143207/markersfile.txt
-
Reference Genome = /xchip/cga/reference/gistic2/hg19_with_miR_20120227.mat
-
CNV Files = /xchip/cga/reference/gistic2/CNV.hg19.bypos.111213.txt
-
Amplification Threshold = 0.3
-
Deletion Threshold = 0.3
-
Cap Values = 2
-
Broad Length Cutoff = 0.5
-
Remove X-Chromosome = 0
-
Confidence Level = 0.99
-
Join Segment Size = 10
-
Arm Level Peel Off = 1
-
Maximum Sample Segments = 10000
-
Gene GISTIC = 0
Table 4. Get Full Table First 10 out of 115 Input Tumor Samples.
| Tumor Sample Names |
|---|
| TCGA-CH-5741-01A-11D-1572-02 |
| TCGA-CH-5743-01A-21D-1572-02 |
| TCGA-CH-5744-01A-11D-1572-02 |
| TCGA-CH-5745-01A-11D-1572-02 |
| TCGA-CH-5746-01A-11D-1572-02 |
| TCGA-CH-5748-01A-11D-1572-02 |
| TCGA-CH-5750-01A-11D-1572-02 |
| TCGA-CH-5751-01A-11D-1572-02 |
| TCGA-CH-5752-01A-11D-1572-02 |
| TCGA-CH-5754-01A-11D-1572-02 |
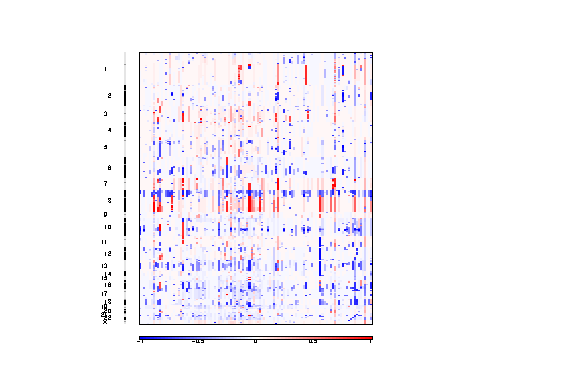
Figure 3. Segmented copy number profiles in the input data
The all lesions file summarizes the results from the GISTIC run. It contains data about the significant regions of amplification and deletion as well as which samples are amplified or deleted in each of these regions. The identified regions are listed down the first column, and the samples are listed across the first row, starting in column 10.
Region Data
Columns 1-9 present the data about the significant regions as follows:
-
Unique Name: A name assigned to identify the region.
-
Descriptor: The genomic descriptor of that region.
-
Wide Peak Limits: The 'wide peak' boundaries most likely to contain the targeted genes. These are listed in genomic coordinates and marker (or probe) indices.
-
Peak Limits: The boundaries of the region of maximal amplification or deletion.
-
Region Limits: The boundaries of the entire significant region of amplification or deletion.
-
Q values: The Q value of the peak region.
-
Residual Q values: The Q value of the peak region after removing ('peeling off') amplifications or deletions that overlap other, more significant peak regions in the same chromosome.
-
Broad or Focal: Identifies whether the region reaches significance due primarily to broad events (called 'broad'), focal events (called 'focal'), or independently significant broad and focal events (called 'both').
-
Amplitude Threshold: Key giving the meaning of values in the subsequent columns associated with each sample.
Sample Data
Each of the analyzed samples is represented in one of the columns following the lesion data (columns 10 through end). The data contained in these columns varies slightly by section of the file. The first section can be identified by the key given in column 9 - it starts in row 2 and continues until the row that reads 'Actual Copy Change Given.' This section contains summarized data for each sample. A '0' indicates that the copy number of the sample was not amplified or deleted beyond the threshold amount in that peak region. A '1' indicates that the sample had low-level copy number aberrations (exceeding the low threshold indicated in column 9), and a '2' indicates that the sample had high-level copy number aberrations (exceeding the high threshold indicated in column 9).The second section can be identified the rows in which column 9 reads 'Actual Copy Change Given.' The second section exactly reproduces the first section, except that here the actual changes in copy number are provided rather than zeroes, ones, and twos.The final section is similar to the first section, except that here only broad events are included. A 1 in the samples columns (columns 10+) indicates that the median copy number of the sample across the entire significant region exceeded the threshold given in column 9. That is, it indicates whether the sample had a geographically extended event, rather than a focal amplification or deletion covering little more than the peak region.
The amp genes file contains one column for each amplification peak identified in the GISTIC analysis. The first four rows are:
-
Cytoband
-
Q value
-
Residual Q value
-
Wide Peak Boundaries
These rows identify the lesion in the same way as the all lesions file.The remaining rows list the genes contained in each wide peak. For peaks that contain no genes, the nearest gene is listed in brackets.
The del genes file contains one column for each deletion peak identified in the GISTIC analysis. The file format for the del genes file is identical to the format for the amp genes file.
The scores file lists the Q values [presented as -log10(q)], G scores, average amplitudes among aberrant samples, and frequency of aberration, across the genome for both amplifications and deletions. The scores file is viewable with the Genepattern SNPViewer module and may be imported into the Integrated Genomics Viewer (IGV).
The segmented copy number is a pdf file containing a colormap image of the segmented copy number profiles in the input data.
The amplification pdf is a plot of the G scores (top) and Q values (bottom) with respect to amplifications for all markers over the entire region analyzed.
The deletion pdf is a plot of the G scores (top) and Q values (bottom) with respect to deletions for all markers over the entire region analyzed.
Tables of basic information about the genomic regions (peaks) that GISTIC determined to be significantly amplified or deleted. These describe three kinds of peak boundaries, and list the genes contained in two of them. The region start and region end columns (along with the chromosome column) delimit the entire area containing the peak that is above the significance level. The region may be the same for multiple peaks. The peak start and end delimit the maximum value of the peak. The extended peak is the peak determined by robust, and is contained within the wide peak reported in {amp|del}_genes.txt by one marker.
A table of per-arm statistical results for the data set. Each arm is a row in the table. The first column specifies the arm and the second column counts the number of genes known to be on the arm. For both amplification and deletion, the table has columns for the frequency of amplification or deletion of the arm, and a Z score and Q value.
A table of chromosome arm amplification levels for each sample. Each row is a chromosome arm, and each column a sample. The data are in units of absolute copy number -2.
A gene-level table of copy number values for all samples. Each row is the data for a gene. The first three columns name the gene, its NIH locus ID, and its cytoband - the remaining columns are the samples. The copy number values in the table are in units of (copy number -2), so that no amplification or deletion is 0, genes with amplifications have positive values, and genes with deletions are negative values. The data are converted from marker level to gene level using the extreme method: a gene is assigned the greatest amplification or the least deletion value among the markers it covers.
A gene-level table of copy number data similar to the all_data_by_genes.txt output, but using only broad events with lengths greater than the broad length cutoff. The structure of the file and the methods and units used for the data analysis are otherwise identical to all_data_by_genes.txt.
A gene-level table of copy number data similar to the all_data_by_genes.txt output, but using only focal events with lengths greater than the focal length cutoff. The structure of the file and the methods and units used for the data analysis are otherwise identical to all_data_by_genes.txt.
A gene-level table of discrete amplification and deletion indicators at for all samples. There is a row for each gene. The first three columns name the gene, its NIH locus ID, and its cytoband - the remaining columns are the samples. A table value of 0 means no amplification or deletion above the threshold. Amplifications are positive numbers: 1 means amplification above the amplification threshold; 2 means amplifications larger to the arm level amplifications observed for the sample. Deletions are represented by negative table values: -1 represents deletion beyond the threshold; -2 means deletions greater than the minimum arm-level deletion observed for the sample.
A table of the per-sample threshold cutoffs (in units of absolute copy number -2) used to distinguish the high level amplifications (+/-2) from ordinary amplifications (+/-1) in the all_thresholded.by_genes.txt output file. The table contains three columns: the sample identifier followed by the low (deletion) and high (amplification) cutoff values. The cutoffs are calculated as the minimum arm-level amplification level less the deletion threshold for deletions and the maximum arm-level amplification plus the amplification threshold for amplifications.
A list of copy number segments describing just the focal events present in the data. The segment amplification/deletion levels are in units of (copy number -2), with amplifications positive and deletions negative numbers. This file may be viewed with IGV.
An image showing the correlation between gene counts and frequency of copy number alterations.
A file indicating the position of the confidence intervals around GISTIC peaks that can be loaded as a track in a compatible viewer browser such as IGV or the UCSC genome browser.
GISTIC identifies genomic regions that are significantly gained or lost across a set of tumors. It takes segmented copy number ratios as input, separates arm-level events from focal events, and then performs two tests: (i) identifies significantly amplified/deleted chromosome arms; and (ii) identifies regions that are significantly focally amplified or deleted. For the focal analysis, the significance levels (Q values) are calculated by comparing the observed gains/losses at each locus to those obtained by randomly permuting the events along the genome to reflect the null hypothesis that they are all 'passengers' and could have occurred anywhere. The locus-specific significance levels are then corrected for multiple hypothesis testing. The arm-level significance is calculated by comparing the frequency of gains/losses of each arm to the expected rate given its size. The method outputs genomic views of significantly amplified and deleted regions, as well as a table of genes with gain or loss scores. A more in depth discussion of the GISTIC algorithm and its utility is given in [1], [3], and [5].
Regions of the genome that are prone to germ line variations in copy number are excluded from the GISTIC analysis using a list of germ line copy number variations (CNVs). A CNV is a DNA sequence that may be found at different copy numbers in the germ line of two different individuals. Such germ line variations can confound a GISTIC analysis, which finds significant somatic copy number variations in cancer. A more in depth discussion is provided in [6]. GISTIC currently uses two CNV exclusion lists. One is based on the literature describing copy number variation, and a second one comes from an analysis of significant variations among the blood normals in the TCGA data set.
In addition to the links below, the full results of the analysis summarized in this report can also be downloaded programmatically using firehose_get, or interactively from either the Broad GDAC website or TCGA Data Coordination Center Portal.