This pipeline inspects significant overlapping pathway gene sets for a given gene list using a hypergeometric test. For the gene set database, we uses GSEA MSigDB Class2: Canonical Pathways DB as a gene set data. Further details about the MsigDB gene sets, please visit The Broad Institute GSEA MsigDB
For a given gene list, a hypergeometric test was tried to find significant overlapping canonical pathways using 1320 gene sets. In terms of FDR adjusted p.values, top 5 significant overlapping gene sets are listed as below.
-
KEGG_PATHWAYS_IN_CANCER, KEGG_ENDOMETRIAL_CANCER, REACTOME_IMMUNE_SYSTEM, KEGG_COLORECTAL_CANCER, KEGG_MELANOMA
Table 1. Get Full Table This table shows significant gene sets in which at least one gene is found and its FDR adjusted p.value is smaller than 0.3. the hypergeometric p-value is a probability of randomly drawing x or more successes(gene overlaps in gene set database) from the population (gene universe consisting of N number of genes) in k total draws(the number of input genes). The hypergeometric test is identical to the corresponding one-tailed version of Fisher's exact test. That is, P(X=x) = f(x| N,m,k). The FDR q.value was obtained for 1320 multiple comparison.
| GS(gene set) pathway name | gene.list | GS size (m) | n.NotInGS (n) | Gene universe (N) | n.drawn (k) | n.found (x) | p.value (p(X>=x)) | FDR (q.value) |
|---|---|---|---|---|---|---|---|---|
| KEGG PATHWAYS IN CANCER | gene.list | 328 | 45628 | 45956 | 1421 | 52 | 3.929e-22 | 5.186e-19 |
| KEGG ENDOMETRIAL CANCER | gene.list | 52 | 45904 | 45956 | 1421 | 19 | 5.315e-16 | 3.508e-13 |
| REACTOME IMMUNE SYSTEM | gene.list | 933 | 45023 | 45956 | 1421 | 79 | 1.115e-15 | 4.906e-13 |
| KEGG COLORECTAL CANCER | gene.list | 62 | 45894 | 45956 | 1421 | 18 | 3.060e-13 | 1.010e-10 |
| KEGG MELANOMA | gene.list | 71 | 45885 | 45956 | 1421 | 17 | 4.204e-11 | 1.110e-08 |
| KEGG CHRONIC MYELOID LEUKEMIA | gene.list | 73 | 45883 | 45956 | 1421 | 17 | 6.767e-11 | 1.489e-08 |
| KEGG RENAL CELL CARCINOMA | gene.list | 70 | 45886 | 45956 | 1421 | 16 | 3.307e-10 | 5.457e-08 |
| KEGG PANCREATIC CANCER | gene.list | 70 | 45886 | 45956 | 1421 | 16 | 3.307e-10 | 5.457e-08 |
| REACTOME CYTOKINE SIGNALING IN IMMUNE SYSTEM | gene.list | 270 | 45686 | 45956 | 1421 | 31 | 4.514e-10 | 6.621e-08 |
| REACTOME HEMOSTASIS | gene.list | 466 | 45490 | 45956 | 1421 | 42 | 8.838e-10 | 1.167e-07 |
| KEGG ADHERENS JUNCTION | gene.list | 75 | 45881 | 45956 | 1421 | 16 | 9.861e-10 | 1.183e-07 |
| KEGG PROSTATE CANCER | gene.list | 89 | 45867 | 45956 | 1421 | 17 | 1.821e-09 | 1.849e-07 |
| BIOCARTA TGFB PATHWAY | gene.list | 19 | 45937 | 45956 | 1421 | 9 | 1.760e-09 | 1.849e-07 |
| KEGG MAPK SIGNALING PATHWAY | gene.list | 267 | 45689 | 45956 | 1421 | 29 | 5.841e-09 | 5.507e-07 |
| KEGG NON SMALL CELL LUNG CANCER | gene.list | 54 | 45902 | 45956 | 1421 | 13 | 7.622e-09 | 6.707e-07 |
| KEGG NEUROTROPHIN SIGNALING PATHWAY | gene.list | 126 | 45830 | 45956 | 1421 | 19 | 1.266e-08 | 1.027e-06 |
| BIOCARTA CTCF PATHWAY | gene.list | 23 | 45933 | 45956 | 1421 | 9 | 1.392e-08 | 1.027e-06 |
| PID FANCONI PATHWAY | gene.list | 47 | 45909 | 45956 | 1421 | 12 | 1.400e-08 | 1.027e-06 |
| REACTOME METABOLISM OF LIPIDS AND LIPOPROTEINS | gene.list | 478 | 45478 | 45956 | 1421 | 40 | 1.779e-08 | 1.236e-06 |
| PID MET PATHWAY | gene.list | 80 | 45876 | 45956 | 1421 | 15 | 2.116e-08 | 1.331e-06 |
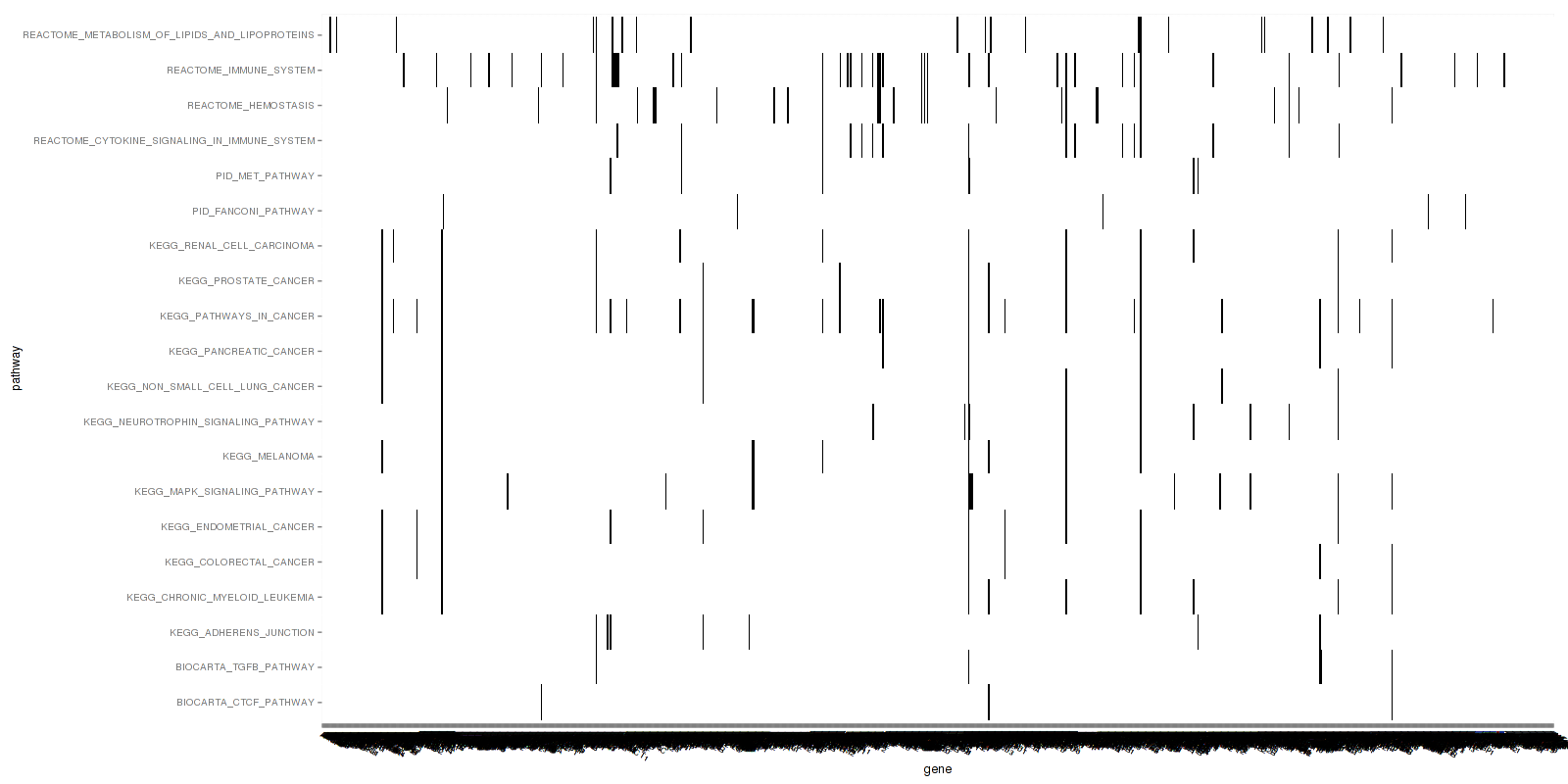
Figure 1. Get High-res Image This figure is an event heatmap indicating gene matches across gene sets
-
Gene set database = c2.cp.v4.0.symbols.gmt
-
Input gene list = MutSig2CV.input.genenames.txt
For a given gene list, it uses a hypergeometric test to get a significance of each overlapping pathway gene set. The hypergeometric p-value is obtained by R library function phyper() and is defined as a probability of randomly drawing x or more successes(gene matches) from the population consisting N genes in k(the input genes) total draws.
-
a cumulative p-value using the R function phyper():
-
ex). a probability to see at least x genes in the group is defined as p(X>=x) = 1 - p(X<=x)= 1 - phyper(x-1, m, n, k, lower.tail=FALSE, log.p=FALSE) that is, f(x| N, m, k) = (m) C (k) * ((N-m) C (n-k)) / ((N) C (n))
-
The hypergeometric test is identical to the corresponding one-tailed version of Fisher's exact test.
-
ex). Fisher' exact test = matrix(c(n.Found, n.GS-n.Found, n.drawn-n.Found, n.NotGS- (n.drawn-n.Found)), nrow=2, dimnames = list(inputGenes = c("Found", "NotFound"),GeneUniverse = c("GS", "nonGS")) )
In addition to the links below, the full results of the analysis summarized in this report can also be downloaded programmatically using firehose_get, or interactively from either the Broad GDAC website or TCGA Data Coordination Center Portal.