This report serves to describe the mutational landscape and properties of a given individual set, as well as rank genes and genesets according to mutational significance. MutSig v2.0 was used to generate the results found in this report.
-
Working with individual set: STAD-TP
-
Number of patients in set: 116
The input for this pipeline is a set of individuals with the following files associated for each:
-
An annotated .maf file describing the mutations called for the respective individual, and their properties.
-
A .wig file that contains information about the coverage of the sample.
-
MAF used for this analysis:STAD-TP.final_analysis_set.maf
-
Significantly mutated genes (q ≤ 0.1): 37
-
Mutations seen in COSMIC: 291
-
Significantly mutated genes in COSMIC territory: 19
-
Genes with clustered mutations (≤ 3 aa apart): 969
-
Significantly mutated genesets: 17
-
Significantly mutated genesets: (excluding sig. mutated genes):0
-
Read 116 MAFs of type "Broad"
-
Total number of mutations in input MAFs: 192216
-
After removing 5994 blacklisted mutations: 186222
-
After removing 102470 noncoding mutations: 83752
-
After collapsing adjacent/redundant mutations: 64521
-
Number of mutations before filtering: 64521
-
After removing 316 mutations outside gene set: 64205
-
After removing 72 mutations outside category set: 64133
-
After removing 2 "impossible" mutations in
-
gene-patient-category bins of zero coverage: 63743
Table 1. Get Full Table Table representing breakdown of mutations by type.
| type | count |
|---|---|
| Frame_Shift_Del | 1639 |
| Frame_Shift_Ins | 233 |
| In_Frame_Del | 111 |
| In_Frame_Ins | 7 |
| Missense_Mutation | 41478 |
| Nonsense_Mutation | 1924 |
| Nonstop_Mutation | 47 |
| Silent | 17734 |
| Splice_Site | 936 |
| Translation_Start_Site | 24 |
| Total | 64133 |
Table 2. Get Full Table A breakdown of mutation rates per category discovered for this individual set.
| category | n | N | rate | rate_per_mb | relative_rate | exp_ns_s_ratio |
|---|---|---|---|---|---|---|
| *CpG->T | 14400 | 187756957 | 0.000077 | 77 | 5.6 | 2.1 |
| *Np(A/C/T)->transit | 14106 | 2700753364 | 5.2e-06 | 5.2 | 0.38 | 2 |
| *ApG->G | 1984 | 523468245 | 3.8e-06 | 3.8 | 0.28 | 2.1 |
| transver | 11010 | 3411978566 | 3.2e-06 | 3.2 | 0.24 | 5 |
| indel+null | 4829 | 3411978566 | 1.4e-06 | 1.4 | 0.1 | NaN |
| double_null | 69 | 3411978566 | 2e-08 | 0.02 | 0.0015 | NaN |
| Total | 46398 | 3411978566 | 0.000014 | 14 | 1 | 3.5 |
The x axis represents the samples. The y axis represents the exons, one row per exon, and they are sorted by average coverage across samples. For exons with exactly the same average coverage, they are sorted next by the %GC of the exon. (The secondary sort is especially useful for the zero-coverage exons at the bottom).
Figure 1.
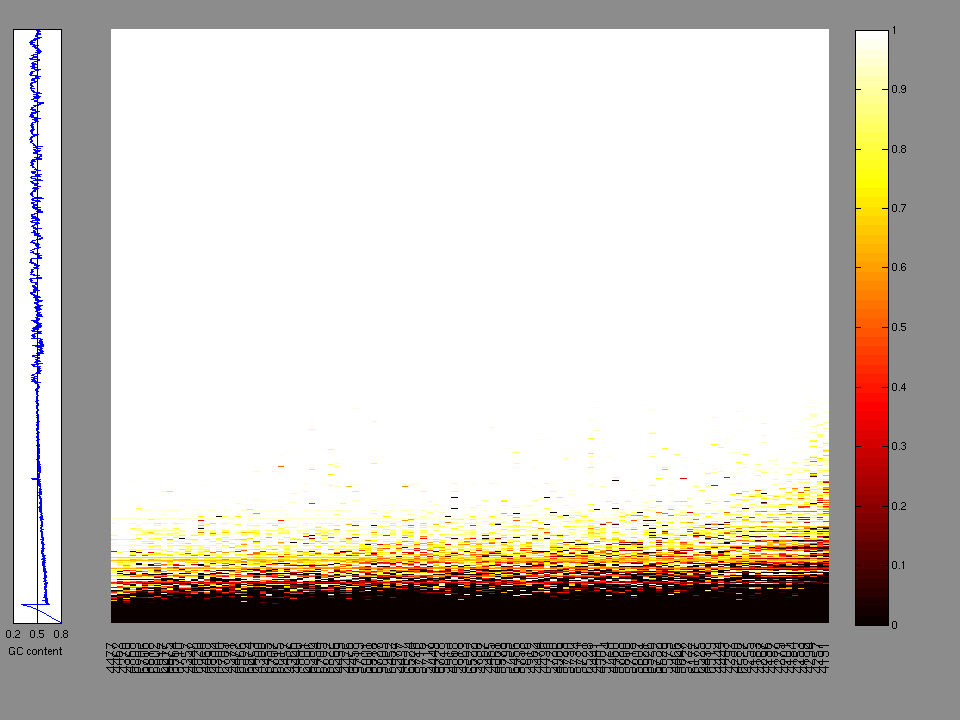
Figure 2. Patients counts and rates file used to generate this plot: STAD-TP.patients.counts_and_rates.txt
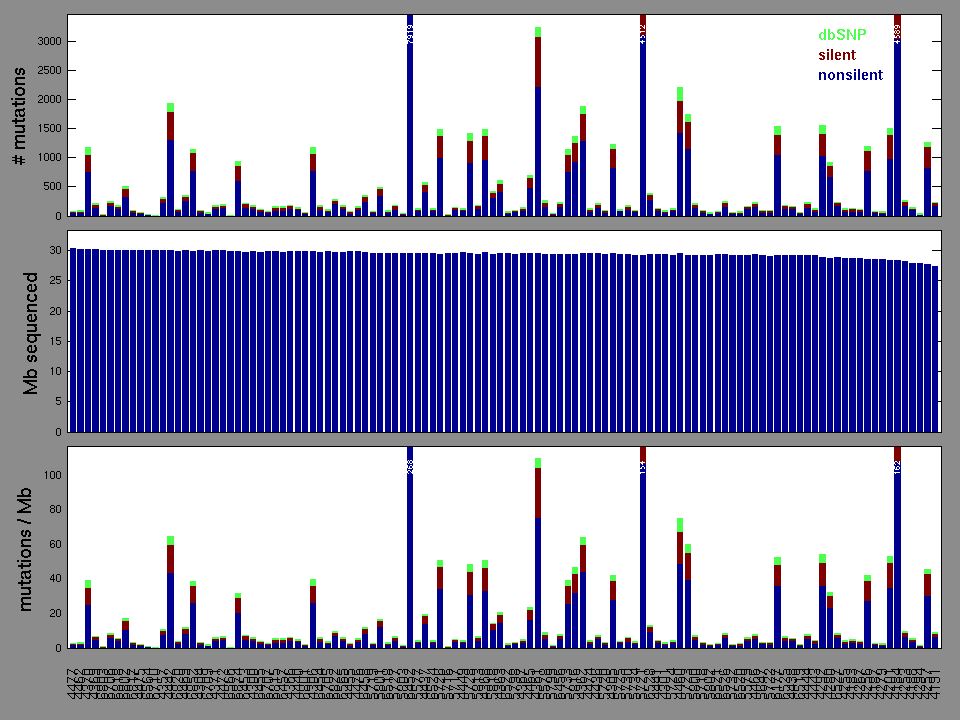
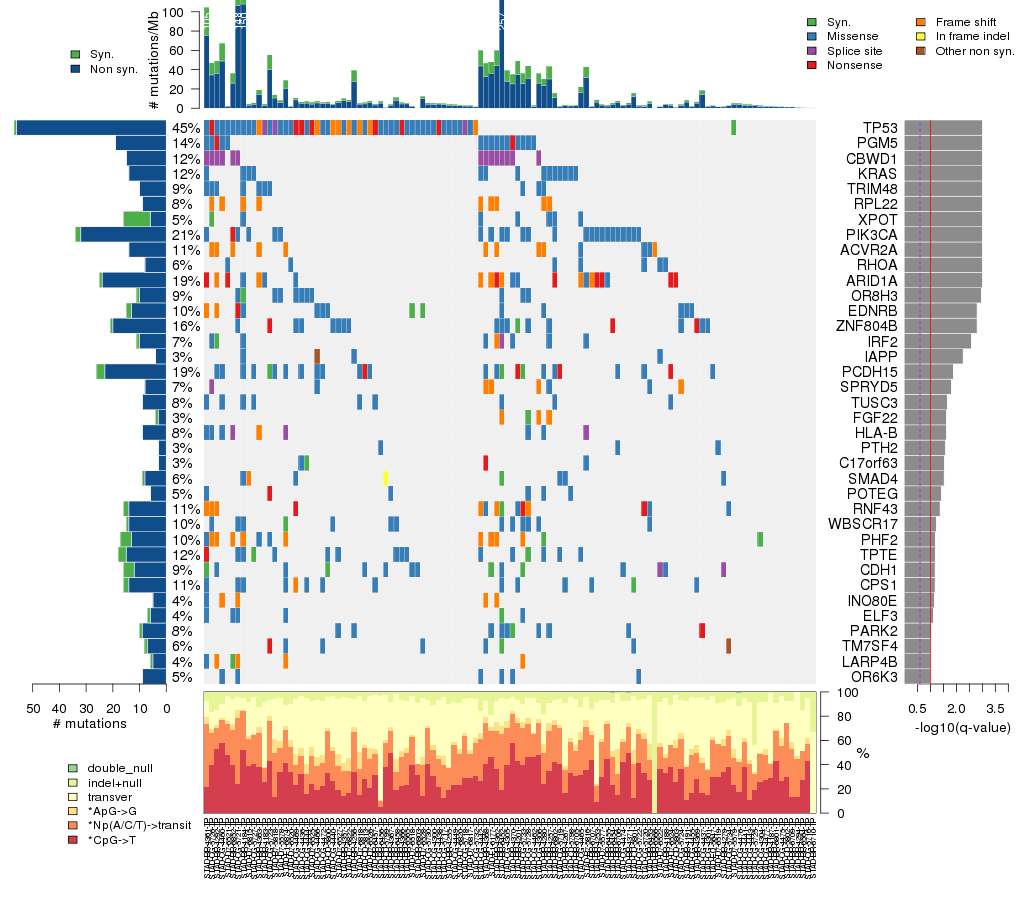
Figure 3. Get High-res Image The matrix in the center of the figure represents individual mutations in patient samples, color-coded by type of mutation, for the significantly mutated genes. The rate of synonymous and non-synonymous mutations is displayed at the top of the matrix. The barplot on the left of the matrix shows the number of mutations in each gene. The percentages represent the fraction of tumors with at least one mutation in the specified gene. The barplot to the right of the matrix displays the q-values for the most significantly mutated genes. The purple boxplots below the matrix (only displayed if required columns are present in the provided MAF) represent the distributions of allelic fractions observed in each sample. The plot at the bottom represents the base substitution distribution of individual samples, using the same categories that were used to calculate significance.
Column Descriptions:
-
N = number of sequenced bases in this gene across the individual set
-
n = number of (nonsilent) mutations in this gene across the individual set
-
npat = number of patients (individuals) with at least one nonsilent mutation
-
nsite = number of unique sites having a non-silent mutation
-
nsil = number of silent mutations in this gene across the individual set
-
n1 = number of nonsilent mutations of type: *CpG->T
-
n2 = number of nonsilent mutations of type: *Np(A/C/T)->transit
-
n3 = number of nonsilent mutations of type: *ApG->G
-
n4 = number of nonsilent mutations of type: transver
-
n5 = number of nonsilent mutations of type: indel+null
-
n6 = number of nonsilent mutations of type: double_null
-
p_classic = p-value for the observed amount of nonsilent mutations being elevated in this gene
-
p_ns_s = p-value for the observed nonsilent/silent ratio being elevated in this gene
-
p_cons = p-value for enrichment of mutations at evolutionarily most-conserved sites in gene
-
p_joint = p-value for clustering + conservation
-
p = p-value (overall)
-
q = q-value, False Discovery Rate (Benjamini-Hochberg procedure)
Table 3. Get Full Table A Ranked List of Significantly Mutated Genes. Number of significant genes found: 37. Number of genes displayed: 35. Click on a gene name to display its stick figure depicting the distribution of mutations and mutation types across the chosen gene (this feature may not be available for all significant genes).
| rank | gene | description | N | n | npat | nsite | nsil | n1 | n2 | n3 | n4 | n5 | n6 | p_classic | p_ns_s | p_cons | p_joint | p | q |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | TP53 | tumor protein p53 | 144134 | 56 | 52 | 41 | 1 | 18 | 12 | 1 | 7 | 17 | 1 | 1.1e-15 | 2.6e-06 | 1.6e-06 | 0 | <1.00e-15 | <2.57e-12 |
| 2 | PGM5 | phosphoglucomutase 5 | 164179 | 19 | 16 | 5 | 0 | 3 | 14 | 0 | 0 | 2 | 0 | 1.2e-09 | 0.00064 | 1 | 0 | <1.00e-15 | <2.57e-12 |
| 3 | CBWD1 | COBW domain containing 1 | 115744 | 15 | 14 | 2 | 0 | 0 | 1 | 0 | 0 | 14 | 0 | 5.1e-11 | 0.076 | 8.8e-06 | 0 | <1.00e-15 | <2.57e-12 |
| 4 | KRAS | v-Ki-ras2 Kirsten rat sarcoma viral oncogene homolog | 81393 | 14 | 14 | 6 | 0 | 0 | 10 | 0 | 4 | 0 | 0 | 6.1e-14 | 0.013 | 0.00087 | 0 | <1.00e-15 | <2.57e-12 |
| 5 | TRIM48 | tripartite motif-containing 48 | 74295 | 10 | 10 | 2 | 0 | 0 | 9 | 0 | 1 | 0 | 0 | 6.5e-08 | 0.018 | 0.86 | 0 | <1.00e-15 | <2.57e-12 |
| 6 | RPL22 | ribosomal protein L22 | 44234 | 9 | 9 | 1 | 0 | 0 | 0 | 0 | 0 | 9 | 0 | 6e-09 | 1 | 0.06 | 0 | <1.00e-15 | <2.57e-12 |
| 7 | XPOT | exportin, tRNA (nuclear export receptor for tRNAs) | 345938 | 6 | 6 | 1 | 10 | 0 | 6 | 0 | 0 | 0 | 0 | 1 | 1 | 0.98 | 0 | <1.00e-15 | <2.57e-12 |
| 8 | PIK3CA | phosphoinositide-3-kinase, catalytic, alpha polypeptide | 381238 | 32 | 24 | 19 | 2 | 5 | 19 | 3 | 4 | 1 | 0 | 5.7e-12 | 0.0015 | 0.05 | 0.0037 | 6.84e-13 | 1.54e-09 |
| 9 | ACVR2A | activin A receptor, type IIA | 183945 | 14 | 13 | 5 | 0 | 0 | 3 | 0 | 1 | 10 | 0 | 3.4e-09 | 0.28 | 0.022 | 0.000027 | 2.89e-12 | 5.78e-09 |
| 10 | RHOA | ras homolog gene family, member A | 69368 | 8 | 7 | 4 | 0 | 0 | 5 | 0 | 3 | 0 | 0 | 4.1e-08 | 0.089 | 0.23 | 0.000064 | 7.28e-11 | 1.31e-07 |
| 11 | ARID1A | AT rich interactive domain 1A (SWI-like) | 674991 | 24 | 22 | 23 | 1 | 4 | 1 | 0 | 4 | 13 | 2 | 3.2e-10 | 0.03 | 0.14 | 0.42 | 3.19e-09 | 5.21e-06 |
| 12 | OR8H3 | olfactory receptor, family 8, subfamily H, member 3 | 109388 | 10 | 10 | 8 | 1 | 0 | 4 | 3 | 3 | 0 | 0 | 4.5e-08 | 0.1 | 0.016 | 0.048 | 4.48e-08 | 6.73e-05 |
| 13 | EDNRB | endothelin receptor type B | 161210 | 13 | 12 | 12 | 2 | 5 | 4 | 0 | 1 | 3 | 0 | 1.3e-07 | 0.14 | 0.95 | 0.2 | 4.57e-07 | 0.000595 |
| 14 | ZNF804B | zinc finger protein 804B | 471407 | 20 | 18 | 19 | 1 | 0 | 6 | 0 | 11 | 3 | 0 | 7.3e-08 | 0.042 | 0.74 | 0.34 | 4.63e-07 | 0.000595 |
| 15 | IRF2 | interferon regulatory factor 2 | 125493 | 10 | 8 | 10 | 1 | 4 | 0 | 0 | 4 | 1 | 1 | 0.00012 | 0.2 | 0.034 | 0.00062 | 1.33e-06 | 0.00160 |
| 16 | IAPP | islet amyloid polypeptide | 32248 | 4 | 4 | 3 | 0 | 0 | 0 | 0 | 4 | 0 | 0 | 0.00012 | 0.47 | 0.98 | 0.002 | 3.99e-06 | 0.00449 |
| 17 | PCDH15 | protocadherin 15 | 860677 | 23 | 22 | 23 | 3 | 1 | 5 | 5 | 8 | 4 | 0 | 1.8e-06 | 0.033 | 1 | 0.38 | 1.07e-05 | 0.0114 |
| 18 | SPRYD5 | SPRY domain containing 5 | 106259 | 8 | 8 | 6 | 0 | 0 | 0 | 1 | 2 | 5 | 0 | 9.6e-07 | 0.45 | 1 | 1 | 1.42e-05 | 0.0142 |
| 19 | TUSC3 | tumor suppressor candidate 3 | 124898 | 9 | 9 | 8 | 0 | 3 | 1 | 0 | 5 | 0 | 0 | 8.6e-06 | 0.13 | 0.2 | 0.18 | 2.26e-05 | 0.0214 |
| 20 | FGF22 | fibroblast growth factor 22 | 21067 | 3 | 3 | 1 | 1 | 0 | 0 | 0 | 0 | 3 | 0 | 0.0011 | 1 | 0.98 | 0.0016 | 2.52e-05 | 0.0227 |
| 21 | HLA-B | major histocompatibility complex, class I, B | 115097 | 9 | 9 | 9 | 0 | 1 | 2 | 1 | 1 | 3 | 1 | 4.8e-06 | 0.059 | 0.17 | 0.4 | 2.73e-05 | 0.0234 |
| 22 | PTH2 | parathyroid hormone 2 | 24302 | 3 | 3 | 1 | 0 | 0 | 0 | 0 | 3 | 0 | 0 | 0.0013 | 0.43 | 0.13 | 0.0016 | 3.07e-05 | 0.0252 |
| 23 | C17orf63 | chromosome 17 open reading frame 63 | 8520 | 3 | 3 | 3 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0.000035 | 0.33 | NaN | NaN | 3.47e-05 | 0.0272 |
| 24 | SMAD4 | SMAD family member 4 | 197386 | 8 | 7 | 7 | 1 | 3 | 1 | 0 | 2 | 2 | 0 | 0.000087 | 0.41 | 0.12 | 0.032 | 3.81e-05 | 0.0286 |
| 25 | POTEG | POTE ankyrin domain family, member G | 142733 | 6 | 6 | 6 | 0 | 0 | 4 | 1 | 0 | 1 | 0 | 0.00092 | 0.13 | 0.79 | 0.004 | 4.97e-05 | 0.0358 |
| 26 | RNF43 | ring finger protein 43 | 253364 | 14 | 13 | 9 | 2 | 1 | 4 | 0 | 0 | 9 | 0 | 0.000052 | 0.42 | 0.21 | 0.085 | 5.96e-05 | 0.0413 |
| 27 | WBSCR17 | Williams-Beuren syndrome chromosome region 17 | 208730 | 14 | 12 | 12 | 1 | 6 | 5 | 2 | 1 | 0 | 0 | 0.000072 | 0.026 | 0.66 | 0.094 | 8.72e-05 | 0.0582 |
| 28 | PHF2 | PHD finger protein 2 | 308623 | 13 | 12 | 5 | 4 | 2 | 1 | 0 | 1 | 9 | 0 | 0.011 | 0.88 | 0.43 | 0.00068 | 9.57e-05 | 0.0606 |
| 29 | TPTE | transmembrane phosphatase with tensin homology | 201815 | 15 | 14 | 15 | 3 | 2 | 0 | 1 | 11 | 1 | 0 | 1e-05 | 0.44 | 0.89 | 0.75 | 9.75e-05 | 0.0606 |
| 30 | CDH1 | cadherin 1, type 1, E-cadherin (epithelial) | 294862 | 12 | 11 | 12 | 4 | 1 | 4 | 1 | 4 | 2 | 0 | 0.00099 | 0.49 | 0.018 | 0.0086 | 0.000109 | 0.0650 |
| 31 | CPS1 | carbamoyl-phosphate synthetase 1, mitochondrial | 541853 | 14 | 13 | 14 | 2 | 3 | 2 | 2 | 6 | 1 | 0 | 0.0036 | 0.22 | 0.19 | 0.0024 | 0.000112 | 0.0650 |
| 32 | INO80E | INO80 complex subunit E | 47311 | 5 | 5 | 2 | 0 | 1 | 0 | 0 | 0 | 4 | 0 | 0.00042 | 0.64 | 0.036 | 0.022 | 0.000118 | 0.0662 |
| 33 | ELF3 | E74-like factor 3 (ets domain transcription factor, epithelial-specific ) | 132764 | 6 | 5 | 6 | 1 | 0 | 3 | 0 | 3 | 0 | 0 | 0.044 | 0.39 | 0.00012 | 0.00025 | 0.000134 | 0.0734 |
| 34 | PARK2 | Parkinson disease (autosomal recessive, juvenile) 2, parkin | 165616 | 9 | 9 | 9 | 1 | 3 | 3 | 0 | 2 | 1 | 0 | 0.00021 | 0.17 | 0.49 | 0.069 | 0.000174 | 0.0922 |
| 35 | TM7SF4 | transmembrane 7 superfamily member 4 | 165300 | 7 | 7 | 7 | 1 | 1 | 0 | 2 | 2 | 2 | 0 | 0.000064 | 0.32 | 0.91 | 0.25 | 0.000194 | 0.0981 |
Figure S1. This figure depicts the distribution of mutations and mutation types across the TP53 significant gene.
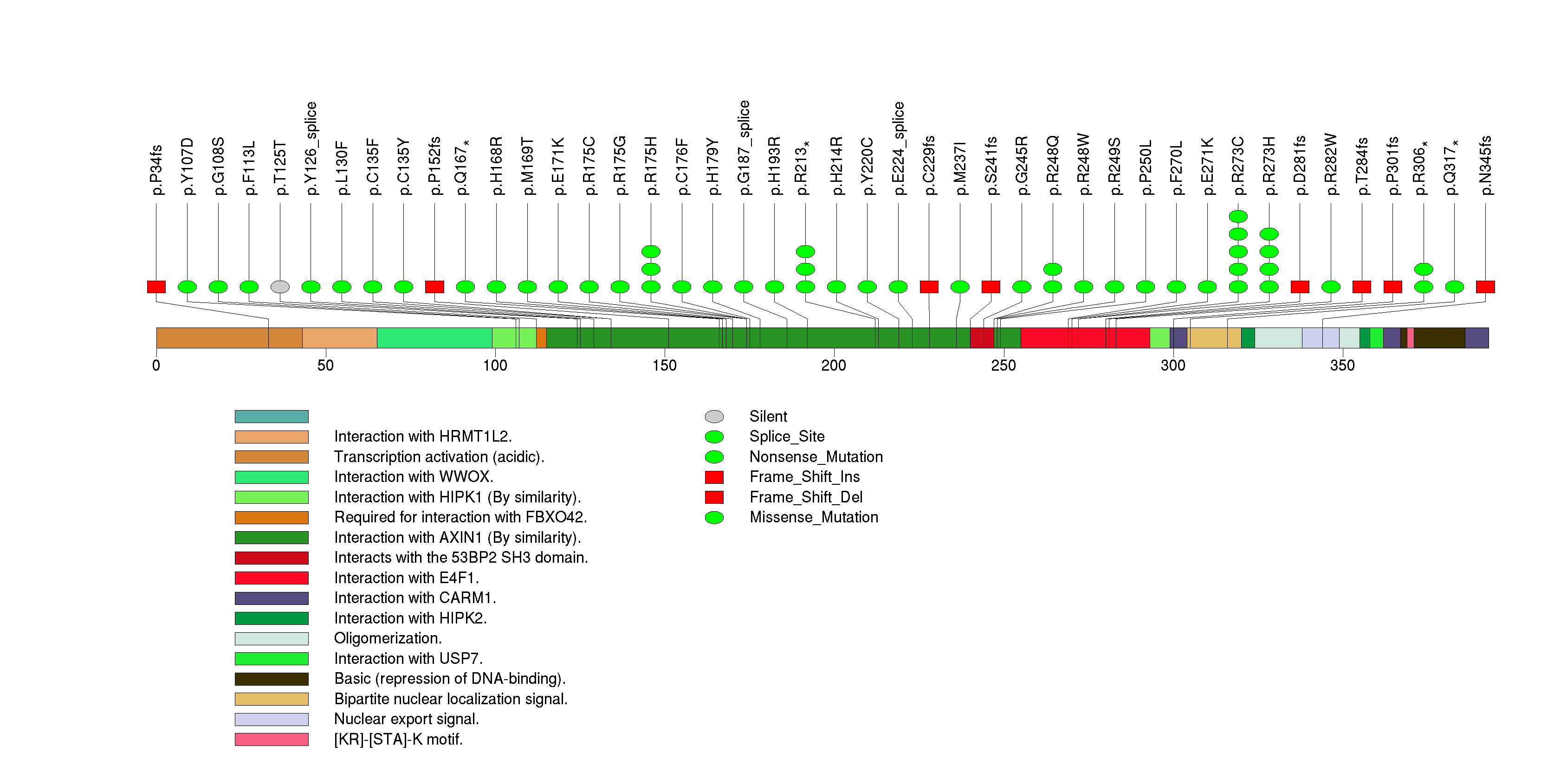
Figure S2. This figure depicts the distribution of mutations and mutation types across the PGM5 significant gene.
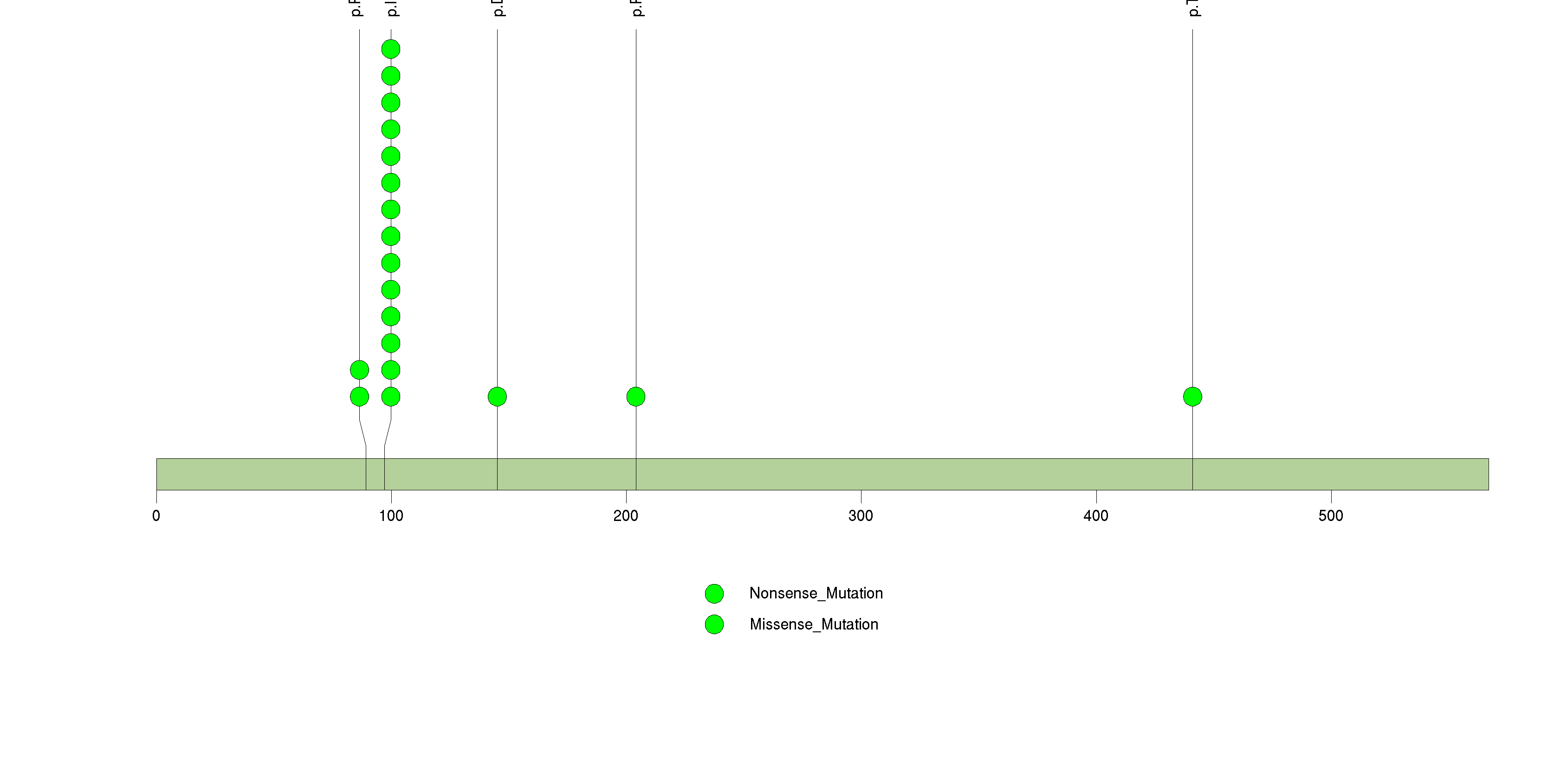
Figure S3. This figure depicts the distribution of mutations and mutation types across the KRAS significant gene.
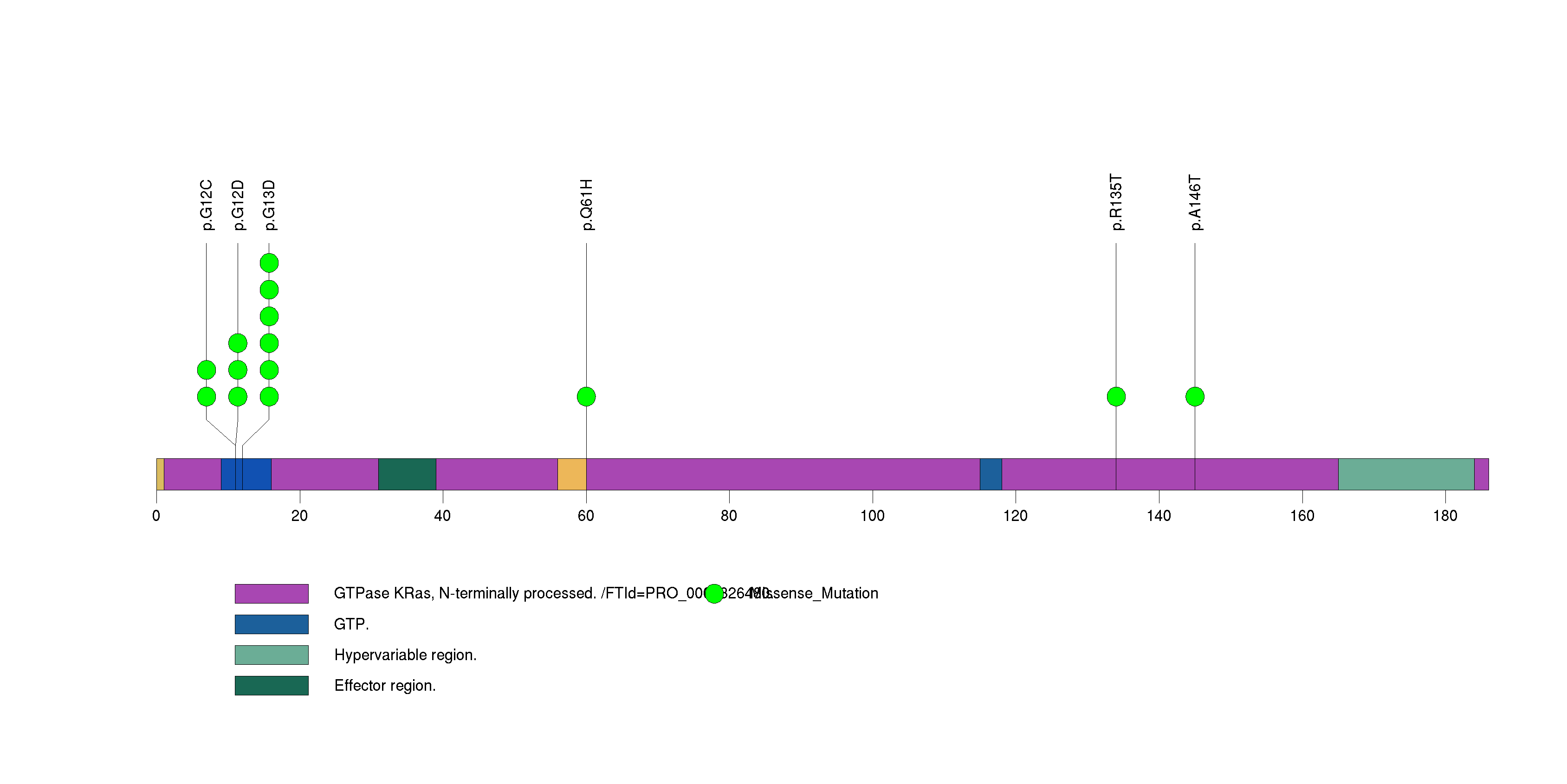
Figure S4. This figure depicts the distribution of mutations and mutation types across the TRIM48 significant gene.
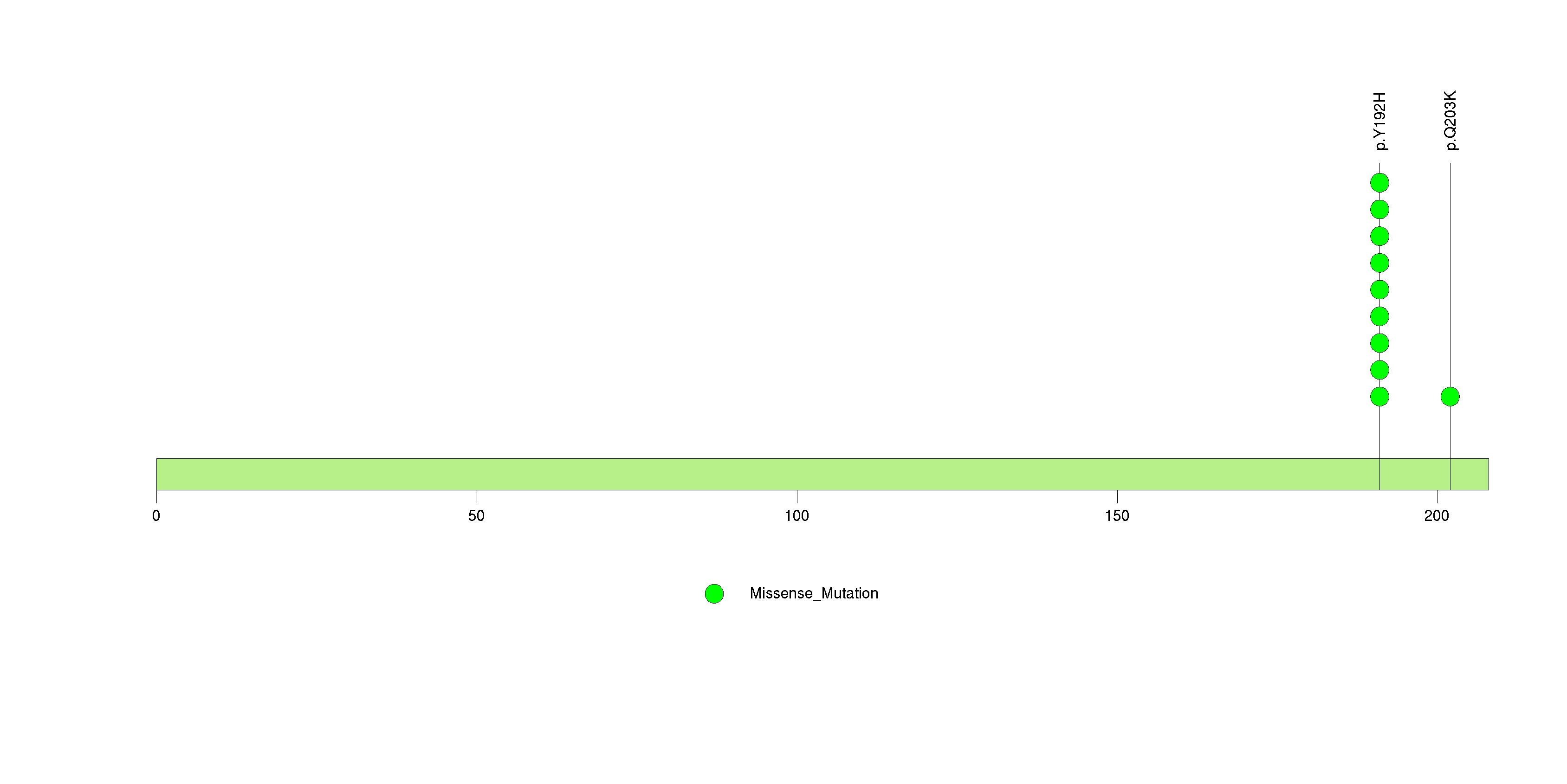
Figure S5. This figure depicts the distribution of mutations and mutation types across the RPL22 significant gene.

Figure S6. This figure depicts the distribution of mutations and mutation types across the XPOT significant gene.
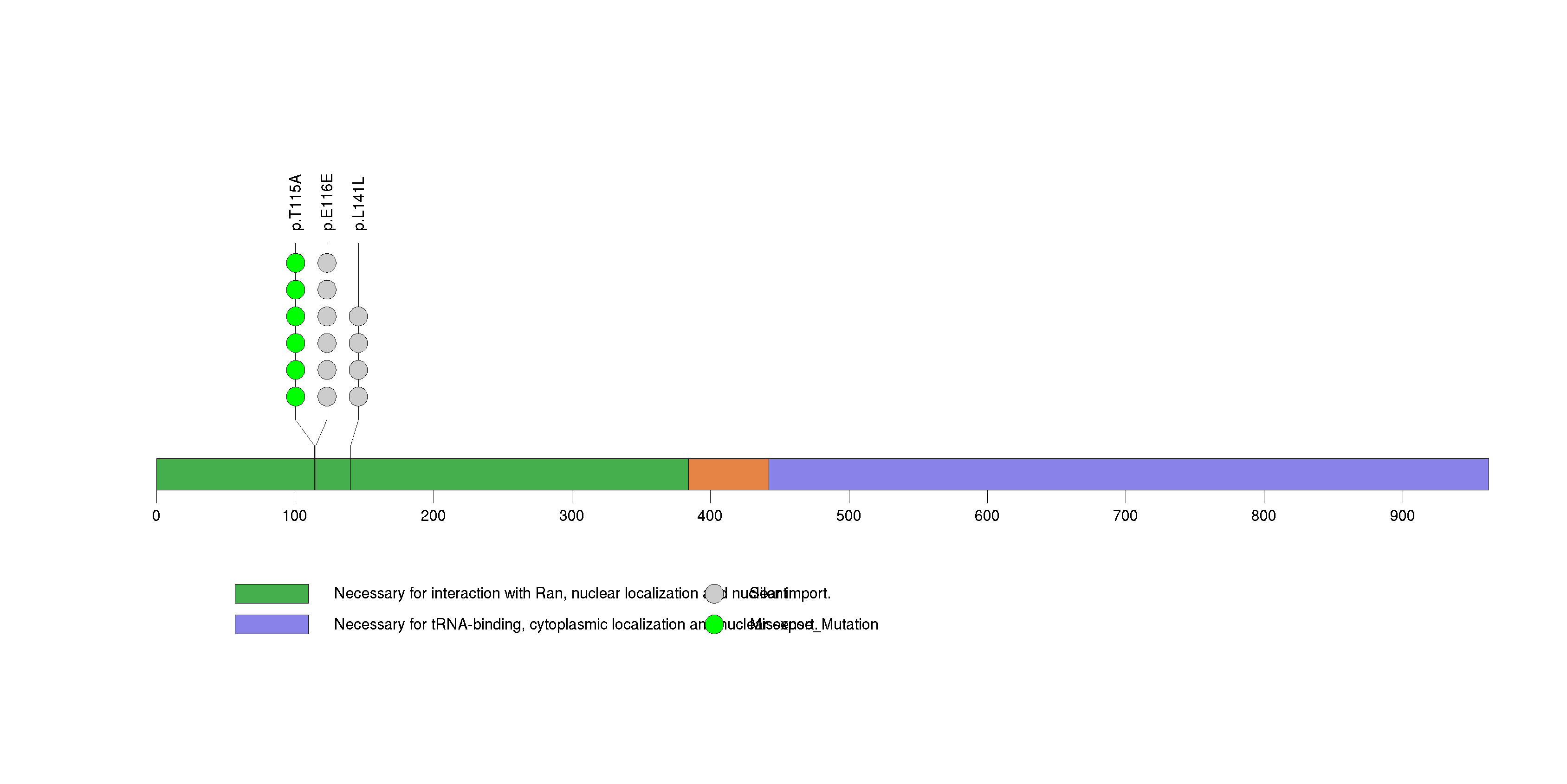
Figure S7. This figure depicts the distribution of mutations and mutation types across the PIK3CA significant gene.
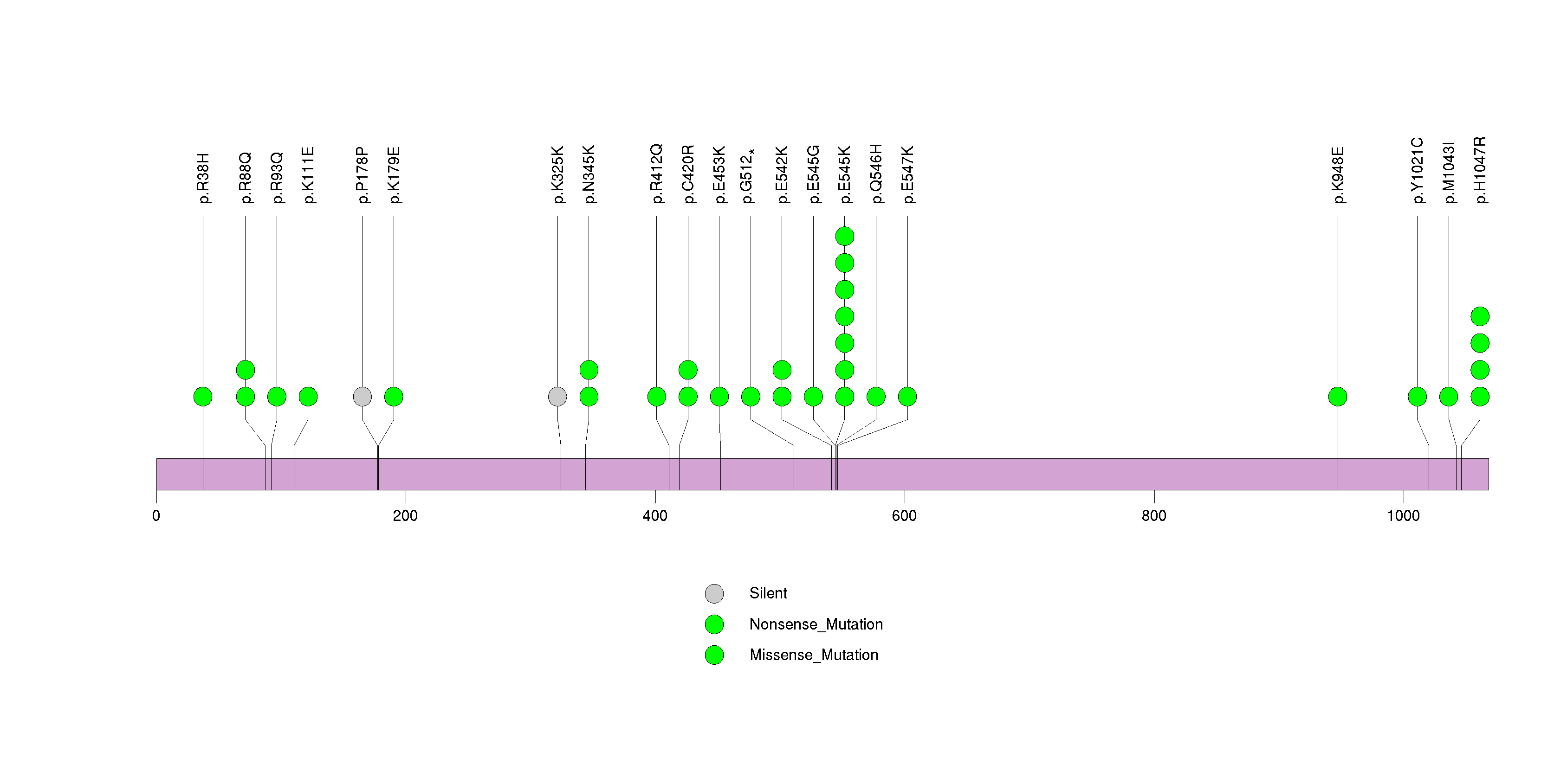
Figure S8. This figure depicts the distribution of mutations and mutation types across the ACVR2A significant gene.

Figure S9. This figure depicts the distribution of mutations and mutation types across the RHOA significant gene.
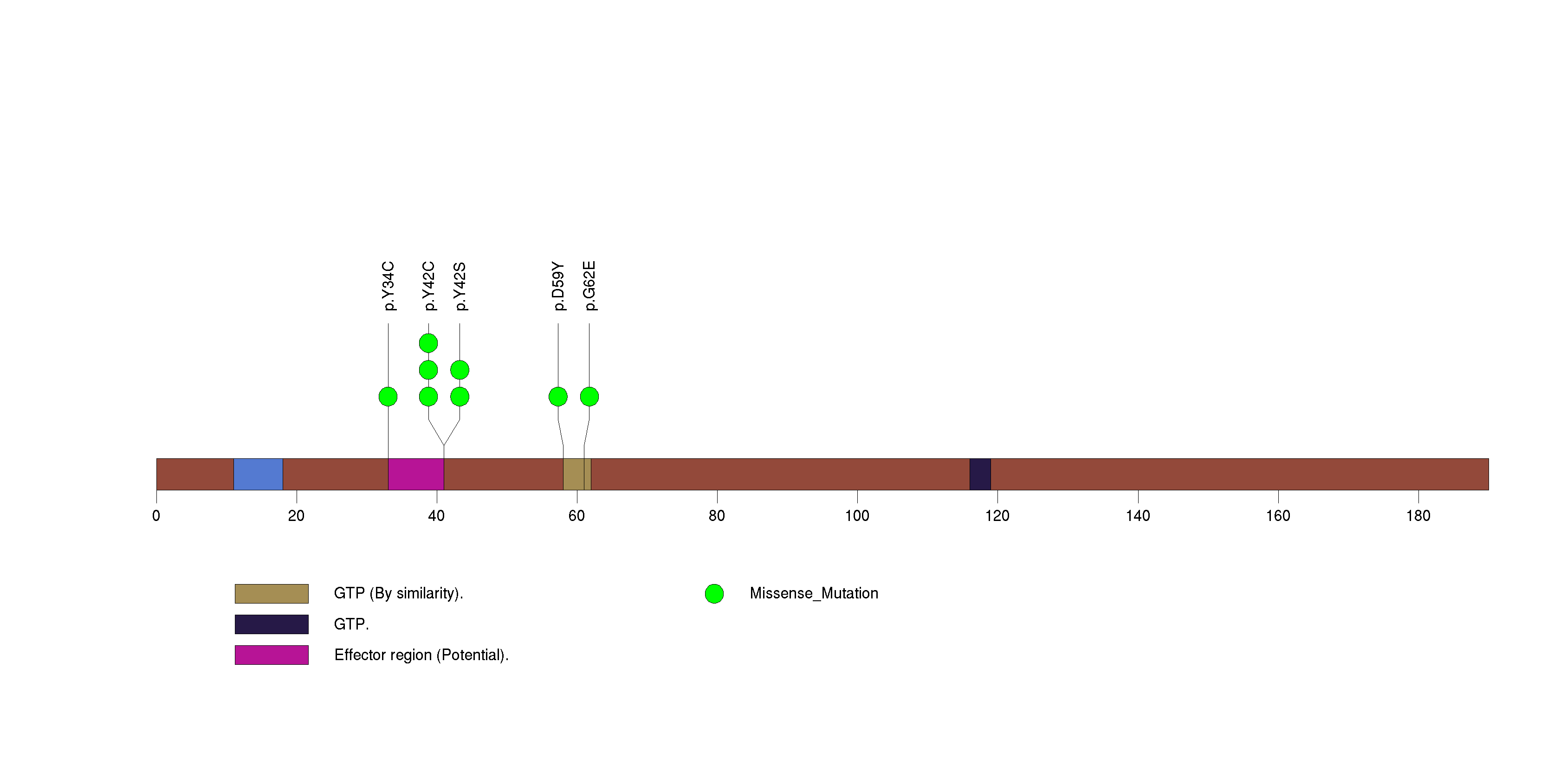
Figure S10. This figure depicts the distribution of mutations and mutation types across the ARID1A significant gene.
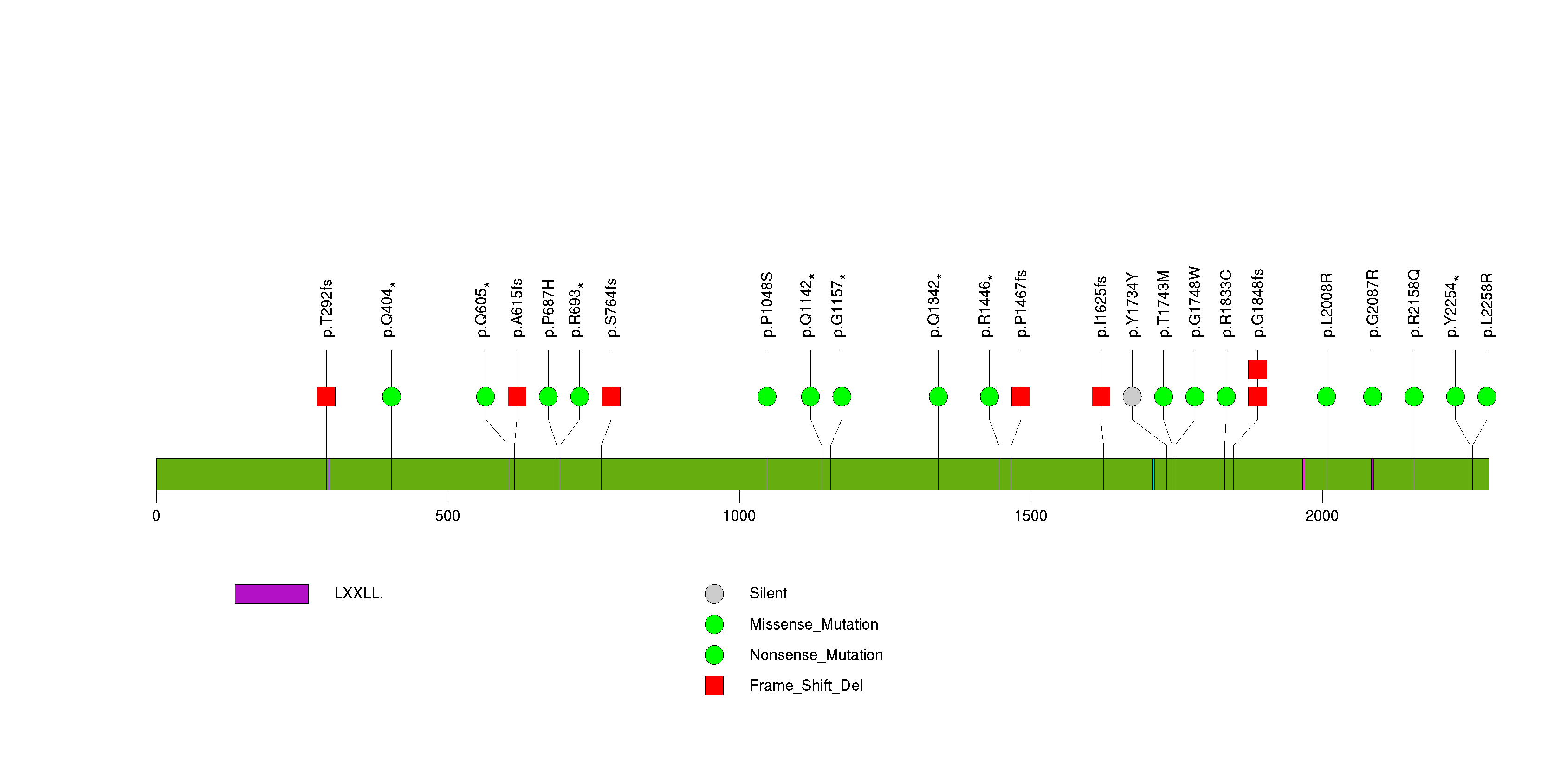
Figure S11. This figure depicts the distribution of mutations and mutation types across the OR8H3 significant gene.
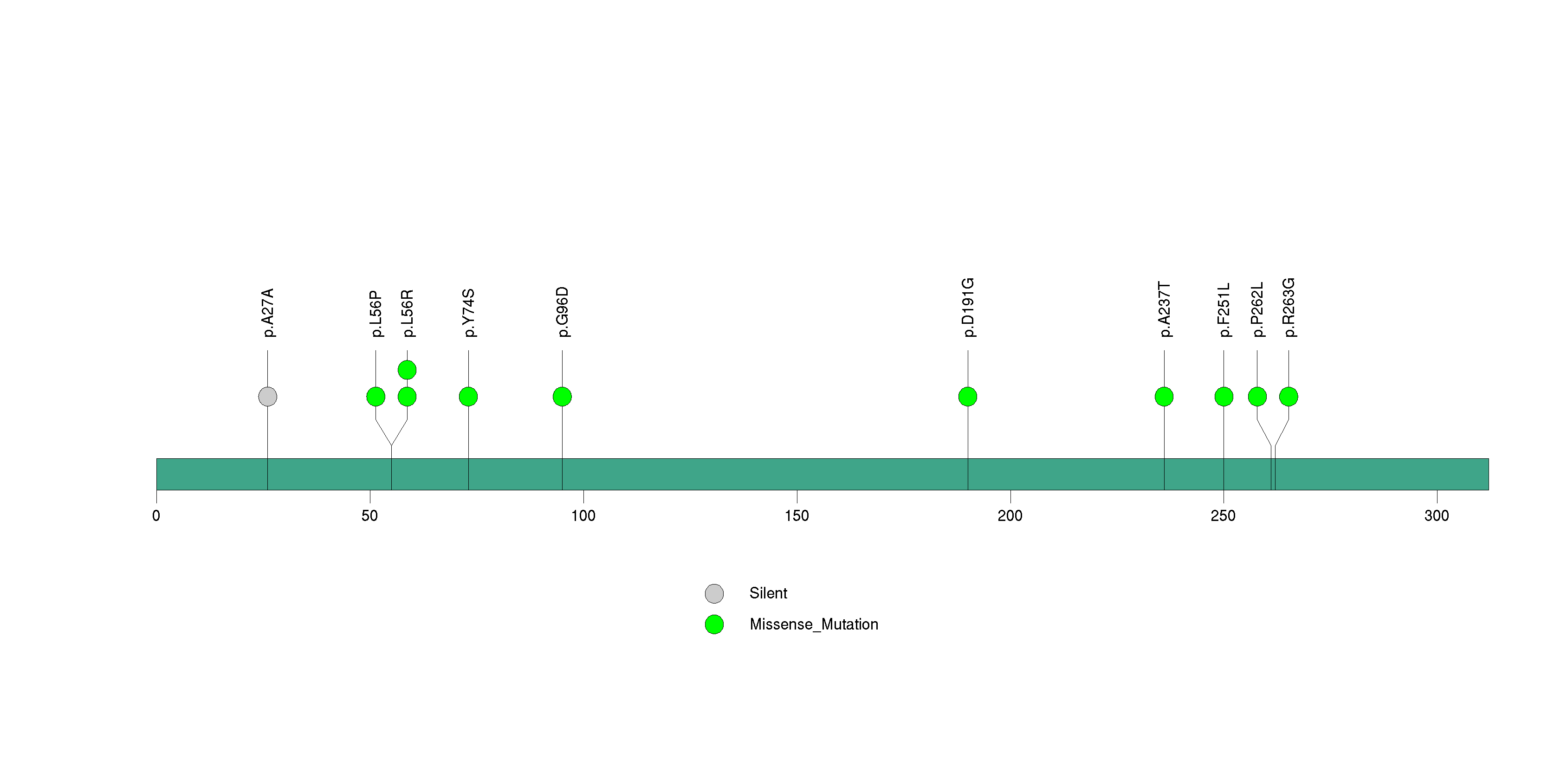
Figure S12. This figure depicts the distribution of mutations and mutation types across the EDNRB significant gene.
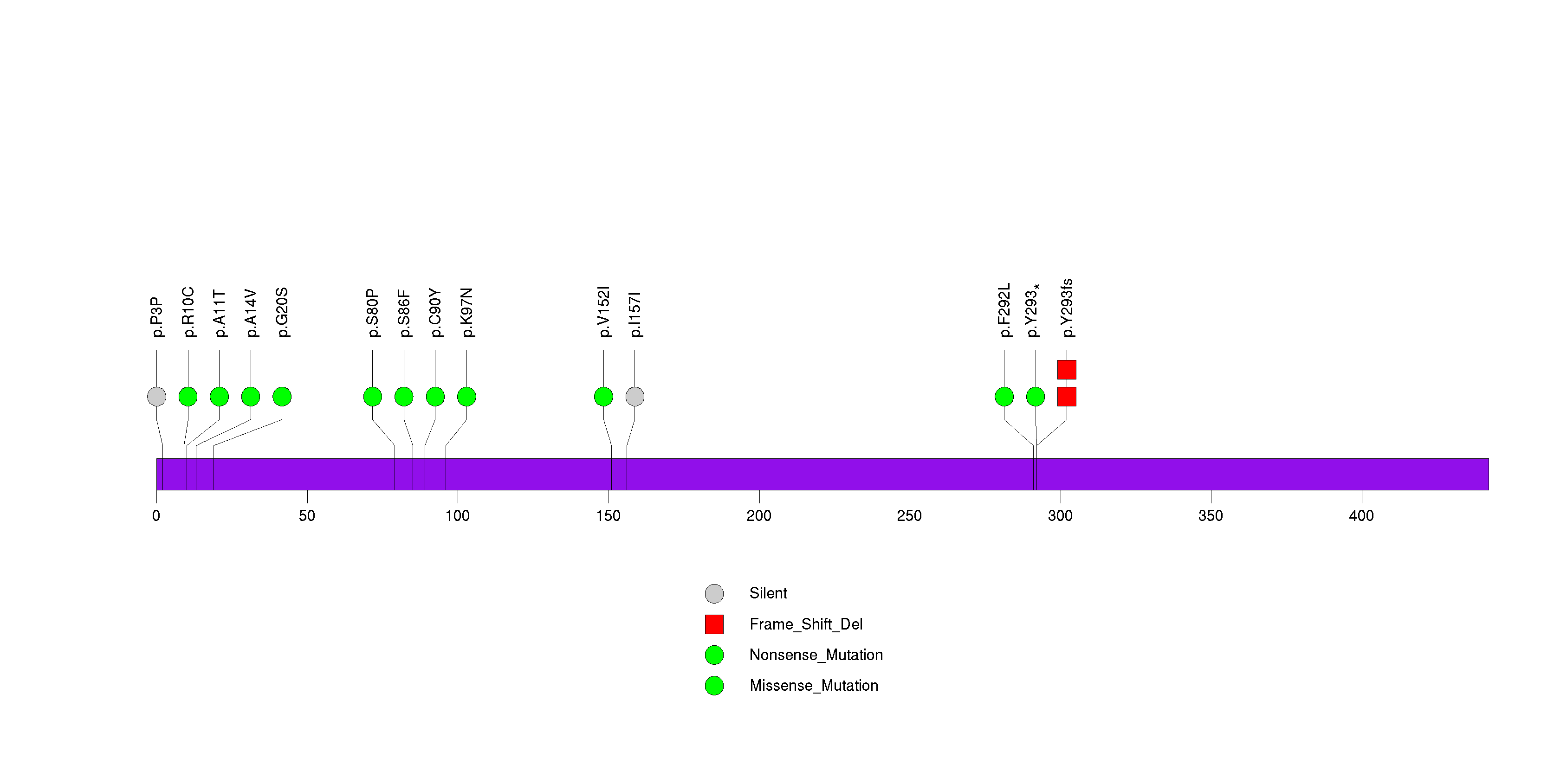
Figure S13. This figure depicts the distribution of mutations and mutation types across the ZNF804B significant gene.
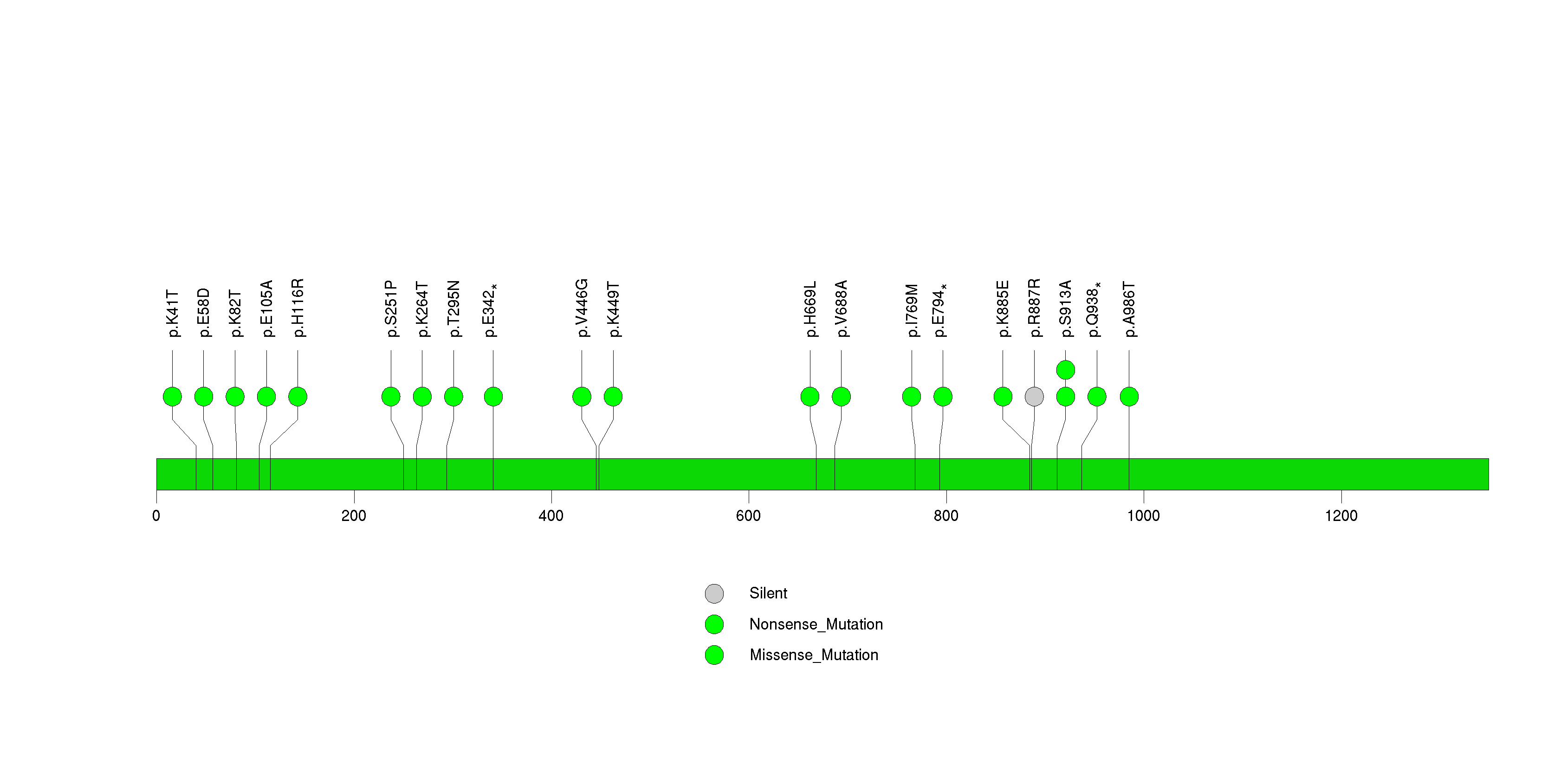
Figure S14. This figure depicts the distribution of mutations and mutation types across the IRF2 significant gene.
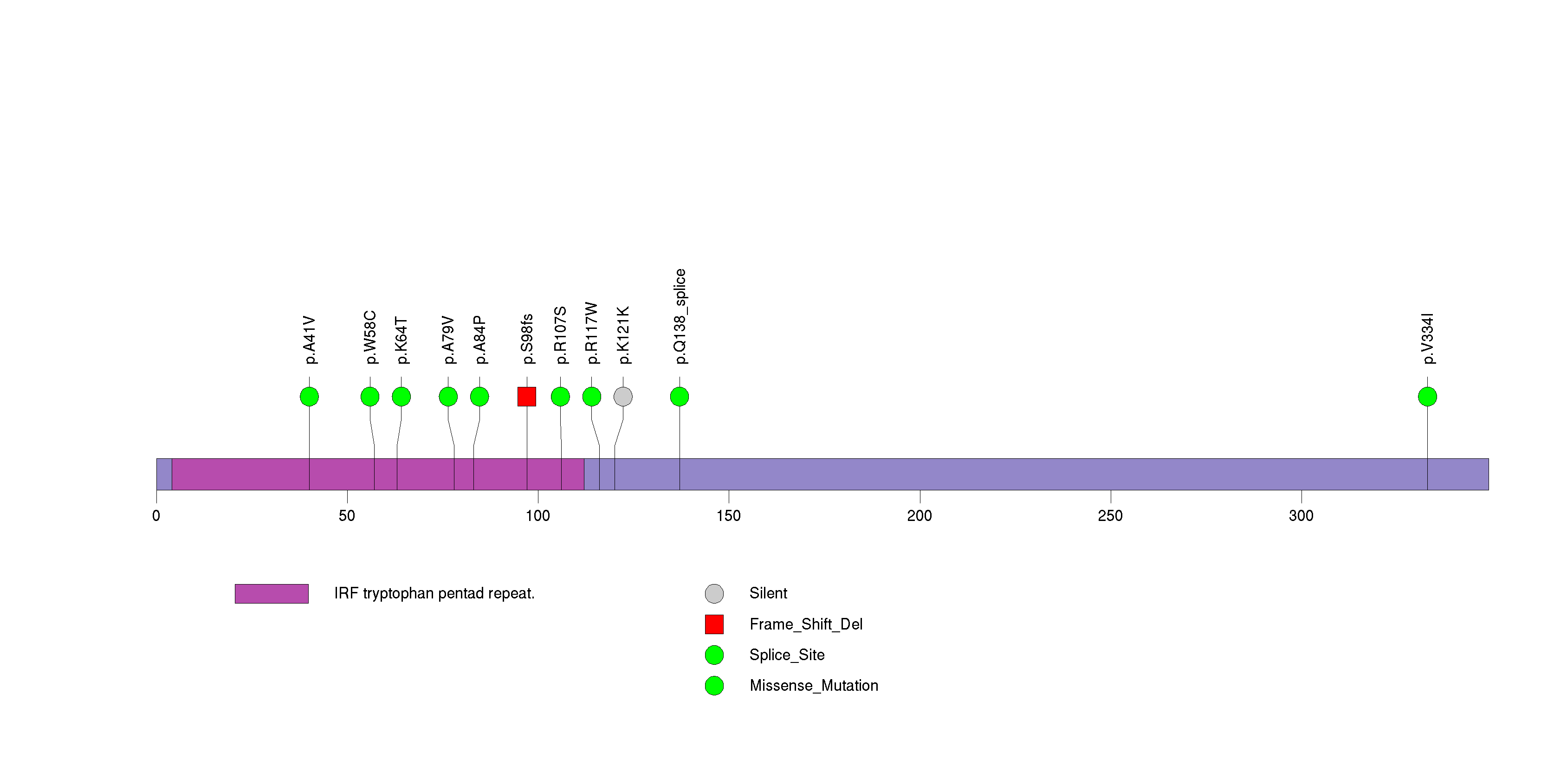
Figure S15. This figure depicts the distribution of mutations and mutation types across the PCDH15 significant gene.
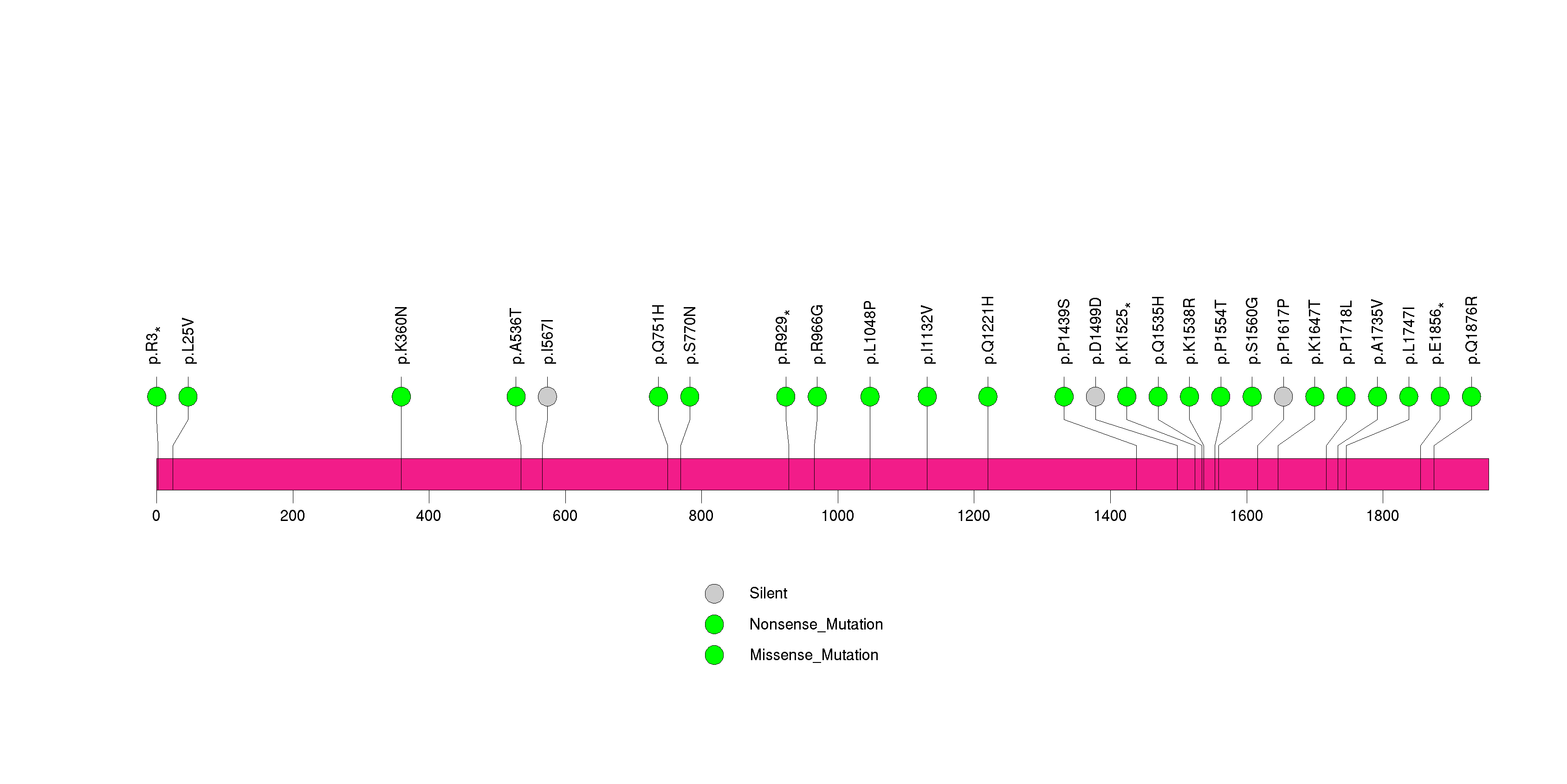
Figure S16. This figure depicts the distribution of mutations and mutation types across the SPRYD5 significant gene.
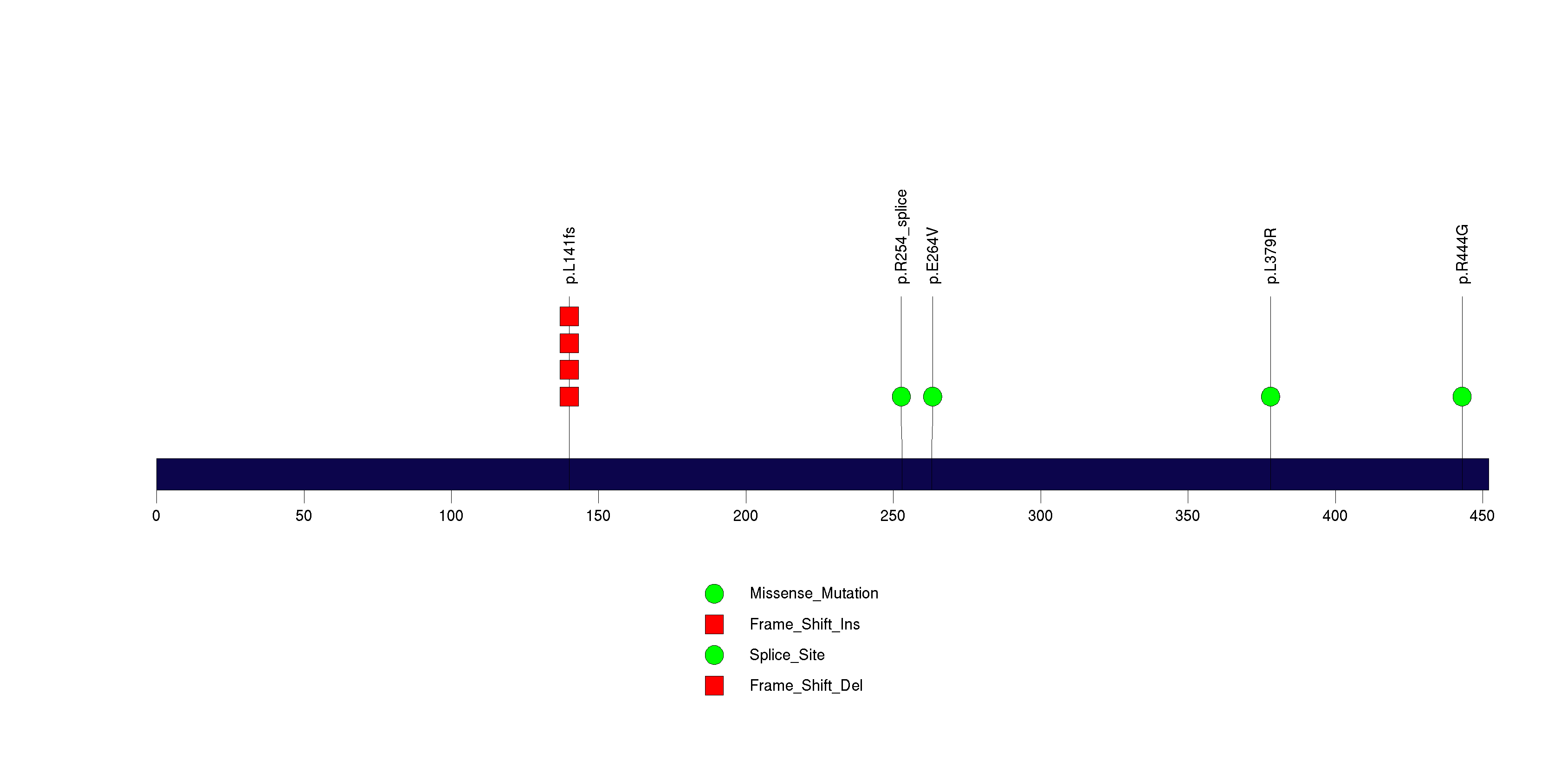
Figure S17. This figure depicts the distribution of mutations and mutation types across the TUSC3 significant gene.
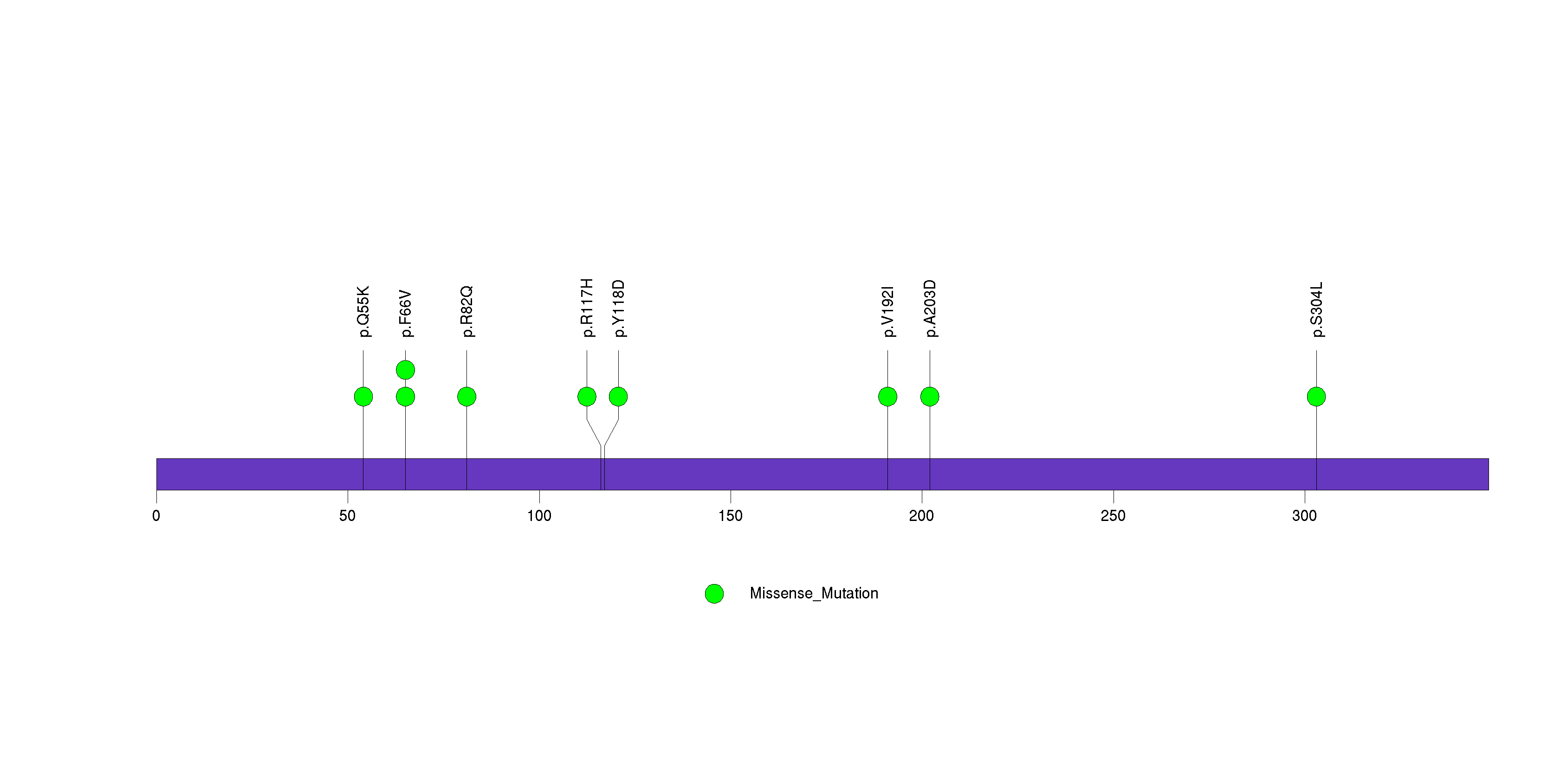
Figure S18. This figure depicts the distribution of mutations and mutation types across the FGF22 significant gene.
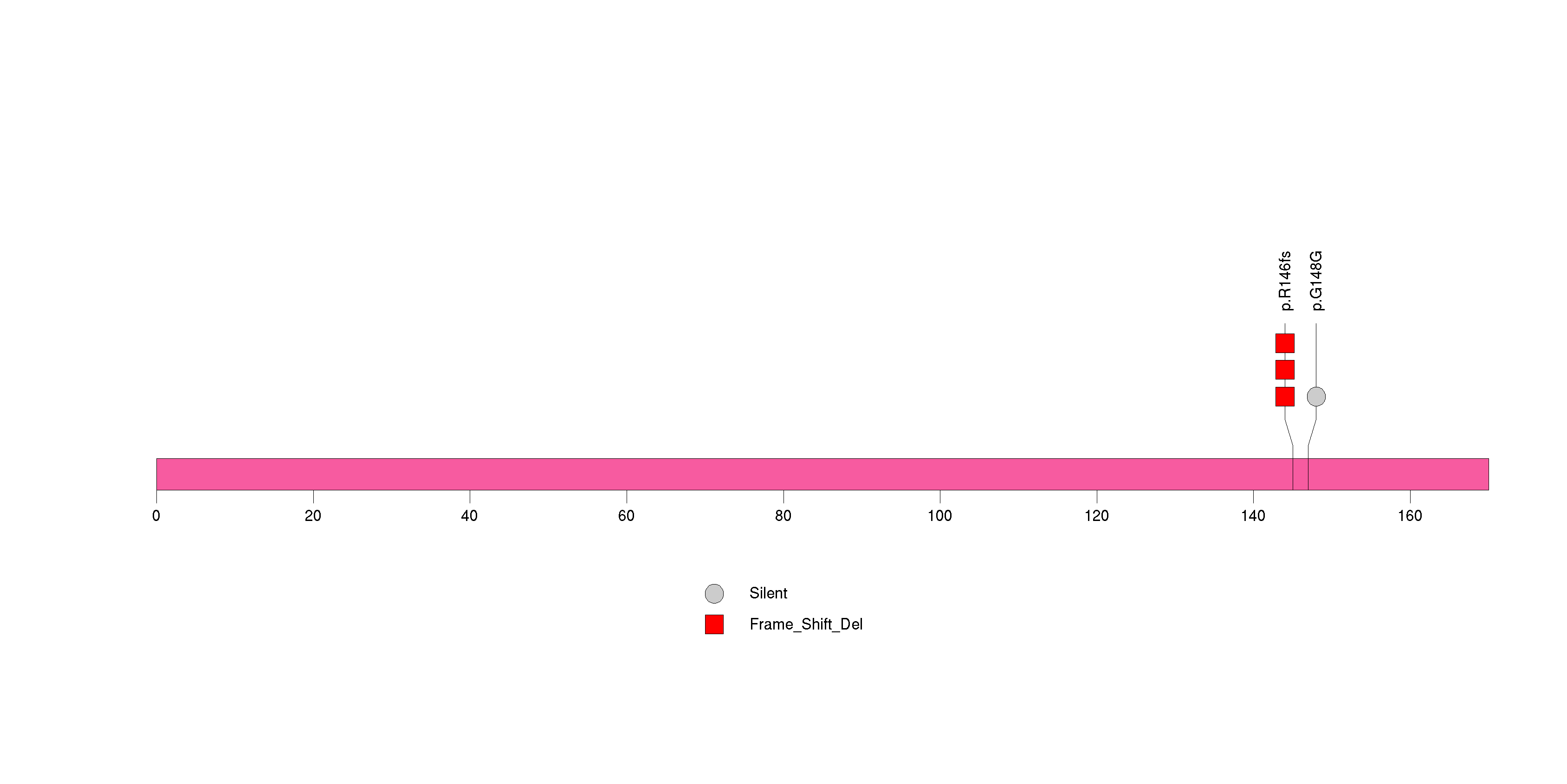
Figure S19. This figure depicts the distribution of mutations and mutation types across the C17orf63 significant gene.
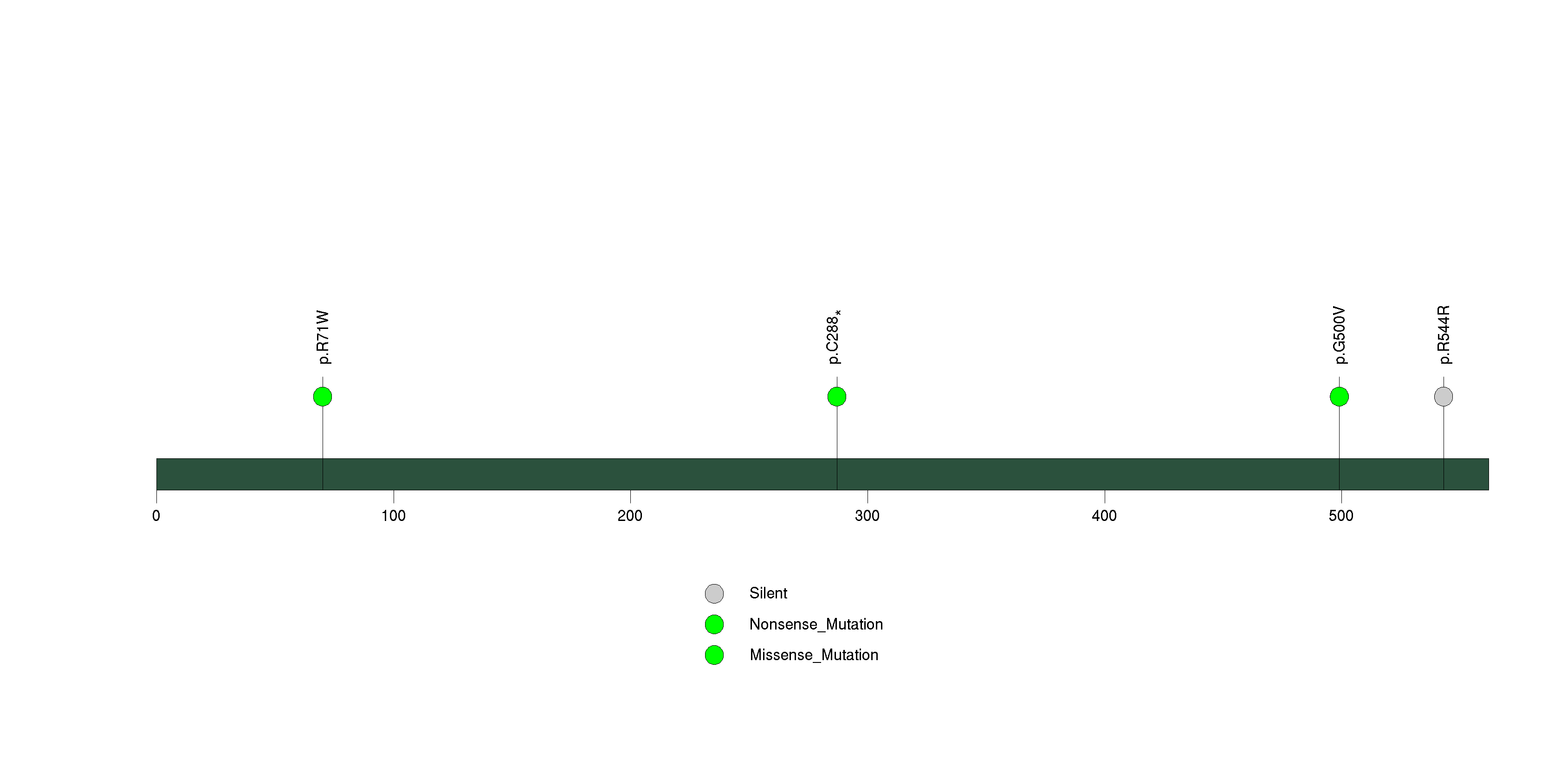
Figure S20. This figure depicts the distribution of mutations and mutation types across the SMAD4 significant gene.
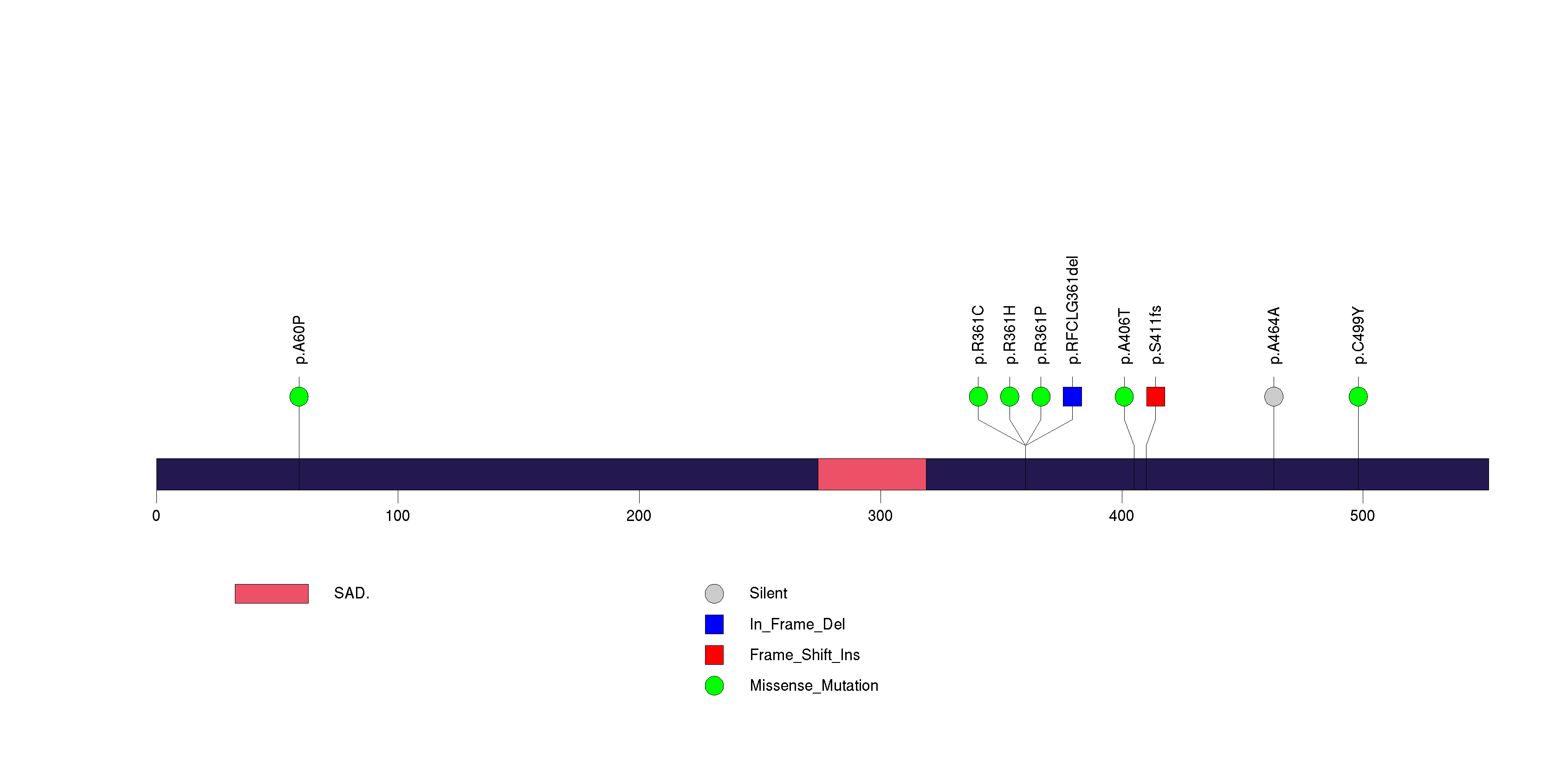
Figure S21. This figure depicts the distribution of mutations and mutation types across the POTEG significant gene.
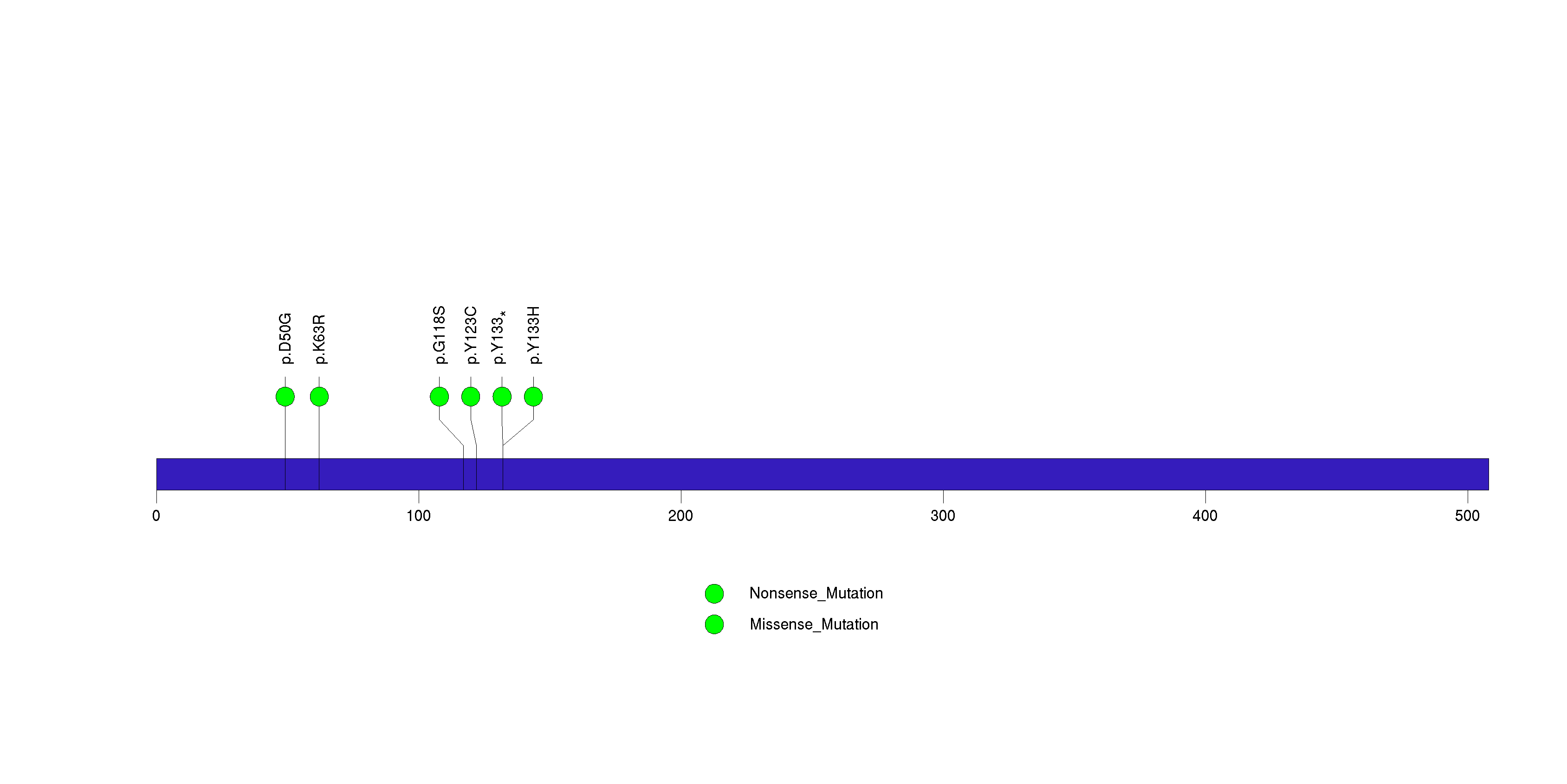
Figure S22. This figure depicts the distribution of mutations and mutation types across the RNF43 significant gene.
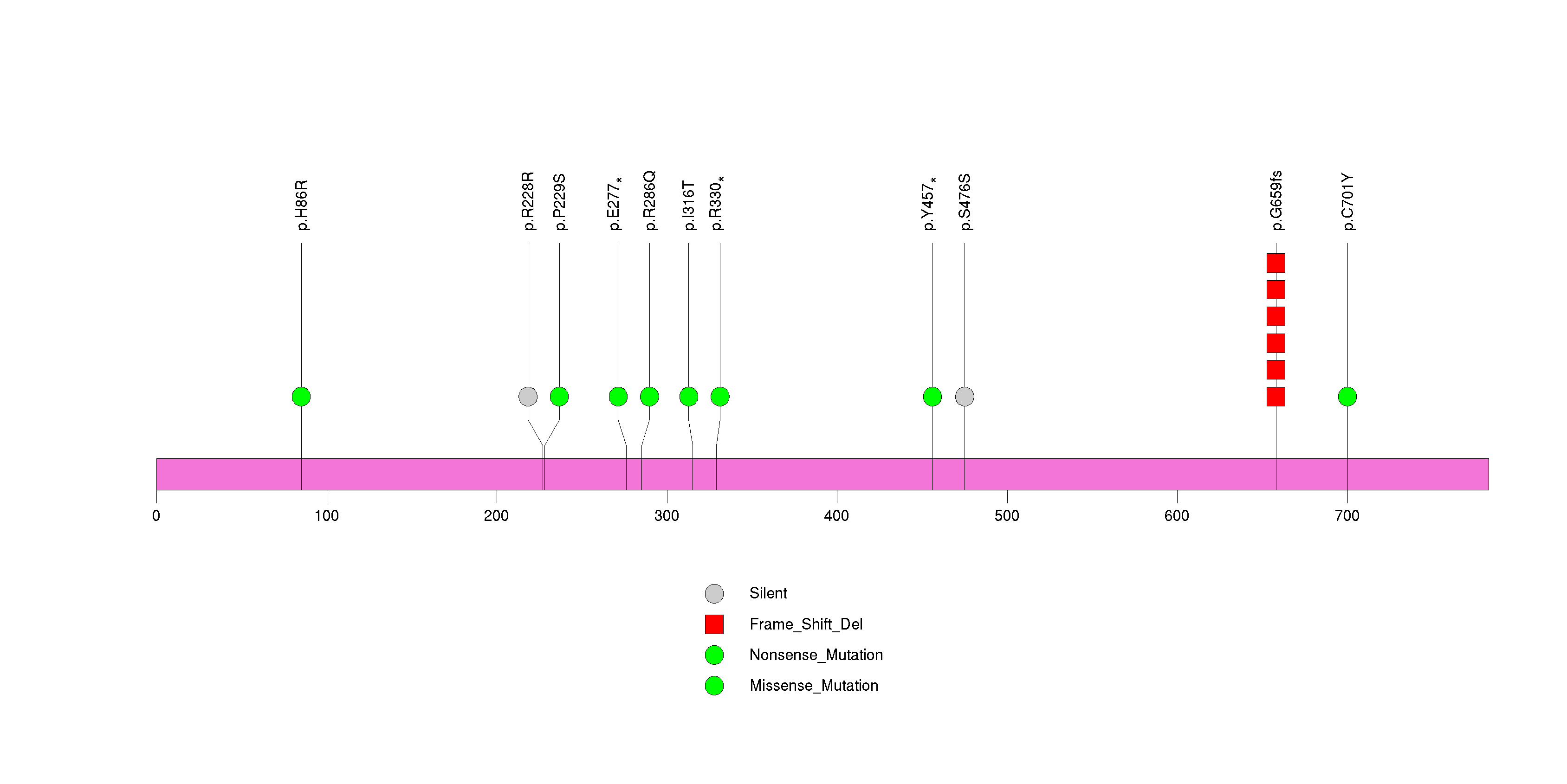
Figure S23. This figure depicts the distribution of mutations and mutation types across the WBSCR17 significant gene.
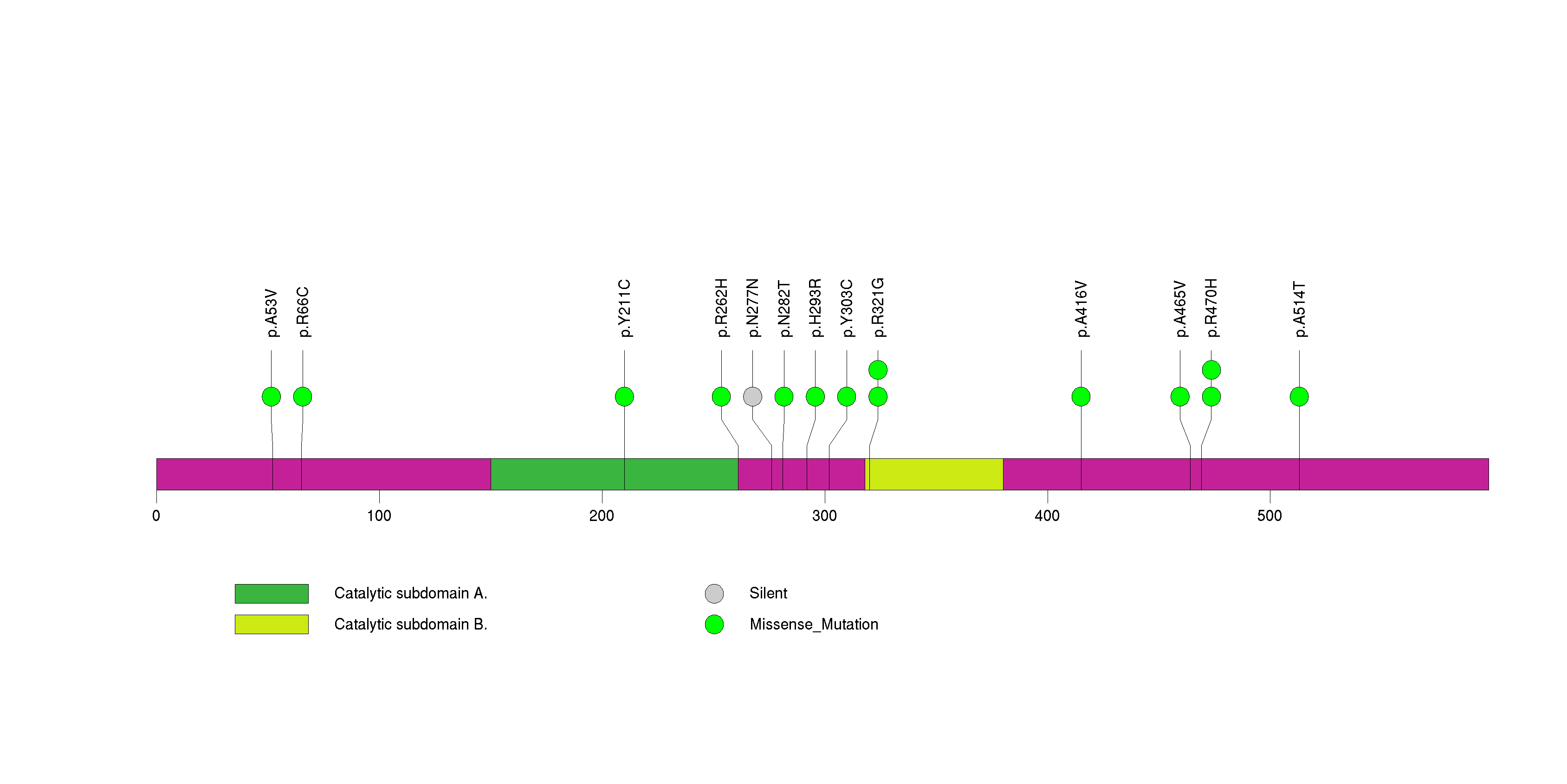
Figure S24. This figure depicts the distribution of mutations and mutation types across the PHF2 significant gene.
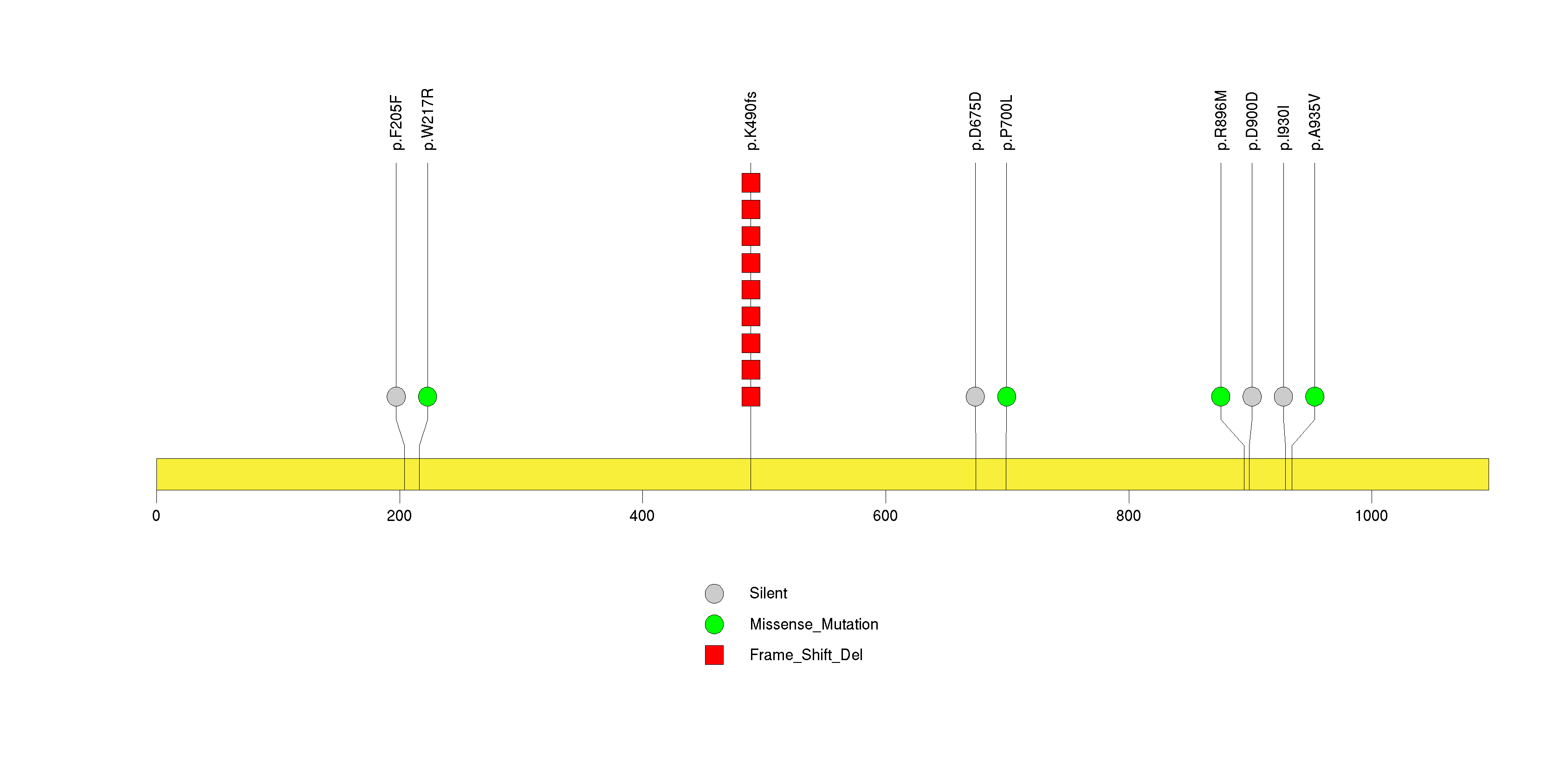
Figure S25. This figure depicts the distribution of mutations and mutation types across the TPTE significant gene.
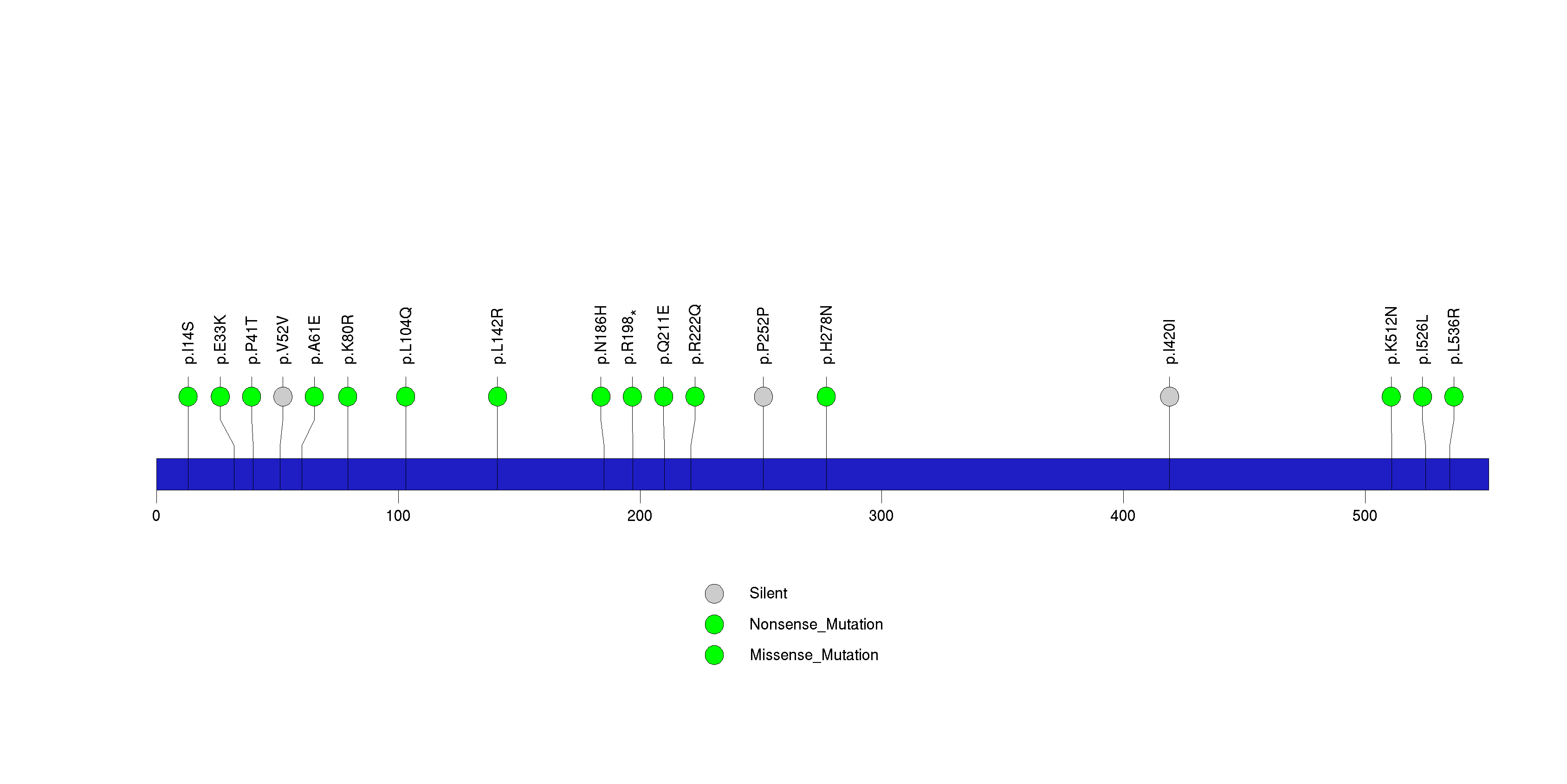
Figure S26. This figure depicts the distribution of mutations and mutation types across the CDH1 significant gene.
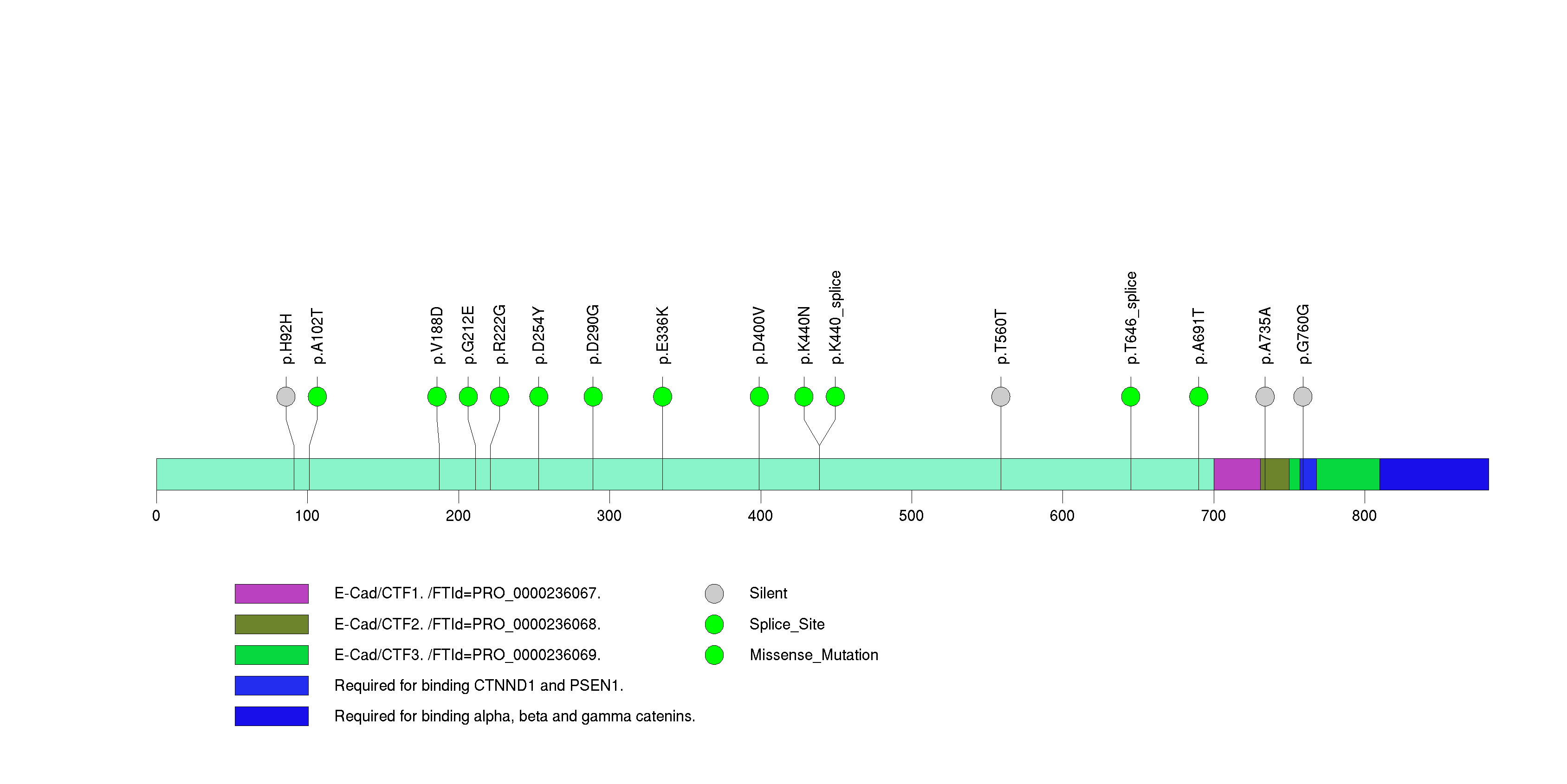
Figure S27. This figure depicts the distribution of mutations and mutation types across the CPS1 significant gene.
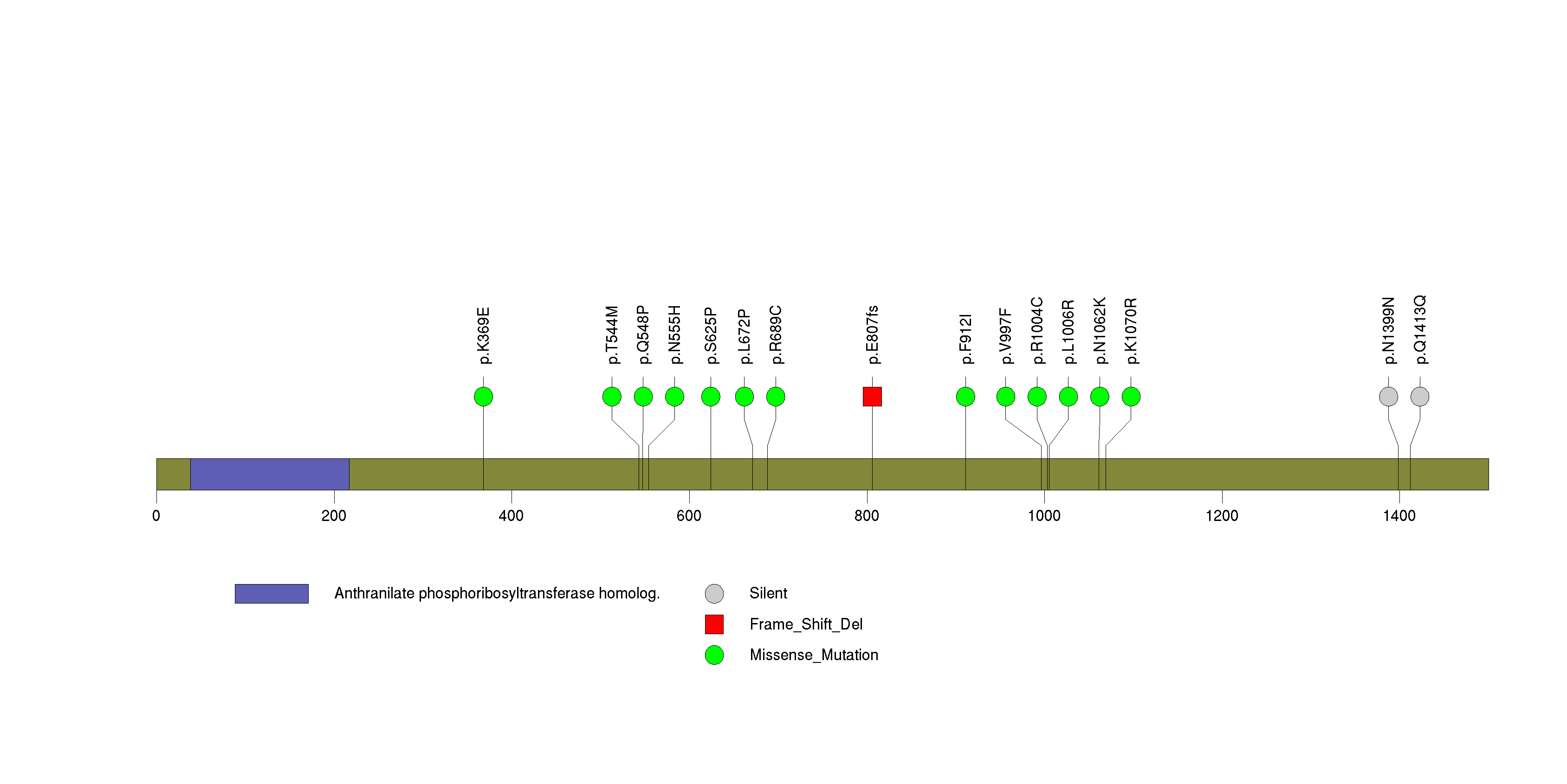
Figure S28. This figure depicts the distribution of mutations and mutation types across the INO80E significant gene.
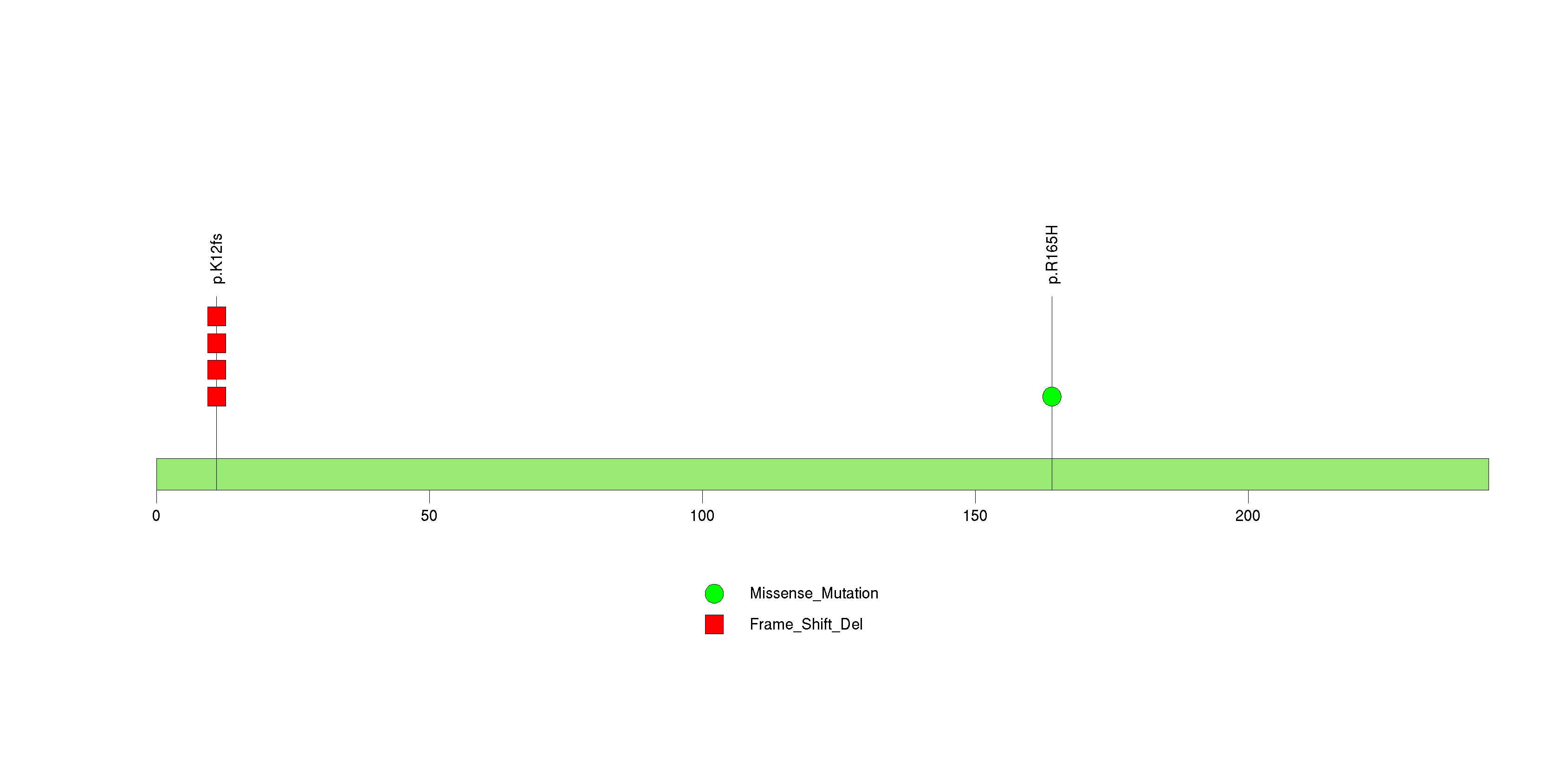
Figure S29. This figure depicts the distribution of mutations and mutation types across the ELF3 significant gene.
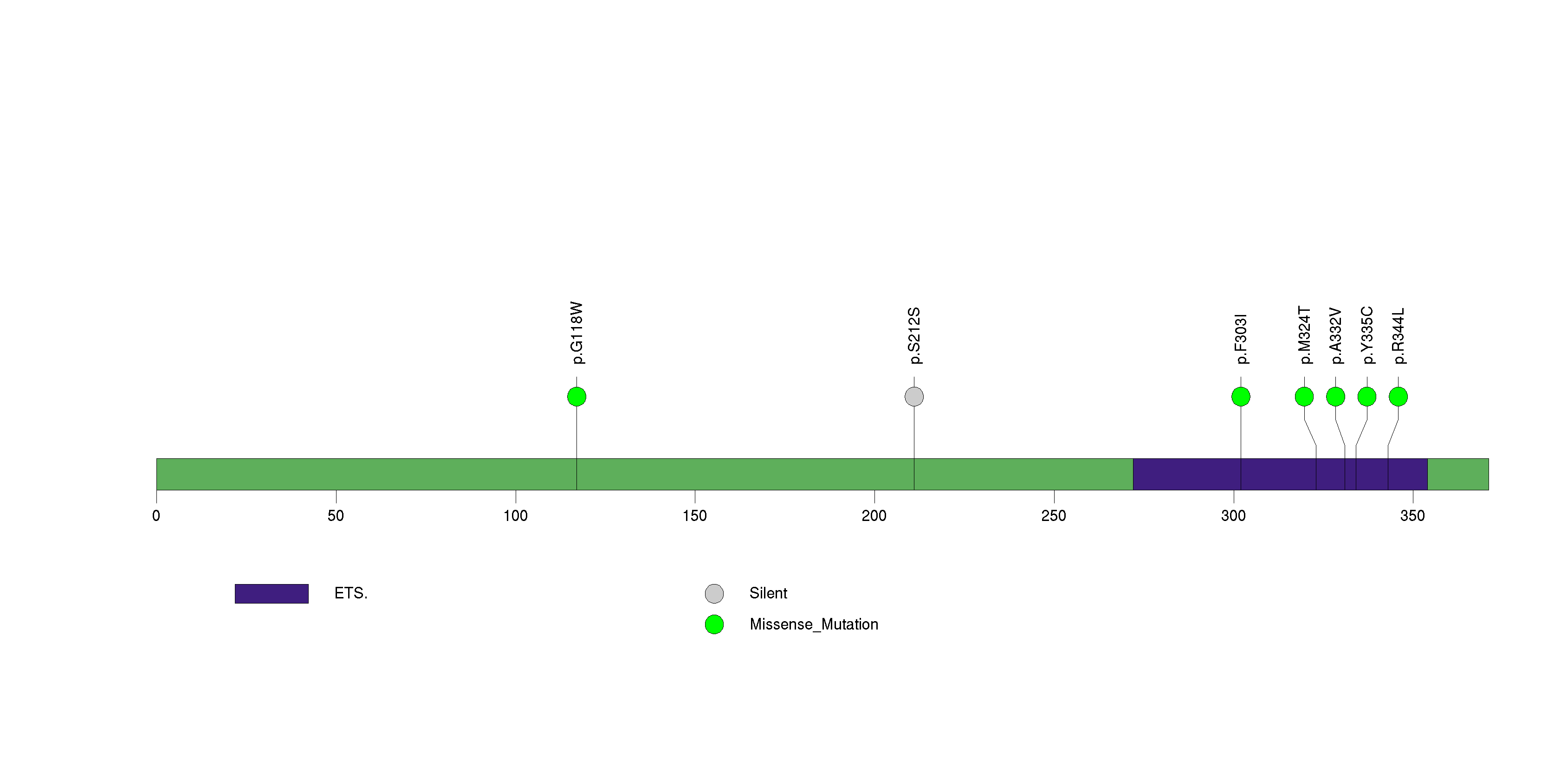
Figure S30. This figure depicts the distribution of mutations and mutation types across the PARK2 significant gene.
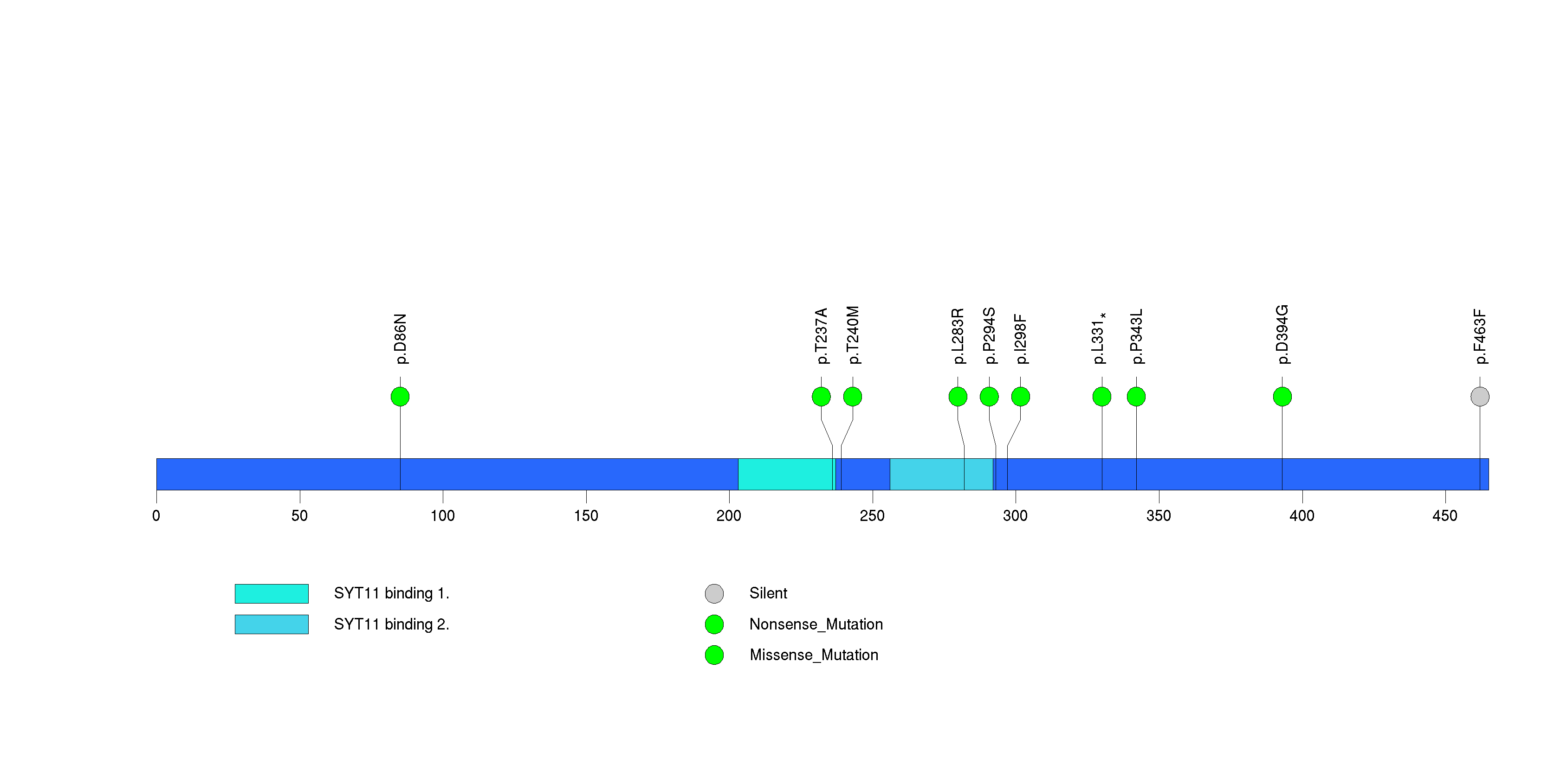
In this analysis, COSMIC is used as a filter to increase power by restricting the territory of each gene. Cosmic version: v48.
Table 4. Get Full Table Significantly mutated genes (COSMIC territory only). To access the database please go to: COSMIC. Number of significant genes found: 19. Number of genes displayed: 10
| rank | gene | description | n | cos | n_cos | N_cos | cos_ev | p | q |
|---|---|---|---|---|---|---|---|---|---|
| 1 | ACVR2A | activin A receptor, type IIA | 14 | 3 | 10 | 348 | 10 | 0 | 0 |
| 2 | KRAS | v-Ki-ras2 Kirsten rat sarcoma viral oncogene homolog | 14 | 52 | 13 | 6032 | 86315 | 0 | 0 |
| 3 | TP53 | tumor protein p53 | 56 | 356 | 52 | 41296 | 18767 | 0 | 0 |
| 4 | PIK3CA | phosphoinositide-3-kinase, catalytic, alpha polypeptide | 32 | 220 | 29 | 25520 | 10169 | 0 | 0 |
| 5 | SMAD4 | SMAD family member 4 | 8 | 159 | 7 | 18444 | 23 | 9.9e-09 | 9e-06 |
| 6 | ERBB3 | v-erb-b2 erythroblastic leukemia viral oncogene homolog 3 (avian) | 16 | 6 | 3 | 696 | 3 | 1.4e-07 | 0.00011 |
| 7 | PKHD1 | polycystic kidney and hepatic disease 1 (autosomal recessive) | 18 | 8 | 3 | 928 | 3 | 3.3e-07 | 0.00021 |
| 8 | FBXW7 | F-box and WD repeat domain containing 7 | 8 | 91 | 5 | 10556 | 278 | 4.5e-07 | 0.00025 |
| 9 | CDH1 | cadherin 1, type 1, E-cadherin (epithelial) | 12 | 185 | 6 | 21460 | 27 | 6.7e-07 | 0.00034 |
| 10 | ACIN1 | apoptotic chromatin condensation inducer 1 | 6 | 1 | 2 | 116 | 2 | 1.2e-06 | 0.00051 |
Note:
n - number of (nonsilent) mutations in this gene across the individual set.
cos = number of unique mutated sites in this gene in COSMIC
n_cos = overlap between n and cos.
N_cos = number of individuals times cos.
cos_ev = total evidence: number of reports in COSMIC for mutations seen in this gene.
p = p-value for seeing the observed amount of overlap in this gene)
q = q-value, False Discovery Rate (Benjamini-Hochberg procedure)
Table 5. Get Full Table Genes with Clustered Mutations
| num | gene | desc | n | mindist | nmuts0 | nmuts3 | nmuts12 | npairs0 | npairs3 | npairs12 |
|---|---|---|---|---|---|---|---|---|---|---|
| 8924 | PGM5 | phosphoglucomutase 5 | 19 | 0 | 92 | 92 | 120 | 92 | 92 | 120 |
| 1975 | CBWD1 | COBW domain containing 1 | 15 | 0 | 91 | 91 | 91 | 91 | 91 | 91 |
| 12381 | TP53 | tumor protein p53 | 56 | 0 | 54 | 98 | 176 | 54 | 98 | 176 |
| 9019 | PIK3CA | phosphoinositide-3-kinase, catalytic, alpha polypeptide | 32 | 0 | 38 | 71 | 83 | 38 | 71 | 83 |
| 12491 | TRIM48 | tripartite motif-containing 48 | 10 | 0 | 36 | 36 | 45 | 36 | 36 | 45 |
| 6359 | KRAS | v-Ki-ras2 Kirsten rat sarcoma viral oncogene homolog | 14 | 0 | 25 | 55 | 56 | 25 | 55 | 56 |
| 501 | ANAPC1 | anaphase promoting complex subunit 1 | 13 | 0 | 15 | 15 | 15 | 15 | 15 | 15 |
| 13203 | XPOT | exportin, tRNA (nuclear export receptor for tRNAs) | 6 | 0 | 15 | 15 | 15 | 15 | 15 | 15 |
| 10103 | RHOA | ras homolog gene family, member A | 8 | 0 | 10 | 11 | 16 | 10 | 11 | 16 |
| 4232 | FAT4 | FAT tumor suppressor homolog 4 (Drosophila) | 61 | 0 | 4 | 5 | 14 | 4 | 5 | 14 |
Note:
n - number of mutations in this gene in the individual set.
mindist - distance (in aa) between closest pair of mutations in this gene
npairs3 - how many pairs of mutations are within 3 aa of each other.
npairs12 - how many pairs of mutations are within 12 aa of each other.
Table 6. Get Full Table A Ranked List of Significantly Mutated Genesets. (Source: MSigDB GSEA Cannonical Pathway Set).Number of significant genesets found: 17. Number of genesets displayed: 10
| rank | geneset | description | genes | N_genes | mut_tally | N | n | npat | nsite | nsil | n1 | n2 | n3 | n4 | n5 | n6 | p_ns_s | p | q |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | RNAPATHWAY | dsRNA-activated protein kinase phosphorylates elF2a, which generally inhibits translation, and activates NF-kB to provoke inflammation. | CHUK, DNAJC3, EIF2S1, EIF2S2, MAP3K14, NFKB1, NFKBIA, PRKR, RELA, TP53 | 9 | DNAJC3(1), EIF2S1(1), EIF2S2(2), MAP3K14(2), NFKB1(5), RELA(1), TP53(56) | 1708094 | 68 | 57 | 53 | 4 | 21 | 14 | 1 | 12 | 19 | 1 | 0.000037 | 4e-15 | 8.5e-13 |
| 2 | PLK3PATHWAY | Active Plk3 phosphorylates CDC25c, blocking the G2/M transition, and phosphorylates p53 to induce apoptosis. | ATM, ATR, CDC25C, CHEK1, CHEK2, CNK, TP53, YWHAH | 7 | ATM(13), ATR(5), CDC25C(2), CHEK1(1), CHEK2(5), TP53(56), YWHAH(1) | 2781580 | 83 | 64 | 67 | 9 | 26 | 21 | 3 | 10 | 21 | 2 | 0.00084 | 4.4e-15 | 8.5e-13 |
| 3 | TERTPATHWAY | hTERC, the RNA subunit of telomerase, and hTERT, the catalytic protein subunit, are required for telomerase activity and are overexpressed in many cancers. | HDAC1, MAX, MYC, SP1, SP3, TP53, WT1, ZNF42 | 7 | HDAC1(2), MAX(1), SP1(3), SP3(3), TP53(56), WT1(1) | 1216894 | 66 | 57 | 51 | 7 | 21 | 16 | 1 | 8 | 19 | 1 | 0.000092 | 5.8e-15 | 8.5e-13 |
| 4 | P53HYPOXIAPATHWAY | Hypoxia induces p53 accumulation and consequent apoptosis with p53-mediated cell cycle arrest, which is present under conditions of DNA damage. | ABCB1, AKT1, ATM, BAX, CDKN1A, CPB2, CSNK1A1, CSNK1D, FHL2, GADD45A, HIC1, HIF1A, HSPA1A, HSPCA, IGFBP3, MAPK8, MDM2, NFKBIB, NQO1, TP53 | 19 | ABCB1(8), AKT1(2), ATM(13), CDKN1A(1), CPB2(3), FHL2(2), HIC1(1), HIF1A(2), HSPA1A(1), IGFBP3(4), MAPK8(3), MDM2(3), NFKBIB(4), NQO1(2), TP53(56) | 3603665 | 105 | 71 | 89 | 14 | 34 | 26 | 3 | 15 | 25 | 2 | 4e-05 | 6.7e-15 | 8.5e-13 |
| 5 | SA_G1_AND_S_PHASES | Cdk2, 4, and 6 bind cyclin D in G1, while cdk2/cyclin E promotes the G1/S transition. | ARF1, ARF3, CCND1, CDK2, CDK4, CDKN1A, CDKN1B, CDKN2A, CFL1, E2F1, E2F2, MDM2, NXT1, PRB1, TP53 | 15 | ARF1(2), CCND1(1), CDK2(2), CDKN1A(1), CDKN2A(3), CFL1(1), E2F2(2), MDM2(3), NXT1(1), PRB1(2), TP53(56) | 1409760 | 74 | 61 | 59 | 8 | 24 | 19 | 2 | 8 | 20 | 1 | 0.000094 | 6.9e-15 | 8.5e-13 |
| 6 | CHEMICALPATHWAY | DNA damage promotes Bid cleavage, which stimulates mitochondrial cytochrome c release and consequent caspase activation, resulting in apoptosis. | ADPRT, AKT1, APAF1, ATM, BAD, BAX, BCL2, BCL2L1, BID, CASP3, CASP6, CASP7, CASP9, CYCS, EIF2S1, PRKCA, PRKCB1, PTK2, PXN, STAT1, TLN1, TP53 | 20 | AKT1(2), APAF1(2), ATM(13), BAD(1), BCL2(1), BID(1), CASP3(1), CASP6(1), CASP7(2), CASP9(1), EIF2S1(1), PTK2(7), PXN(1), STAT1(4), TLN1(11), TP53(56) | 4749058 | 105 | 64 | 89 | 14 | 37 | 29 | 5 | 11 | 21 | 2 | 0.000046 | 5.9e-14 | 6.1e-12 |
| 7 | TIDPATHWAY | On ligand binding, interferon gamma receptors stimulate JAK2 kinase to phosphorylate STAT transcription factors, which promote expression of interferon responsive genes. | DNAJA3, HSPA1A, IFNG, IFNGR1, IFNGR2, IKBKB, JAK2, LIN7A, NFKB1, NFKBIA, RB1, RELA, TIP-1, TNF, TNFRSF1A, TNFRSF1B, TP53, USH1C, WT1 | 18 | DNAJA3(1), HSPA1A(1), IFNG(2), IFNGR1(2), IFNGR2(1), IKBKB(3), JAK2(8), LIN7A(4), NFKB1(5), RB1(7), RELA(1), TNF(1), TNFRSF1A(2), TNFRSF1B(1), TP53(56), USH1C(1), WT1(1) | 3158351 | 97 | 64 | 80 | 14 | 26 | 24 | 2 | 21 | 23 | 1 | 0.00037 | 1.5e-13 | 1.3e-11 |
| 8 | RBPATHWAY | The ATM protein kinase recognizes DNA damage and blocks cell cycle progression by phosphorylating chk1 and p53, which normally inhibits Rb to allow G1/S transitions. | ATM, CDC2, CDC25A, CDC25B, CDC25C, CDK2, CDK4, CHEK1, MYT1, RB1, TP53, WEE1, YWHAH | 12 | ATM(13), CDC25A(2), CDC25B(2), CDC25C(2), CDK2(2), CHEK1(1), MYT1(9), RB1(7), TP53(56), YWHAH(1) | 3061869 | 95 | 64 | 78 | 11 | 29 | 27 | 3 | 12 | 22 | 2 | 0.00011 | 2e-13 | 1.5e-11 |
| 9 | ARFPATHWAY | Cyclin-dependent kinase inhibitor 2A is a tumor suppressor that induces G1 arrest and can activate the p53 pathway, leading to G2/M arrest. | ABL1, CDKN2A, E2F1, MDM2, MYC, PIK3CA, PIK3R1, POLR1A, POLR1B, POLR1C, POLR1D, RAC1, RB1, TBX2, TP53, TWIST1 | 16 | ABL1(2), CDKN2A(3), MDM2(3), PIK3CA(32), PIK3R1(5), POLR1A(5), POLR1C(2), POLR1D(1), RB1(7), TBX2(3), TP53(56) | 3505057 | 119 | 74 | 90 | 21 | 31 | 42 | 5 | 15 | 25 | 1 | 0.00024 | 8e-10 | 5.5e-08 |
| 10 | P53PATHWAY | p53 induces cell cycle arrest or apoptosis under conditions of DNA damage. | APAF1, ATM, BAX, BCL2, CCND1, CCNE1, CDK2, CDK4, CDKN1A, E2F1, GADD45A, MDM2, PCNA, RB1, TIMP3, TP53 | 16 | APAF1(2), ATM(13), BCL2(1), CCND1(1), CCNE1(3), CDK2(2), CDKN1A(1), MDM2(3), PCNA(2), RB1(7), TIMP3(2), TP53(56) | 3148338 | 93 | 63 | 76 | 14 | 26 | 28 | 3 | 12 | 22 | 2 | 0.001 | 1.6e-08 | 1e-06 |
Table 7. Get Full Table A Ranked List of Significantly Mutated Genesets (Excluding Significantly Mutated Genes). Number of significant genesets found: 0. Number of genesets displayed: 10
| rank | geneset | description | genes | N_genes | mut_tally | N | n | npat | nsite | nsil | n1 | n2 | n3 | n4 | n5 | n6 | p_ns_s | p | q |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | HSA00472_D_ARGININE_AND_D_ORNITHINE_METABOLISM | Genes involved in D-arginine and D-ornithine metabolism | DAO | 1 | DAO(5) | 125186 | 5 | 5 | 5 | 1 | 1 | 0 | 1 | 1 | 2 | 0 | 0.55 | 0.0089 | 1 |
| 2 | SLRPPATHWAY | Small leucine-rich proteoglycans (SLRPs) interact with and reorganize collagen fibers in the extracellular matrix. | BGN, DCN, DSPG3, FMOD, KERA, LUM | 5 | BGN(2), DCN(2), FMOD(9), KERA(1), LUM(2) | 629673 | 16 | 14 | 16 | 2 | 8 | 3 | 0 | 5 | 0 | 0 | 0.082 | 0.032 | 1 |
| 3 | ERBB4PATHWAY | ErbB4 (aka HER4) is a receptor tyrosine kinase that binds neuregulins as well as members of the EGF family, which also target EGF receptors. | ADAM17, ERBB4, NRG2, NRG3, PRKCA, PRKCB1, PSEN1 | 6 | ADAM17(3), ERBB4(16), NRG2(4), NRG3(9), PSEN1(1) | 1555655 | 33 | 24 | 33 | 5 | 7 | 13 | 4 | 5 | 4 | 0 | 0.023 | 0.056 | 1 |
| 4 | TCRMOLECULE | T Cell Receptor and CD3 Complex | CD3D, CD3E, CD3G, CD3Z, TRA@, TRB@ | 3 | CD3E(2), CD3G(2) | 196753 | 4 | 4 | 3 | 1 | 0 | 1 | 1 | 0 | 2 | 0 | 0.82 | 0.1 | 1 |
| 5 | VOBESITYPATHWAY | The adipose tissue of obese individuals overexpresses a key glucocorticoid-metabolizing enzyme, activating inactive circulating corticosteroids and inducing insulin resistance. | APM1, HSD11B1, LPL, NR3C1, PPARG, RETN, RXRA, TNF | 7 | LPL(2), NR3C1(4), PPARG(1), RXRA(2), TNF(1) | 999771 | 10 | 10 | 10 | 1 | 2 | 1 | 1 | 5 | 1 | 0 | 0.21 | 0.21 | 1 |
| 6 | EOSINOPHILSPATHWAY | Recruitment of eosinophils in the inflammatory response observed in asthma occurs via the chemoattractant eotaxin binding to the CCR3 receptor. | CCL11, CCL5, CCR3, CSF2, HLA-DRA, HLA-DRB1, IL3, IL5 | 8 | CCL11(1), CCL5(1), CCR3(4), HLA-DRA(3), HLA-DRB1(1), IL3(1) | 526404 | 11 | 10 | 11 | 3 | 4 | 4 | 0 | 2 | 1 | 0 | 0.35 | 0.23 | 1 |
| 7 | GCRPATHWAY | Corticosteroids activate the glucocorticoid receptor (GR), which inhibits NF-kB and activates Annexin-1, thus inhibiting the inflammatory response. | ADRB2, AKT1, ANXA1, CALM1, CALM2, CALM3, CRN, GNAS, GNB1, GNGT1, HSPCA, NFKB1, NOS3, NPPA, NR3C1, PIK3CA, PIK3R1, RELA, SYT1 | 16 | ADRB2(3), AKT1(2), ANXA1(3), CALM1(1), CALM2(2), CALM3(1), GNAS(11), GNGT1(3), NFKB1(5), NOS3(3), NPPA(1), NR3C1(4), PIK3R1(5), RELA(1) | 2722623 | 45 | 28 | 45 | 7 | 13 | 12 | 0 | 11 | 9 | 0 | 0.041 | 0.26 | 1 |
| 8 | TOB1PATHWAY | TGF-beta signaling activates SMADs, which interact with intracellular Tob to maintain unstimulated T cells by repressing IL-2 expression. | CD28, CD3D, CD3E, CD3G, CD3Z, IFNG, IL2, IL2RA, IL4, MADH3, MADH4, TGFB1, TGFB2, TGFB3, TGFBR1, TGFBR2, TGFBR3, TOB1, TOB2, TRA@, TRB@ | 16 | CD3E(2), CD3G(2), IFNG(2), IL2RA(1), TGFB1(3), TGFB2(6), TGFB3(3), TGFBR1(2), TGFBR2(6), TGFBR3(2), TOB1(1), TOB2(4) | 1836086 | 34 | 24 | 33 | 6 | 6 | 11 | 3 | 10 | 4 | 0 | 0.11 | 0.3 | 1 |
| 9 | FLUMAZENILPATHWAY | Flumazenil is a benzodiazepine receptor antagonist that may induce protective preconditioning in ischemic cardiomyocytes. | GABRA1, GABRA2, GABRA3, GABRA4, GABRA5, GABRA6, GPX1, PRKCE, SOD1 | 9 | GABRA1(5), GABRA2(5), GABRA3(5), GABRA4(4), GABRA5(4), GABRA6(5), PRKCE(5) | 1366369 | 33 | 21 | 33 | 9 | 11 | 7 | 5 | 9 | 1 | 0 | 0.2 | 0.31 | 1 |
| 10 | PEPIPATHWAY | Proepithelin (PEPI) induces epithelial cells to secrete IL-8, which promotes elastase secretion by neutrophils. | ELA1, ELA2, ELA2A, ELA2B, ELA3B, GRN, IL8, SLPI | 3 | GRN(3), IL8(1), SLPI(1) | 296007 | 5 | 4 | 5 | 1 | 2 | 2 | 0 | 1 | 0 | 0 | 0.39 | 0.38 | 1 |
In brief, we tabulate the number of mutations and the number of covered bases for each gene. The counts are broken down by mutation context category: four context categories that are discovered by MutSig, and one for indel and 'null' mutations, which include indels, nonsense mutations, splice-site mutations, and non-stop (read-through) mutations. For each gene, we calculate the probability of seeing the observed constellation of mutations, i.e. the product P1 x P2 x ... x Pm, or a more extreme one, given the background mutation rates calculated across the dataset. [1]
This is an experimental feature. The full results of the analysis summarized in this report can be downloaded from the TCGA Data Coordination Center.